上一篇
hive数据库
Hive是基于Hadoop的数据仓库,支持SQL查询,用于大数据分析,适合离线
Hive数据库详解
Hive
Apache Hive是基于Hadoop的数据仓库工具,专为大规模数据处理设计,它通过类SQL语言(HiveQL)实现对分布式存储数据(如HDFS)的查询与分析,将复杂的MapReduce任务封装为直观的SQL语句,降低大数据分析门槛,Hive的核心优势在于支持PB级数据存储、高可扩展性及与Hadoop生态的无缝集成。
核心特性:
- SQL兼容性:支持大部分标准SQL语法,支持JOIN、GROUP BY、窗口函数等复杂操作。
- 分布式执行:自动将查询转换为MapReduce、Tez或Spark作业,利用集群资源并行处理。
- ACID支持:通过事务表实现原子性、一致性、隔离性和持久性(需开启事务支持)。
- 分区与分桶:通过分区(Partition)和分桶(Bucket)优化数据存储与查询效率。
- 元数据管理:依赖Metastore(元数据服务)存储表结构、分区信息等元数据。
Hive架构解析
Hive架构由多个组件协同工作,核心模块如下表所示:

| 组件 | 功能描述 |
|---|---|
| Metastore | 存储数据库、表、分区、列的元数据,通常由关系型数据库(如MySQL)实现。 |
| Driver | 编译并执行HiveQL语句,负责解析、优化及生成执行计划。 |
| Compiler | 将HiveQL转换为抽象语法树(AST),优化查询计划(如谓词下推、列裁剪)。 |
| Execution Engine | 调用底层执行框架(如MapReduce、Tez、Spark)执行任务。 |
| CLI/JDBC/ODBC | 提供多种客户端接口,支持命令行、JDBC连接及第三方工具(如Tableau、Zeppelin)访问。 |
数据流程示例:
- 用户提交HiveQL查询;
- Driver解析语句并生成执行计划;
- Compiler优化逻辑计划(如合并分区、过滤条件下沉);
- Execution Engine将任务拆分为MapReduce阶段;
- HDFS读取数据,Map阶段处理后经Shuffle传递至Reduce阶段;
- 结果返回用户或写入文件系统。
Hive数据模型
Hive采用关系型数据库的表结构,但针对分布式存储进行了优化。
表类型
| 表类型 | 特点 | 适用场景 |
|---|---|---|
| 内部表 | 数据删除时自动移除HDFS文件。 | 临时数据或无需保留原始文件的场景 |
| 外部表 | 数据删除仅删除元数据,保留HDFS文件。 | 需要共享数据或保留原始文件的场景 |
| 分区表 | 按指定字段划分子目录(如dt=2023-01-01)。 | 高频查询字段(如时间、地区)加速查询 |
| 桶表 | 按哈希分配数据到多个桶,支持采样查询。 | 均匀分布数据,提升JOIN效率 |
存储格式
Hive支持多种文件格式,对比如下:
| 格式 | 特点 |
|---|---|
| Text | 纯文本格式,兼容性好,但无压缩与索引,适合小规模数据。 |
| SequenceFile | 二进制格式,支持压缩,适合中等规模数据。 |
| ORC | 列式存储,高效压缩与向量化读取,适合OLAP场景。 |
| Parquet | 列式存储,支持复杂嵌套结构,与ORC性能相近,生态兼容性更强。 |
| Avro | 基于Schema的动态类型,适合半结构化数据(如JSON)。 |
Hive操作实践
建表与加载数据
