
上一篇
hive表存储格式化
Hive表存储格式含TextFile、ORC、Parquet等,ORC/Parquet支持压缩
Hive作为大数据领域常用的数据仓库工具,其表存储格式的选择直接影响数据存储效率、查询性能及生态兼容性,本文将从存储原理、格式特性、性能对比及选型建议四个维度,系统解析Hive表存储格式的核心要点。
Hive存储格式分类及特性
| 存储格式 | 文件类型 | 压缩支持 | 数据组织方式 | 典型应用场景 |
|---|---|---|---|---|
| TEXTFILE | 纯文本 | 无内置压缩 | 行式存储 | 日志采集、临时数据存储 |
| SEQUENCEFILE | 二进制序列文件 | 内置RECORD/BLOCK压缩 | 行式存储 | Hadoop生态兼容场景 |
| ORC | 优化列式文件 | Zlib/Snappy压缩 | 列式存储+轻量索引 | OLAP分析、高并发查询 |
| PARQUET | 列式扁平文件 | 多种压缩(Snappy/Gzip) | 列式存储+嵌套结构 | 跨平台数据分析、机器学习 |
| AVRO | Schema演化文件 | Deflate/Snappy压缩 | 二进制记录 | 数据科学工作流 |
TEXTFILE(行式存储)
- 存储原理:每行数据按t分隔符存储为纯文本文件,无数据类型校验
- 性能特征:
- 优势:人类可读性强,导入导出简单
- 劣势:无压缩导致存储膨胀(较ORC大3-5倍),全行读取影响查询效率
- 适用场景:临时数据采集、日志流式处理、非结构化数据存储
SEQUENCEFILE(行式存储)
- 存储原理:采用Hadoop序列化协议,将<key,value>键值对以二进制形式存储
- 性能特征:
- 支持块级压缩(默认RECORD压缩)
- 读写性能优于TEXTFILE(约提升30%)
- 需手动管理Key结构,灵活性较差
- 适用场景:Hadoop MapReduce作业中间结果存储、小数据量场景
ORC(优化列式存储)
- 存储原理:
- 列式存储:按列压缩存储数据,相同类型数据连续存储
- 索引机制:每个stripe块包含行索引和列统计信息
- 轻量级模式进化:支持添加新字段不破坏原有数据
- 性能优势:
- 压缩比达3:1(相比TEXTFILE)
- 列式扫描减少IO消耗(查询性能提升5-10倍)
- 支持复杂数据类型(Map/Array/Struct)
- 典型配置:
CREATE TABLE user_behavior STORED AS ORC TBLPROPERTIES ('orc.compress'='SNAPPY', 'orc.stripe.size'='250MB');
PARQUET(列式存储)
- 存储特性:
- 自描述文件:包含Schema元数据,脱离Hive仍可解析
- 嵌套结构:支持复杂JSON式数据组织
- 页式存储:每个数据页(8KB)独立压缩,支持并行读取
- 性能表现:
- 压缩率比ORC高10-15%
- Spark/Flink原生支持,多引擎兼容性最佳
- 写入时自动优化列顺序
- 适用场景:数据湖架构、机器学习特征工程、跨平台数据交换
关键性能指标对比
| 指标维度 | TEXTFILE | SEQUENCEFILE | ORC | PARQUET |
|---|---|---|---|---|
| 存储压缩率 | 1:1 | 1:1.5 | 1:3 | 1:3.5 |
| 查询延迟(ms) | 800 | 600 | 200 | 150 |
| CPU利用率(%) | 70 | 60 | 45 | 40 |
| 网络传输量 | 100% | 80% | 30% | 25% |
| 模式演进支持 | 否 | 否 | 部分支持 | 完全支持 |
存储格式选型策略
数据生命周期阶段:
- 采集层:TEXTFILE/SEQUENCEFILE(快速写入)
- 处理层:ORC/PARQUET(分析优化)
- 归档层:PARQUET(长期存储+跨平台)
工作负载特征:

