上一篇
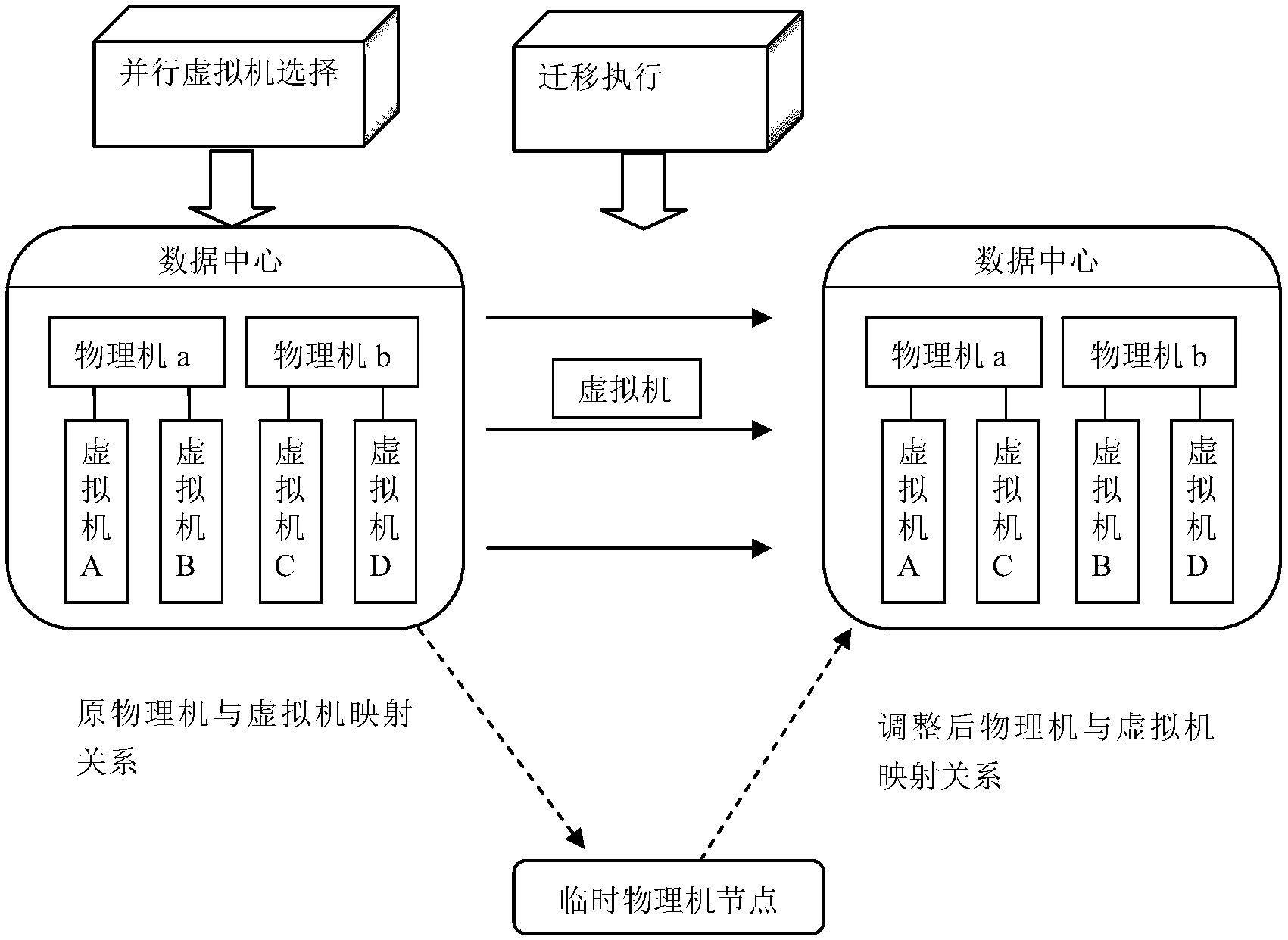
物理机死机 虚拟机
机死机时,其上运行的虚拟机也会受影响,因依赖宿主机资源,常同步
现象关联性分析
- 资源竞争引发的连锁反应:当虚拟机配置过高时(如将8G内存全部分配给虚拟系统),可能导致物理主机因剩余资源不足而卡死,此时需通过任务管理器终止相关进程才能恢复操作,这种情况常见于未合理规划资源的多虚拟机环境。
- 软件兼容性缺陷导致的双向影响:某些操作系统更新可能与虚拟化层产生冲突,例如Windows 10 1903版本曾出现VMware Workstation启动即黑屏的问题,只能强制重启物理机解决,这类问题通常需要回退系统版本或升级兼容的虚拟机软件。
- 异常进程的传播效应:运行在虚拟机内的故障程序可能突破隔离机制影响底层宿主机,如Python线程调用错误导致CPU/内存占满的情况,最终致使整个服务器瘫痪且无法正常关机。
典型故障场景处理方案
| 故障类型 | 特征表现 | 解决步骤 | 注意事项 |
|---|---|---|---|
| 虚拟机内部卡死 | 界面无响应但鼠标可移动;任务栏图标静止 | ①优先尝试管理平台的重启按钮→②若无效则强制结束进程→③检查日志定位根本原因 | 频繁发生需考虑快照回滚或重建虚拟磁盘 |
| 主机连带死机 | 所有虚拟机同步崩溃;键盘指示灯熄灭;必须长按电源键强制关机 | ①调整虚拟硬件参数(特别是内存配额)→②更新Hypervisor至稳定版→③隔离有问题的虚拟设备 | 避免设置等于物理机总内存的虚拟内存配额 |
| 启动阶段黑屏 | 开机自检未完成即停滞;控制台无输出信息 | ①降低显卡直通负载→②关闭Resize Bar等BIOS选项→③移除OC引导参数中的调试标记(-v) | ProxmoxVE环境建议使用KVM-Opencore修复包 |
