上一篇
分布式存储有哪些不同的分类?
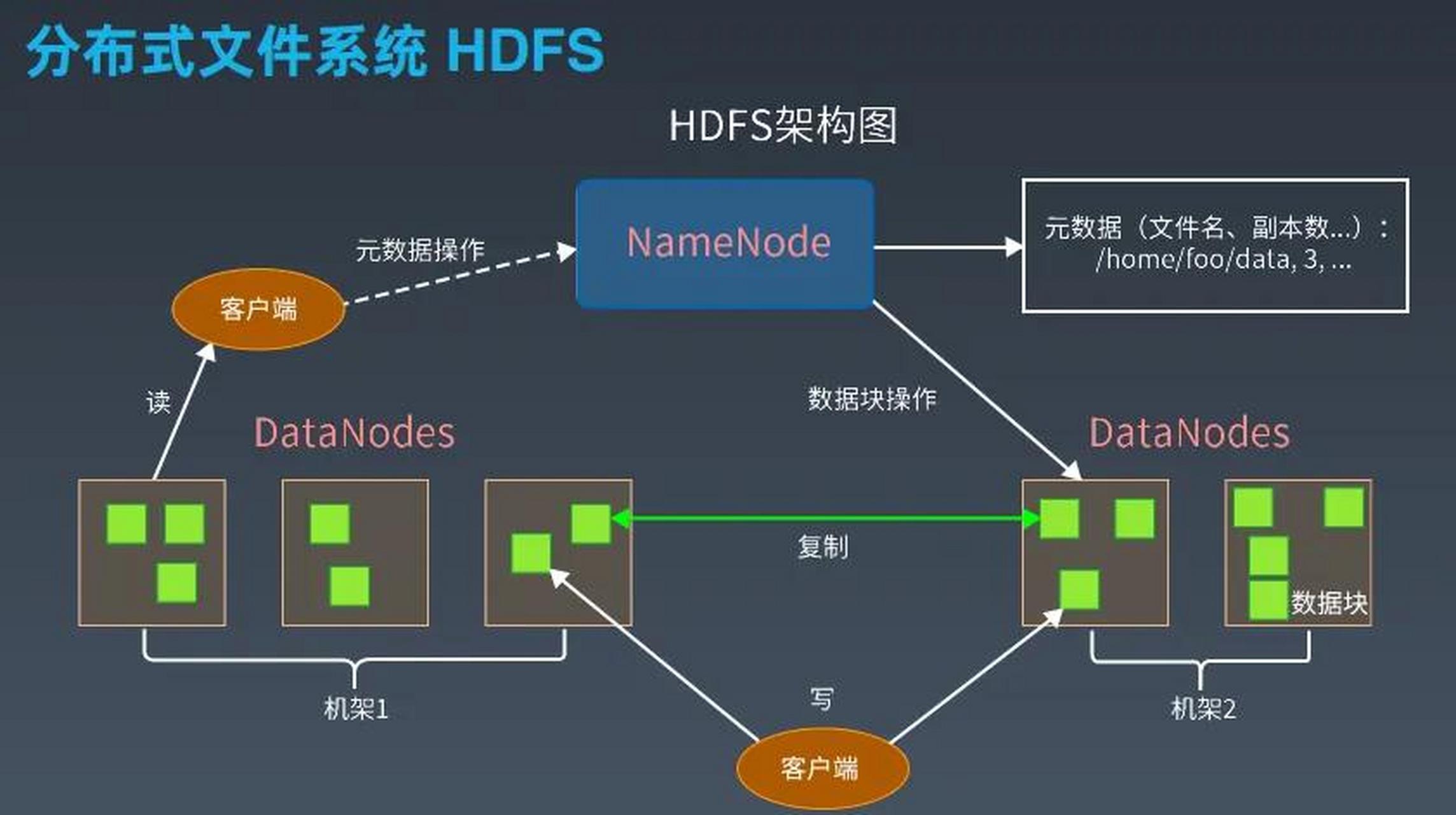
分布式存储主要分类包括:分布式文件系统、分布式块存储和分布式对象存储。分布式文件系统如HDFS,适用于大文件存储;分布式块存储如Ceph,提供块级数据存取;分布式对象存储如Amazon S3,支持海量非结构化数据管理。
分布式存储是一种数据存储技术,它将数据分散存储在多台独立的机器上,以提高数据的可靠性和可用性,分布式存储系统可以根据不同的分类标准进行分类,主要包括以下几种:
1、按照数据一致性模型分类:
强一致性(Strong Consistency):所有节点的数据在任何时刻都是相同的,Google Spanner。
弱一致性(Weak Consistency):允许部分节点的数据在一定时间内不同步,Amazon DynamoDB。
最终一致性(Eventual Consistency):保证在没有新的更新操作的情况下,数据最终会达到一致状态,Cassandra。
2、按照数据分区方式分类:
范围分区(Range Partitioning):按照数据的范围进行分区,如按照时间范围、ID范围等,HBase。
哈希分区(Hash Partitioning):根据数据的哈希值进行分区,将数据均匀地分布在各个节点上,Redis Cluster。
列表分区(List Partitioning):将数据按照顺序存储在列表中,适用于顺序访问的场景,Amazon S3。

3、按照数据副本策略分类:
单副本(Single Replication):每个数据只有一个副本,适用于对数据可靠性要求不高的场景,MongoDB的WiredTiger存储引擎。
多副本(Multiple Replication):每个数据有多个副本,提高数据的可靠性和可用性,HDFS。
4、按照数据类型分类:
结构化数据存储:适用于存储关系型数据库中的数据,如MySQL、PostgreSQL等。
半结构化数据存储:适用于存储JSON、XML等半结构化数据,如MongoDB、Couchbase等。
非结构化数据存储:适用于存储文本、图片、视频等非结构化数据,如Amazon S3、Google Cloud Storage等。
5、按照应用场景分类:
大规模分布式存储系统:适用于海量数据的存储和处理,如Hadoop HDFS、Ceph等。
实时分布式存储系统:适用于高并发、低延迟的数据存储和访问,如Redis、Memcached等。
分布式文件系统:适用于分布式计算和大数据分析场景,如HDFS、GlusterFS等。
以下是一个简单的表格,归纳了上述分类及其特点:
| 分类标准 | 类型 | 特点 |
| 数据一致性模型 | 强一致性 | 所有节点的数据在任何时刻都是相同的 |
| 弱一致性 | 允许部分节点的数据在一定时间内不同步 | |
| 最终一致性 | 保证在没有新的更新操作的情况下,数据最终会达到一致状态 | |
| 数据分区方式 | 范围分区 | 按照数据的范围进行分区 |
| 哈希分区 | 根据数据的哈希值进行分区,将数据均匀地分布在各个节点上 | |
| 列表分区 | 将数据按照顺序存储在列表中,适用于顺序访问的场景 | |
| 数据副本策略 | 单副本 | 每个数据只有一个副本,适用于对数据可靠性要求不高的场景 |
| 多副本 | 每个数据有多个副本,提高数据的可靠性和可用性 | |
| 数据类型 | 结构化数据存储 | 适用于存储关系型数据库中的数据 |
| 半结构化数据存储 | 适用于存储JSON、XML等半结构化数据 | |
| 非结构化数据存储 | 适用于存储文本、图片、视频等非结构化数据 | |
| 应用场景 | 大规模分布式存储系统 | 适用于海量数据的存储和处理 |
| 实时分布式存储系统 | 适用于高并发、低延迟的数据存储和访问 | |
| 分布式文件系统 | 适用于分布式计算和大数据分析场景 |
FAQs:
Q1: 分布式存储系统的主要优势是什么?
A1: 分布式存储系统的主要优势包括高可用性、高扩展性和容错性,通过将数据分散存储在多个节点上,即使部分节点出现故障,整个系统仍然可以正常运行,分布式存储系统可以根据需要动态地添加或删除节点,实现弹性扩展。
Q2: 如何选择适合自己业务场景的分布式存储系统?
A2: 选择适合自己业务场景的分布式存储系统时,需要考虑以下几个因素:数据一致性需求、数据类型、访问模式、性能要求、成本预算等,根据这些因素,可以选择相应的分布式存储系统,如关系型数据库、NoSQL数据库、分布式文件系统等,可以参考业界的成功案例和最佳实践,以便更好地满足业务需求。