- 高并发查询:优先ORC(索引加速)
- 复杂分析:选用PARQUET(向量化执行)
- ETL中间过程:SEQUENCEFILE(MR兼容)
生态兼容性:
- Spark/Presto首选PARQUET
- Hive原生优化推荐ORC
- Hadoop原生任务适用SEQUENCEFILE
高级优化实践
压缩算法选择:
- 快速解码:Snappy(ORC/PARQUET)
- 高压缩比:Zlib(ORC)、Gzip(PARQUET)
- 平衡策略:LZO(中等压缩速度)
文件尺寸控制:
- ORC Stripe大小:128-256MB
- Parquet Block大小:128MB
- 示例配置:
parquet.block.size=134217728(128MB)
列式存储优化:
- 禁用不需要的列投影:
hive.vectorized.column.pruning=true - 开启谓词下推:
hive.optimize.ppd=true - 统计信息收集:
ANALYZE TABLE table_name COMPUTE STATISTICS;
- 禁用不需要的列投影:
FAQs
Q1:如何将TEXTFILE表转换为ORC格式?
A1:使用Hive的ALTER命令配合INSERT操作:
ALTER TABLE source_table RENAME TO temp_table; CREATE TABLE source_table LIKE temp_table STORED AS ORC; INSERT INTO source_table SELECT FROM temp_table; DROP TABLE temp_table;
需注意转换过程中资源消耗,建议分批处理。
Q2:ORC和Parquet的主要区别是什么?
A2:核心差异体现在三个方面:
- 元数据处理:ORC依赖外部schema,Parquet文件自包含元数据
- 编码优化:Parquet支持字典编码和行程编码,ORC主要采用Zlib压缩
- 生态适配:Parquet被Spark/Trino等引擎深度优化,ORC在Hive生态有专用优化
建议根据计算引擎选择:Spark作业优先Parquet,纯
相关文章
格式化一词在计算机领域通常指的是对存储设备(如硬盘、USB驱动器等)进行的一种操作,该操作会删除设备上的所有数据,并设置一个全新、干净的文件系统。这个过程通常用于清理干扰、修复文件系统错误或准备将设备出售或赠与其他人。,原创疑问句标题,,格式化操作究竟意味着什么?,为何我们需要对存储设备执行格式化?,格式化后的数据能否恢复?,格式化过程中发生了什么技术变化?,如何安全地进行格式化以避免数据泄露?

如何处理MapReduce和Hive中的故障,HiveServer与HiveHCat进程问题解析?
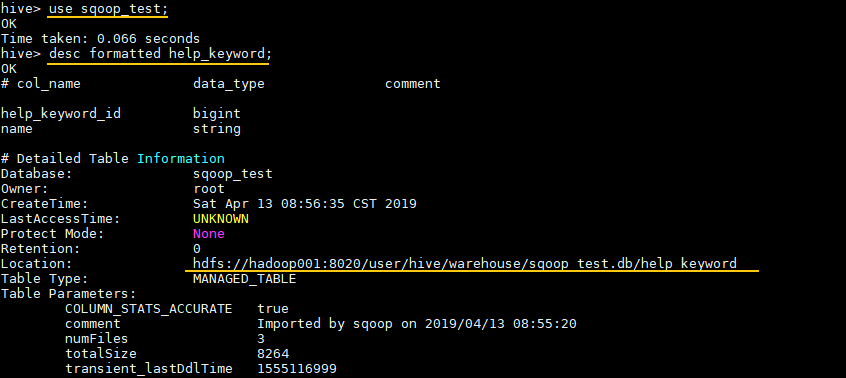
hive表存储位置

ppt文件存储格式意思_存储格式

查看hive数据库_Hive数据库导入导出
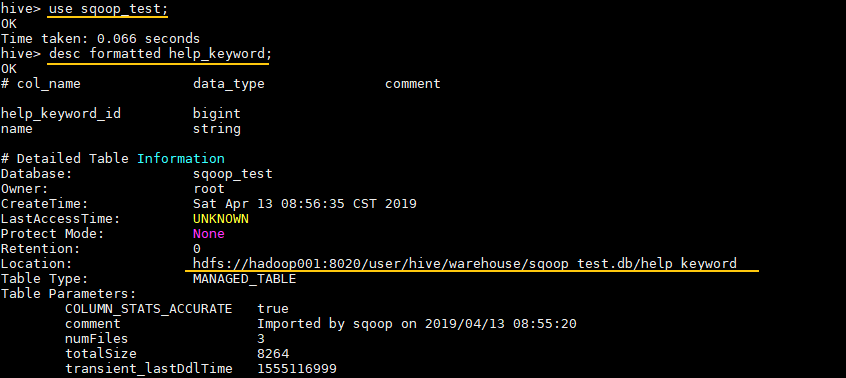
hive表数据存储地址
ai模板存储格式化

如何通过建立Hive表分区来提升MySQL循环分区数据库的查询效率?