深度优化策略
- 动态资源调度机制:建立基于优先级的资源分配策略,对关键业务虚拟机设置CPU亲和性绑定,同时启用气球驱动进行内存回收,建议保留至少20%的物理内存余量作为缓冲区。
- 隔离域强化设计:采用PCI设备直通时,应为每个穿透设备创建独立的IOMMU组,防止设备中断风暴扩散到宿主机内核层面,PowerCLI脚本可批量检查设备映射状态。
- 监控预警体系建设:部署Zabbix等监控系统实时采集ESXi主机的balloon统计值、VMKPTITER次数等指标,当检测到虚拟页交换频率超过阈值时自动触发告警。
- 灾难恢复演练:定期测试从快照还原、克隆迁移到P2V转换等多种容灾方案,确保在物理机宕机时能快速切换至备用节点继续提供服务。
预防性维护措施
- 版本控制矩阵:建立宿主机OS与虚拟化套件的版本兼容对照表,例如确认VMware 15.1.0与Windows 10 1903的组合已验证稳定性,避免跨版本升级带来的未知风险。
- 热补丁管理流程:对生产环境中运行的虚拟机启用自动化更新通道,但延迟24小时应用功能性更新,优先测试安全补丁的影响范围。
- 硬件健康度巡检:每月执行一次压力测试,使用FurMark加载GPU、MemTest86检测内存错误,提前发现可能导致系统不稳定的硬件隐患。
FAQs:

-
问:虚拟机频繁死机是否一定需要重启物理机?
答:不是必须,多数情况下可通过结束对应进程(如找到vmware.log中的PID后在任务管理器终止)、调整资源分配或重建虚拟磁盘来解决,仅当所有方法失效且影响其他虚拟机时才考虑重启物理机。 -
问:如何判断是虚拟机本身故障还是物理机问题?
答:先观察单台虚拟机异常还是批量出现,若仅个别有问题,检查其配置文件和内部系统日志;若普遍发生则监控主机资源使用率(重点看CPU/内存峰值)、核对虚拟交换机流量是否正常,使用命令行工具如`esxtop