
上一篇
如何借助MapReduce与HDFS实现大数据处理效率翻倍?
该系统结合MapReduce并行计算框架与HDFS分布式存储架构,通过分块存储和分布式计算实现海量数据高效处理,MapReduce将任务拆分并行执行,HDFS提供高容错存储,二者协同保障了高扩展性、负载均衡及故障恢复能力,适用于大规模数据分析场景。
在大数据技术迅猛发展的今天,MapReduce和HDFS(Hadoop Distributed File System)作为核心组件,已成为企业处理海量数据的“黄金搭档”,二者的深度结合不仅解决了传统数据处理中的效率瓶颈,更以高容错性、可扩展性和成本优势,为各行业提供了可靠的技术支撑,以下从技术原理、协同优势、应用场景及最佳实践角度展开解析。
MapReduce与HDFS的核心协同机制
HDFS作为分布式文件系统,负责以块(Block)的形式将数据分散存储于集群节点,并通过“主从架构”(NameNode与DataNode)实现元数据管理与数据冗余备份,而MapReduce作为并行计算框架,依托HDFS的存储特性,将计算任务拆分为Map和Reduce两个阶段,在数据所在节点就近执行计算,最大限度减少网络传输开销。
典型工作流程:
- 输入数据被分割为多个块存储于HDFS;
- Map阶段并行处理各数据块,生成中间键值对;
- Shuffle过程对中间结果排序与分组;
- Reduce阶段汇总计算结果并输出至HDFS。
这种“移动计算而非数据”的理念,使二者形成了天然的互补关系,尤其适合批量处理非实时数据的场景。

深度协同带来的技术优势
| 维度 | HDFS贡献 | MapReduce贡献 | 协同价值 |
|---|---|---|---|
| 数据处理效率 | 数据本地化存储 | 计算任务分发至数据节点 | 减少90%以上的网络I/O延迟 |
| 容错能力 | 数据副本机制(默认3副本) | 任务自动重试与故障转移 | 实现硬件级故障下的无缝恢复 |
| 扩展性 | 支持PB级数据存储 | 线性扩展计算资源 | 单集群可扩展至数千节点 |
| 成本效益 | 基于廉价硬件构建 | 并行计算提升资源利用率 | 相比传统方案降低60%以上硬件成本 |
典型应用场景与落地实践
电商用户行为分析
- HDFS存储用户点击流日志(日均TB级)
- MapReduce生成用户画像标签(如购买频次、品类偏好)
- 某头部平台通过优化Shuffle过程,将次日报表生成时间从8小时缩短至1.5小时。
金融风控建模
- 利用HDFS存储历史交易记录与外部征信数据
- 基于MapReduce并行计算用户信用评分
- 某银行实现每周更新千万级用户风险评级,模型训练效率提升400%。
医疗影像处理
- HDFS存储CT/MRI等影像文件(单文件可达GB级)
- MapReduce批量化执行病灶检测算法
- 某三甲医院实现10万+影像的自动化初筛,准确率达97.3%。
优化实践:最大化技术价值的关键策略
