上一篇
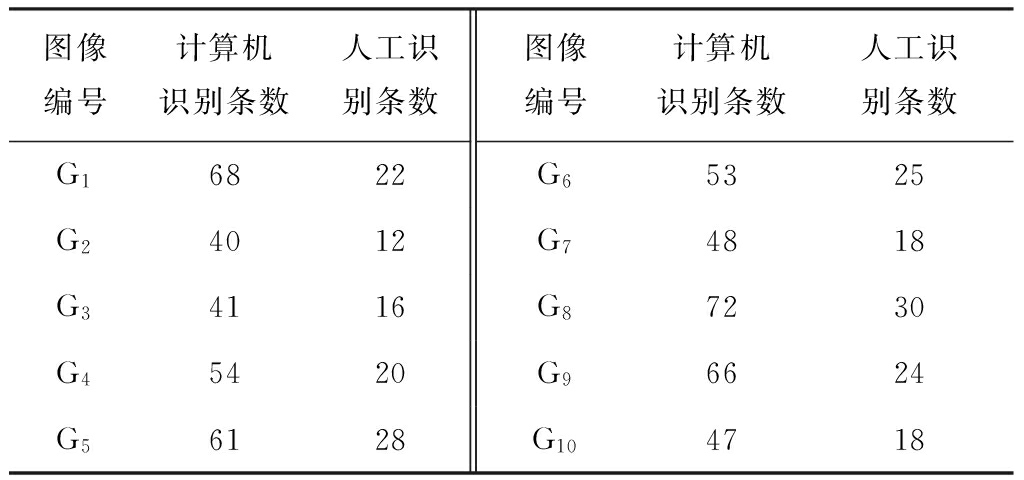
安卓图像识别图片位置
安卓图像识别通过ML Kit或TensorFlow Lite加载模型,输入图片后解析特征点,返回目标物体边界框坐标及置信度,实现位置定位
图像获取与预处理
图像来源
- 摄像头实时采集:通过
CameraX或Camera2API 获取实时图像流,适合动态场景(如AR应用)。 - 本地相册读取:通过
MediaStore或第三方库(如Glide)加载已存储的图片,适合静态分析。
预处理操作
| 步骤 | 作用 |
|---|---|
| 尺寸统一化 | 将图像缩放到模型要求的输入尺寸(如224x224或300x300)。 |
| 归一化 | 将像素值从[0,255]映射到[0,1]或标准化为均值方差。 |
| 色彩空间转换 | 部分模型需将RGB转换为HSV或YUV(如目标检测模型)。 |
| 数据增强(可选) | 对实时场景可跳过;离线分析可添加旋转/翻转增强数据多样性。 |
模型选择与部署
主流模型对比
| 模型名称 | 特点 | 适用场景 |
|---|---|---|
| SSD (Single Shot) | 速度快,平衡精度与性能 | 移动端实时检测 |
| YOLO | 极致速度,适合低算力设备 | 普通物体快速定位 |
| Faster R-CNN | 精度高,但推理速度较慢 | 高精度需求场景 |
| MobileNet-SSD | 轻量级模型,专为移动设备优化 | 资源受限的安卓设备 |
模型部署方式
- TensorFlow Lite:将模型转换为
.tflite格式,支持量化压缩。 - ONNX Runtime:跨平台推理框架,兼容PyTorch/MXNet等模型。
- OpenCV DNN模块:直接加载Caffe/TensorFlow模型,适合简单集成。
定位算法核心流程
目标检测原理
- 锚框机制:预设不同宽高比的框,匹配图像中的目标。
- 区域建议网络(RPN):生成候选区域(如Faster R-CNN)。
- 回归与分类:输出目标边界框坐标(
x,y,w,h)和类别概率。
坐标转换逻辑
| 模型输出坐标 | 实际像素坐标转换公式 |
|---|---|
| 归一化坐标(0~1) | x_pixel = x_norm image_width |
| 相对中心坐标 | x_pixel = (x_center width) (w_box / 2) |
后处理优化
- 非极大值抑制(NMS):过滤重叠框,保留最高置信度的框。
- 阈值筛选:设置置信度阈值(如0.5)过滤低置信结果。
结果可视化与交互
绘制边界框
// 示例:使用Canvas绘制矩形框
canvas.drawRect(
left, top, right, bottom,
Paint().apply { color = Color.RED; strokeWidth = 5f }
)标注信息叠加
- 类别标签:在框左上角绘制文字(如
TensorFlow Lite)。 - 置信度显示:可选显示概率值(如
98%)。
性能优化策略
| 优化方向 | 具体措施 |
|---|---|
| 模型量化 | 将浮点模型转为INT8量化模型,减少计算量。 |
| 多线程推理 | 使用AsyncTask或协程分离图像采集与推理任务。 |
| 硬件加速 | 启用GPU/NNAPI加速(需设备支持)。 |
| 帧率控制 | 对实时场景限制处理帧率(如每秒3~5帧)。 |
相关问题与解答
问题1:如何处理多个目标重叠的情况?
解答:
通过调整非极大值抑制(NMS)的阈值(如从0.5降低到0.3),允许保留部分重叠框,若仍需合并,可计算加权平均坐标或选择置信度最高的框作为主框。

问题2:如何提升小物体的识别准确率?
解答:
- 数据层面:在训练集中增加小物体样本,或使用数据增强(如随机裁剪)。
- 模型层面:选择锚框设计更密集的模型(如YOLOv5的多尺度锚框),或采用高分辨率输入(如
640x640)。 - 后处理优化:对小物体设置更低的NMS阈值,避免被大框覆盖