
上一篇
DataX如何助力你的数据迁移效率翻倍?
DataX是阿里巴巴开源的高效离线数据同步工具,支持异构数据源间批量传输,具备可扩展架构与插件体系,它通过配置文件定义作业,提供多种读写插件(如MySQL、HDFS等),支持断点续传、脏数据管控及并发控制,适用于大数据迁移、数仓构建等场景,以低代码方式实现稳定可靠的数据流转。
DataX:高效可靠的数据同步工具
什么是DataX?
DataX是阿里巴巴开源的一款异构数据源离线同步工具,致力于实现各类数据库、数据仓库、文件系统之间的高效数据迁移,作为一款基于Java开发的ETL(Extract-Transform-Load)工具,DataX通过插件化架构支持多种数据源,并能够处理大规模数据迁移任务,满足企业级高可靠、高性能的需求。
核心功能与特性
多数据源支持
DataX内置丰富的插件,支持包括MySQL、Oracle、HDFS、Hive、HBase、FTP等在内的30+数据源类型,覆盖主流数据库与文件系统,用户可通过配置轻松实现不同数据源间的数据迁移。高并发与高性能
基于分布式设计,DataX通过分段(Split)机制将任务切分为多个子任务并行执行,显著提升同步效率,提供流量控制、脏数据管理等功能,确保任务稳定运行。数据一致性保障
采用事务机制与断点续传技术,DataX在迁移过程中严格保证数据的准确性与完整性,即使任务中断也能从断点继续执行,避免重复传输或数据丢失。灵活可扩展
插件化架构设计允许开发者快速扩展新的数据源,仅需实现Reader(数据读取)和Writer(数据写入)接口即可完成适配。
架构解析
DataX的核心架构分为以下模块:
- Job:用户提交的完整同步任务,包含全局配置与数据通道参数。
- JobSplit:根据配置将Job拆分为多个子任务(Split),分配至不同节点执行。
- Task:实际执行数据同步的最小单元,由Reader和Writer组成,负责数据提取与写入。
- Reader:从源数据源读取数据的组件,支持全量或增量模式。
- Writer:向目标数据源写入数据的组件,支持批量提交与事务控制。
整个流程通过中央调度器(DataX Engine)协调,实现任务分发、状态监控与错误重试。
典型应用场景
- 数据仓库构建
将业务数据库(如MySQL)的数据定期同步至Hive或HDFS,支撑大数据分析。 - 跨系统数据迁移
在数据库升级或系统重构时,快速完成Oracle到MySQL、HBase到Elasticsearch等迁移。 - 数据备份与恢复
通过定时任务将生产数据备份至文件系统或冷存储,保障数据安全。 - 多云/混合云数据互通
实现本地IDC与云上数据库(如阿里云RDS、AWS Redshift)的双向同步。
DataX的独特优势
- 低代码操作:通过JSON配置文件定义任务,无需编写复杂代码。
- 资源占用少:作为轻量级工具,对系统资源消耗低,适合中小型团队使用。
- 社区生态完善:背靠阿里巴巴技术生态,拥有活跃的开源社区和持续更新维护。
- 兼容性强:支持主流操作系统(Linux/Windows)与JDK版本,适配企业IT环境。
使用流程示例
安装部署
下载DataX压缩包并解压,通过命令行工具验证安装:python {DATAX_HOME}/bin/datax.py {JOB_CONFIG_PATH}配置任务文件
编写JSON格式的Job配置文件,定义Reader与Writer参数:{ "job": { "content": [{ "reader": { "name": "mysqlreader", "parameter": { "username": "root", "password": "xxx", "column": ["id","name"], "connection": [{ "jdbcUrl": ["jdbc:mysql://127.0.0.1:3306/db"], "table": ["table"] }] } }, "writer": { "name": "hdfswriter", "parameter": { "path": "/data/output", "fileName": "result", "writeMode": "append" } } }] } }运行与监控
执行任务后,可通过日志文件或Web界面实时查看同步进度、传输速率及错误信息。
最佳实践建议
- 性能优化:
- 调整
channel参数提升并发度,结合硬件资源设置合理值。 - 启用
bufferSize与batchSize减少I/O操作次数。
- 调整
- 错误处理:
- 设置
errorLimit限制脏数据量,避免任务因少量错误失败。 - 定期清理过期日志,避免磁盘空间不足。
- 设置
- 安全合规:
- 使用加密连接(如SSL)传输敏感数据。
- 通过权限控制限制数据访问范围。
常见问题(FAQ)
Q1:DataX是否支持实时数据同步?
DataX定位为离线批处理工具,实时场景建议结合Canal、Flink等流式处理框架。
Q2:如何处理同步过程中的数据类型差异?
DataX会自动进行类型映射(如MySQL的DATETIME转Hive的TIMESTAMP),用户也可通过配置自定义转换规则。
Q3:任务运行缓慢如何排查?
检查网络带宽、源库/目标库负载、并发数设置,或启用-Doracle.jdbc.Trace=true进行性能分析。
引用说明 参考自DataX官方GitHub文档与实践案例,数据截至2025年10月。
相关文章
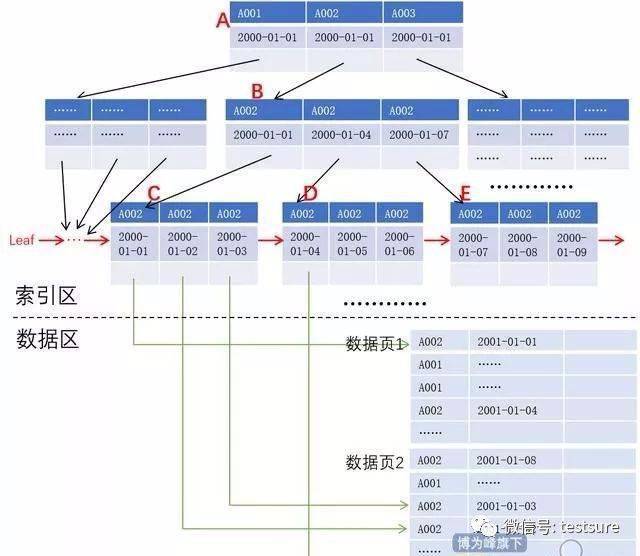
如何让大数据存储与索引效率翻倍?
如何用Linux命令行让工作效率翻倍?

个人云服务器应用如何助力你的数据管理既高效又安全?
如何优化MongoDB MapReduce操作以提升数据迁移效率?
CDN资源如何助力你的网站实现流量暴增?

业务服务器数据迁移指南:快速高效完成迁移 (怎么做业务服务器数据迁移)
企业数据迁移,企业邮箱数据迁移2022年更新(企业邮箱迁移邮件)
processes_镜像保存时报错“there are processes in 'D' status, please check process status using 'ps aux' and kill all the 'D' status processes”或“Buildimge,False,Error response from daemon,Cannot pause container xxx”如何解决?








