上一篇
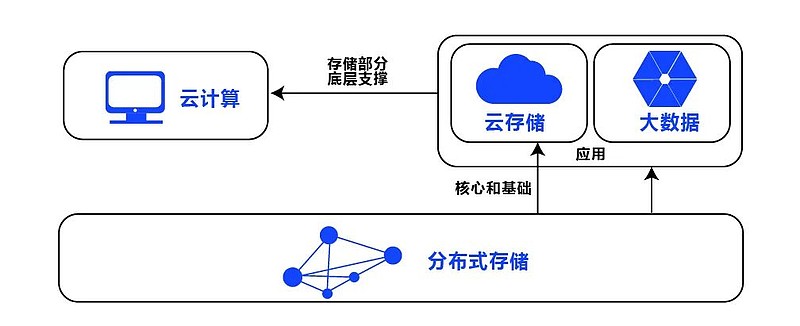
分布式共享存储系统如何玩
分布式共享存储系统通过分布式架构将数据分片并冗余存储,借助一致性协议保障数据正确性,客户端可透明读写,实现高可用与
架构、原理与实践指南
基础概念与核心价值
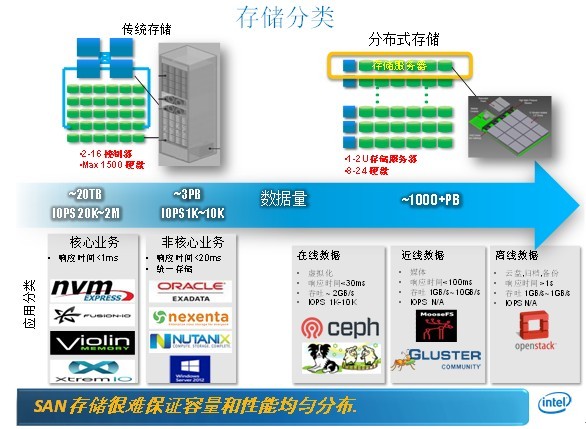
分布式共享存储系统是通过多台服务器协同工作,将数据分散存储在多个节点上,同时对外提供统一访问接口的存储架构,相较于传统集中式存储,其核心优势体现在:
- 弹性扩展:通过增加节点即可提升容量和性能
- 高可用性:数据冗余机制保障99.99%以上可用性
- 性能优化:并行化数据处理提升吞吐能力
- 成本效益:利用普通PC服务器构建存储集群
典型应用场景包括:云计算IaaS层存储、大数据分析平台、容器持久化存储、视频云存储等。
架构设计与关键技术
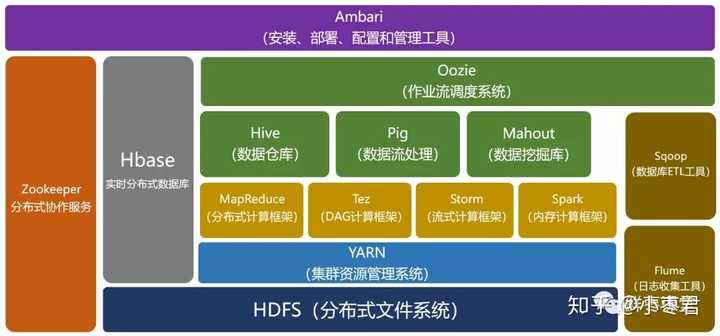
(一)系统架构组件
| 组件类型 | 功能描述 | 代表技术 |
|---|---|---|
| 存储节点 | 实际存储数据的物理服务器 | Ceph OSD/MinIOPod |
| 元数据服务 | 管理文件元信息和目录结构 | Ceph MON/GlusterFS MDS |
| 客户端SDK | 提供标准API接口 | POSIX/S3/NFS协议栈 |
| 协调服务 | 集群状态管理和仲裁 | ZooKeeper/Etcd |
(二)数据分布策略
哈希分片算法:
- 一致性哈希(Consistent Hashing)实现负载均衡
- 虚拟节点技术解决数据倾斜问题
- 示例:Ceph的CRUSH算法支持权重调整
副本控制机制:
- 副本因子(Replication Factor)决定数据冗余度
- 跨机架/机房部署实现故障域隔离
- 典型配置:3副本(读写性能平衡)或EC纠删码(空间效率优先)
(三)元数据管理方案
| 方案类型 | 适用场景 | 优缺点 |
|---|---|---|
| 单点MDS | 小规模集群 | 架构简单,存在单点瓶颈 |
| 多活MDS | 大型集群 | 高可用,需解决数据一致性 |
| 无中心MDS | 对象存储 | 完全分布式,依赖最终一致性 |
核心技术实现原理
(一)数据分片与复制
动态分片流程:
- 客户端计算数据分片ID(ShardID)
- 根据哈希环定位主副本节点
- 同步写入后续副本节点
- 确认所有副本写入成功后返回ACK
副本同步机制:
- 强一致性:2PC协议保证原子性(如HDFS)
- 最终一致性:异步复制+版本控制(如DynamoDB)
- 混合模式:主从同步+次级异步(Ceph OSD)
(二)元数据管理优化
分层缓存策略:

- L1:本地内存缓存最近访问的元数据
- L2:分布式缓存(Redis/Memcached)加速热数据访问
- L3:持久化存储历史元数据
目录结构优化:
- 扁平化命名空间(Object Store)
- 层级化文件系统(POSIX兼容)
- 混合模式(Ceph同时支持RADOS和CephFS)
(三)客户端访问接口
| 协议类型 | 适用场景 | 性能特征 |
|---|---|---|
| NFS/CIFS | 传统应用兼容 | 高延迟,适合小文件 |
| S3 API | 云原生应用 | RESTful架构,扩展性强 |
| POSIX | 高性能计算 | 低延迟,支持并发访问 |
性能优化实战技巧
(一)硬件配置建议
| 组件类型 | 推荐配置 | 关键参数 |
|---|---|---|
| 存储节点 | SSD+HDD混合 | 读缓存命中率>95% |
| 网络架构 | RDMA网络 | 延迟<10μs |
| JBOD扩展 | SAS扩展柜 | 通道带宽≥6Gbps |
(二)软件调优策略
CRUSH地图优化:
- 根据磁盘IOPS调整权重系数
- 设置阶梯式故障域(机房>机柜>节点)
- 示例配置:
osd_pool_default_size=3
缓存参数调整:
- 读缓存预读长度(Ceph:
osd_read_cache_pages) - 写缓存刷新阈值(MinIO:
MINIO_CACHE_DRAIN_INTERVAL) - 元数据缓存TTL(CephFS:
mds_cache_expire_value)
- 读缓存预读长度(Ceph:
(三)典型场景优化
大文件顺序写入:
- 启用对象存储的Multipart Upload
- 配置RADOS条带化宽度(Ceph:
osd_client_write_chunk_size)
小文件并发访问:
- 启用元数据预加载(GlusterFS:
metadata-cache) - 使用组合式CRUSH规则(文件大小+哈希值)
- 启用元数据预加载(GlusterFS:
运维管理要点
(一)监控体系构建
| 监控维度 | 关键指标 | 告警阈值 |
|---|---|---|
| 容量监控 | 剩余空间<15% | WARN级别 |
| 性能监控 | 延迟>50ms | CRITICAL |
| 健康检查 | OSD下线>3% | MAJOR |
(二)故障处理流程
节点故障处理:
- Step1:触发CRUSH重平衡(Ceph自动恢复)
- Step2:检查PG状态(
ceph pg dump) - Step3:替换VSM失败的副本(
ceph osd primary-affinity)
网络分区处理:
- 启用仲裁机制(ZooKeeper多数派原则)
- 临时提升读权限(Ceph:
allow_multiple_osds) - 日志分析定位根因(
/var/log/ceph/日志聚合)
安全与合规实践
(一)数据加密方案
| 加密类型 | 实现方式 | 性能影响 |
|---|---|---|
| 传输加密 | TLS1.3+AES-GCM | <5%延迟 |
| 静态加密 | dm-crypt/AES-256 | CPU消耗<8% |
| 对象加密 | SSE-C/SSE-KMS | AWS KMS集成 |
(二)访问控制策略
RBAC模型实现:
- Ceph:
ceph auth get-or-create命令配置权限 - MinIO:Policy文档定义资源访问规则
- S3:IAM策略+Bucket Policy双重控制
- Ceph:
审计日志管理:
- 启用操作日志(Audit Log)
- 保留周期符合GDPR要求(≥1年)
- 异常行为检测(UFW+Fail2ban)
典型应用场景实践
(一)云计算环境部署
OpenStack集成方案:
- Cinder驱动对接Ceph RBD
- Swift容器适配MinIO架构
- Manila文件系统挂载优化
Kubernetes存储适配:
- RWO/RWX访问模式配置
- CSI插件开发(Ceph/MinIO)
- StatefulSet存储声明周期管理
(二)大数据平台优化
HDFS替代方案:
- CephFS作为NameNode后端存储
- 对象存储加速MapReduce任务
- 纠删码降低存储成本30%+
Spark作业优化:
- 数据本地性优化(delayed block fetch)
- 缓存策略调整(MEMORY_AND_DISK)
- 动态资源分配(on-demand storage)
FAQs常见问题解答
Q1:如何判断集群是否需要扩容?
A1:当出现以下情况时需要考虑扩容:
- 单个池的利用率持续>85%超过7天
- IO等待时间>20ms占比>15%
- Shard分布出现明显热点(标准差>0.3)
建议采用滚动扩容方式,每次增加不超过现有节点数的20%
Q2:如何处理存储节点性能差异问题?
A2:解决方案包括:
- CRUSH权重动态调整:根据IOPS/吞吐量设置权重系数
- 分级存储策略:SSD作为缓存层,HDD存储冷数据
- 工作负载调度:使用Ceph的
osd_op_queue限制低速节点队列长度 - 硬件升级计划:定期检测磁盘健康状态(SMART