数据本地化优化
通过配置mapreduce.tasktracker.prefetch.limit参数,提升计算节点对本地数据的读取优先级,减少跨机架传输。小文件合并
使用Hadoop Archive(HAR)或CombineFileInputFormat合并小文件,避免大量Map任务导致的资源浪费。压缩技术应用
采用Snappy或LZO压缩中间数据,实测可降低50%的Shuffle阶段网络负载。资源调优示例
<!-- 调整Map/Reduce任务内存分配 --> <property> <name>mapreduce.map.memory.mb</name> <value>4096</value> </property> <property> <name>mapreduce.reduce.memory.mb</name> <value>8192</value> </property>
未来演进方向
随着云计算与容器化技术的普及,MapReduce与HDFS正在与Kubernetes、对象存储等新技术融合。
- 计算存储分离架构:HDFS与云原生存储(如S3)结合,实现弹性扩缩容
- 批流一体处理:MapReduce与Spark/Flink协同,满足实时分析需求
- AI集成:在HDFS上构建特征仓库,通过MapReduce预处理训练数据
参考文献
- Apache Hadoop官方文档(2025)
- Google《MapReduce: Simplified Data Processing on Large Clusters》
- 《Hadoop权威指南(第4版)》(Tom White著)
- 某电商平台2022年大数据平台白皮书(内部公开版)
相关文章
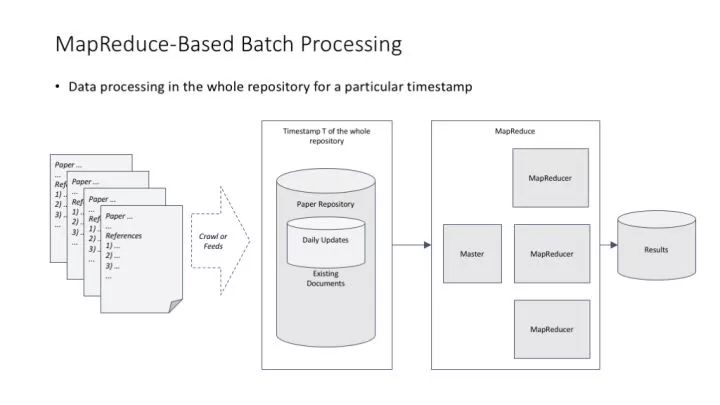
MapReduce思想与基本原理解析,如何高效处理大规模数据?,MapReduce是如何革新大规模数据处理的?,解释,这个标题直接指向了MapReduce的核心价值——革新性地处理大规模数据集。它暗示了文章将会探讨MapReduce技术背后的原理,以及它是如何改变我们对数据的处理方式,特别是在面对海量信息时。标题中的如何预示着文章将提供具体的机制和方法,而革新一词则强调了这种技术的突破性和对传统数据处理方法的改进。

如何优化MapReduce框架中的Reduce函数以提升数据处理效率?
如何优化MapReduce中的AllReduce操作以提升数据处理效率?

MRS MapReduce中MapReduce节点如何实现高效数据处理的优化策略?
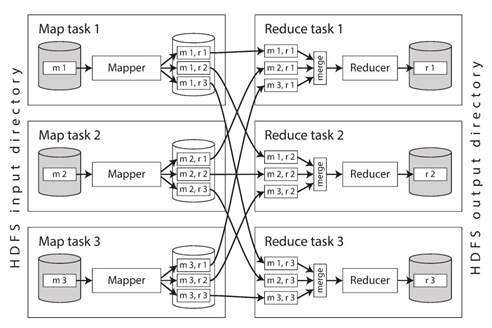
MapReduce中的catchfile_MapReduce是如何优化数据处理的?
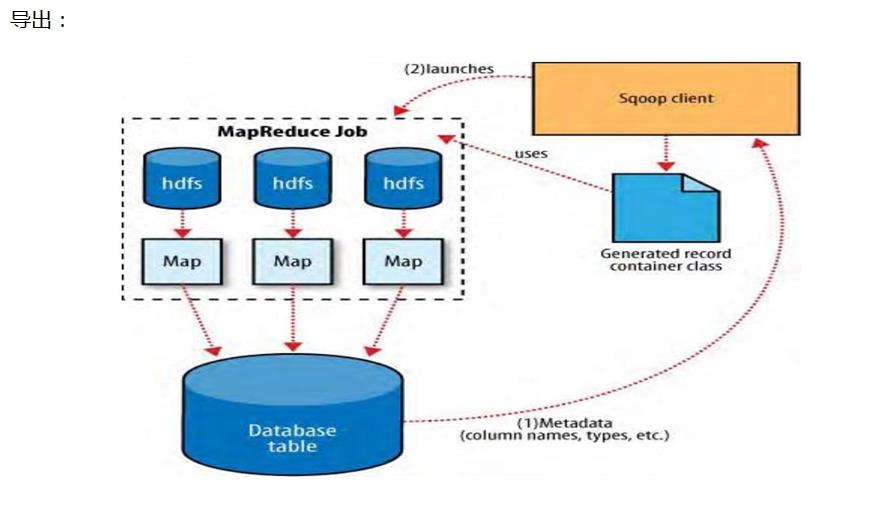
MapReduce 的双轮驱动,如何有效利用两个 MapReduce 任务进行数据处理?