-创建分区表(按日期分区) CREATE TABLE user_logs ( uid STRING, event_time TIMESTAMP, action STRING, duration INT ) PARTITIONED BY (dt STRING) STORED AS ORC; -加载数据(静态分区) LOAD DATA INPATH '/data/logs/2023-01-01' INTO TABLE user_logs PARTITION (dt='2023-01-01'); -动态分区加载(需开启配置`hive.exec.dynamic.partition=true`) INSERT OVERWRITE TABLE user_logs PARTITION (dt) SELECT uid, event_time, action, duration, dt FROM staging_logs;
查询优化案例
需求:统计每日用户活跃数(UV)。
优化思路:
- 使用分区字段过滤(
WHERE dt='2023-01-01')避免全表扫描。 - 利用
COUNT(DISTINCT uid)替代GROUP BY聚合。 - 开启
mapjoin小表优先策略(如用户画像表小于1GB)。
-非优化写法(全表扫描) SELECT COUNT(DISTINCT uid) FROM user_logs; -优化写法(分区+索引) SELECT COUNT(DISTINCT uid) FROM user_logs WHERE dt='2023-01-01' AND exists (SELECT 1 FROM user_index WHERE user_logs.uid = user_index.uid);
Hive性能调优策略
| 优化方向 | 具体措施 |
|---|---|
| 数据存储优化 | 使用ORC/Parquet格式,开启Snappy压缩;合理设计分区字段(如时间、地域)。 |
| 查询执行优化 | 启用LLAP(低延迟分析缓存)、Tez引擎;限制FILESOURCE大小避免小文件。 |
| 资源配置优化 | 调整mapreduce.job.reduces(根据数据量设置Reducer数量);启用CBO(成本优化器)。 |
| 索引与统计 | 对高频查询字段创建Compacted/Bitmap索引;定期更新表统计信息(ANALYZE TABLE)。 |
Hive应用场景
- 数据仓库:替代传统数仓(如Greenplum),处理TB~PB级离线分析。
- 日志分析:聚合网站/APP日志,生成UV/PV、留存率等指标。
- ETL管道:作为数据中台的中间层,清洗、转换原始数据后写入目标系统。
- 实时分析辅助:通过分区设计加速近实时查询(如最近7天数据)。
FAQs
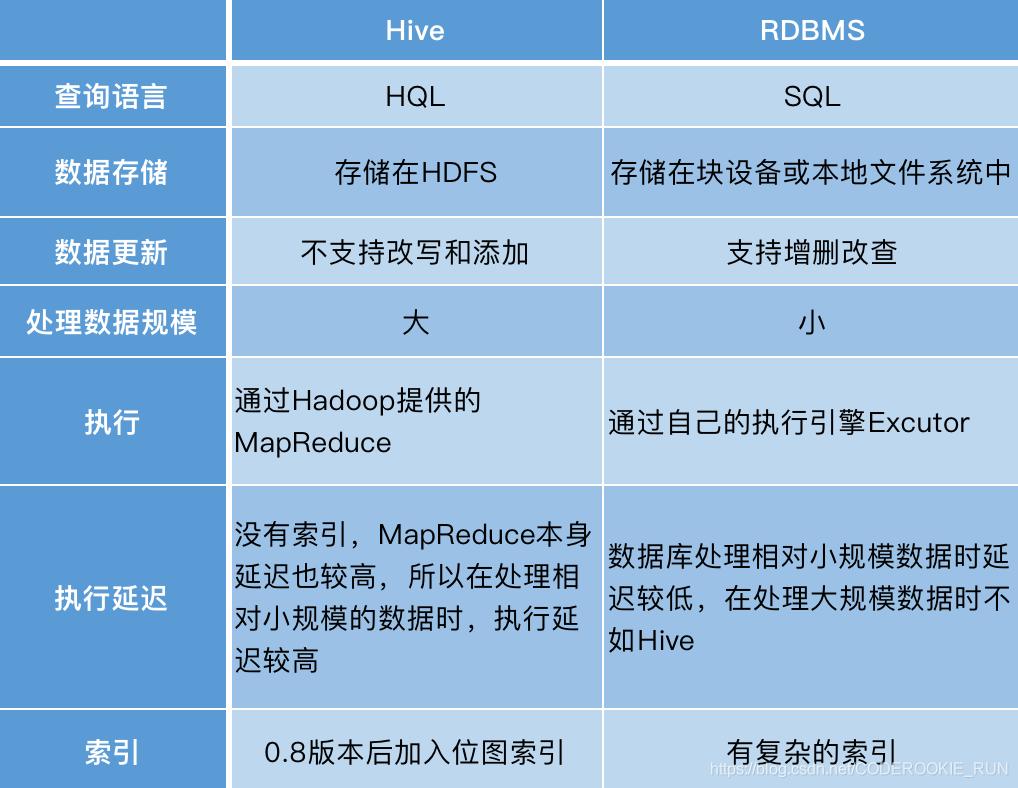
Q1:Hive与MySQL/PostgreSQL等传统数据库有何区别?
A:
| 对比维度 | Hive | 传统数据库 |
|——————–|——————————————-|———————————–|
| 数据规模 | PB级(依赖HDFS) | GB~TB级(受限于单机存储) |
| 计算模型 | 批量处理(MapReduce) | 实时OLTP(行存+B+树索引) |
| 事务支持 | 仅事务表支持ACID(需开启配置) | 强ACID特性 |
| 适用场景 | 离线分析、数据仓库 | 在线交易、实时查询 |
Q2:如何优化Hive的大表JOIN性能?
A:
- 小表广播(MAPJOIN):对小于2GB的表启用
/+ MAPJOIN(small_table) /提示,避免Reduce阶段数据传输。 - 空值过滤:JOIN前增加
WHERE条件过滤空值,减少无效数据参与计算。 - 分桶表对齐:确保两表按相同字段分桶(如
CLUSTERED BY id),启用SMART分桶优化。 - 倾斜处理:对KEY分布不均的字段,使用
skewed关键字