上一篇
MapReduce工作流程,如何详细审查申请内容?
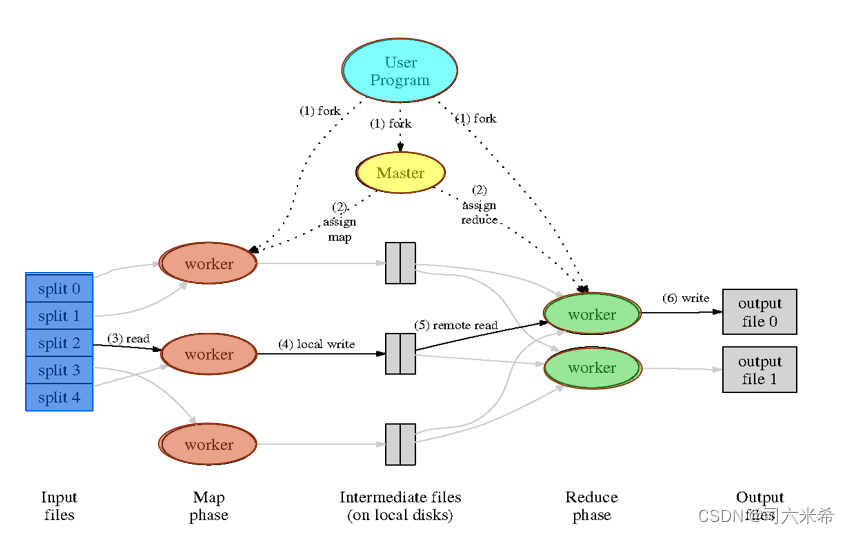
MapReduce的具体流程包括:数据分割、映射(Map)阶段、洗牌和排序、规约(Reduce)阶段,以及最终输出结果。
MapReduce是一个用于处理和生成大数据集的编程模型,最早由Google提出,并被广泛应用于大数据处理,以下是MapReduce的具体流程:
分片(Split)阶段
1、数据源分片:输入的大规模数据文件会被划分为多个独立的数据块,这些数据块称为分片(Split),在Hadoop中,每个分片默认大小为128MB。
2、任务分配:每个分片会分配给一个Map任务,该任务负责处理分片中的所有记录。
Map阶段
1、读取与解析数据:Map任务通过RecordReader从输入的分片中解析出键值对<key,value>,key通常表示数据的偏移量,value表示具体的数据内容。
2、数据处理:解析出的键值对会传递给用户定义的map()函数进行处理,生成中间的键值对结果。
3、缓冲区写入:处理后的键值对首先写入内存缓冲区,缓冲区默认大小为100MB,当缓冲区达到阈值(如80%)时,溢出的数据会被写到磁盘上。
4、分区与排序:在溢写过程中,MapReduce会对数据按key进行排序和分区,确保相同key的数据被分配到同一个Reduce任务。
Shuffle阶段
1、数据传输:Shuffle过程将Map阶段输出的中间结果数据传输给Reduce任务,此过程包括数据的复制、合并和排序操作。
2、合并与压缩:在数据传输过程中,MapReduce框架会对数据进行合并和压缩,以减少网络传输的数据量。
Reduce阶段
1、数据读取:Reduce任务从Map任务或其他Reduce任务获取排序后的中间结果数据。
2、数据处理:Reduce任务将获取的<key,{value list}>形式的数据传递给用户定义的reduce()函数进行处理,最终生成<key,value>形式的输出。
3、输出结果:处理后的结果数据通过OutputFormat的write方法写入到HDFS中。
MapReduce通过分片、Map阶段、Shuffle阶段和Reduce阶段的协同工作,实现了对大规模数据集的高效并行处理,其核心在于将复杂的计算任务分解为简单的小任务,通过分布式计算框架实现高效的数据处理和计算。
| 阶段 | 描述 | 具体流程 |
| 1. 初始化 | 启动MapReduce框架,配置作业参数,如输入输出路径、作业名称等。 | 启动JobTracker和TaskTracker 配置作业参数(如作业名称、输入输出路径等) |
| 2. 输入读取 | 读取输入数据,并将其切分成多个数据块(Split)。 | 使用InputFormat读取输入数据 将输入数据切分成多个Split |
| 3. 分区(Shuffle) | 将数据块分发到各个Map任务,并根据key进行分区。 | 根据key将数据块分发到对应的Map任务 对数据进行排序和分组 |
| 4. Map阶段 | 对每个数据块进行处理,将中间结果输出到本地磁盘。 | 对每个数据块进行Map操作 将中间结果写入本地磁盘的中间文件 |
| 5. Reduce阶段 | 对Map阶段输出的中间结果进行合并和处理,最终输出结果。 | 从Map任务获取中间结果 对中间结果进行排序和分组 对分组后的数据进行Reduce操作 |
| 6. 输出写入 | 将Reduce阶段的输出结果写入到最终的输出路径。 | 将Reduce阶段的输出结果写入到最终的输出路径 |
| 7. 作业完成 | MapReduce作业完成,JobTracker向用户返回作业完成状态。 | 通知用户作业完成状态 清理作业相关资源 |
表格仅为MapReduce流程的简化描述,实际运行过程中可能涉及更多细节和优化。