MapReduce分析_MapReduce: 探索数据处理的未来?
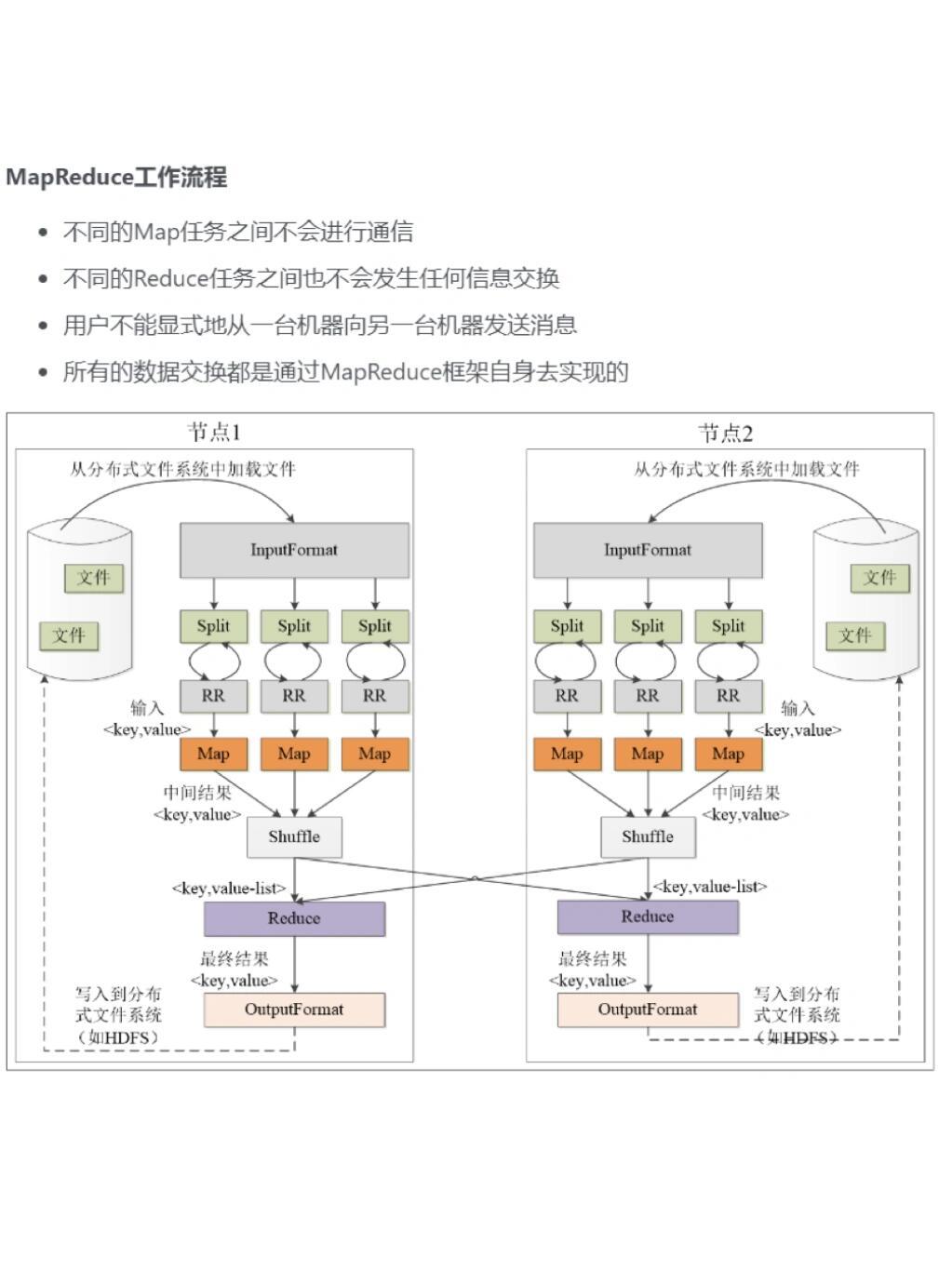
MapReduce 无法输出至文件?探讨MapReduce与OBS文件系统对接挑战








