上一篇
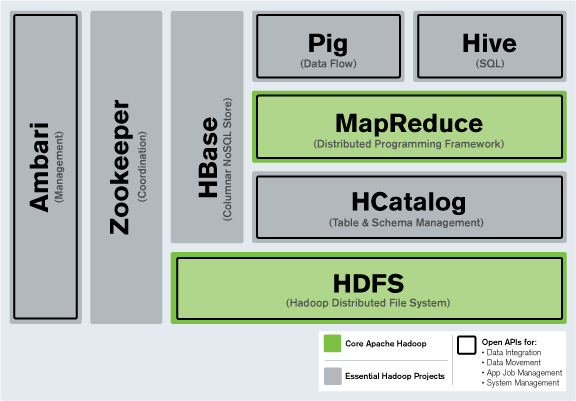
hdfs分布式存储架构
HDFS采用主从架构,数据分块存储并多副本冗余,NameNode管理元数据,DataNode存储数据块,通过心跳检测保障可靠性,具备高扩展与容错能力,适用于海量数据处理
HDFS分布式存储架构详解
架构设计目标与核心思想
HDFS(Hadoop Distributed File System)是Apache Hadoop生态系统中的分布式存储框架,专为大规模数据存储和高吞吐量访问设计,其核心目标是通过冗余存储和分布式管理实现高可靠性、高扩展性及低成本硬件适配,以下是HDFS的关键设计原则:
| 设计目标 | 具体实现 |
|---|---|
| 高容错性 | 数据块多副本存储(默认3份),支持自动故障恢复 |
| 高扩展性 | 通过水平扩展(添加节点)提升存储容量,无需停机重构 |
| 低成本硬件适配 | 支持普通PC服务器集群,通过软件层面实现数据冗余和容错 |
| 高吞吐量数据访问 | 优化批量数据处理,适合顺序读写(如MapReduce任务),而非低延迟随机访问 |
| 可移植性 | 基于Java实现,支持跨平台部署 |
核心组件与职责分工
HDFS采用主从(Master-Slave)架构,主要包含以下角色:
| 组件 | 职责 |
|---|---|
| NameNode | 主节点,负责管理文件系统元数据(如目录结构、块位置信息),所有元数据存储在内存中,支持快速查询。 |
| DataNode | 从节点,负责存储实际数据块(默认128MB),并定期向NameNode发送心跳和块报告。 |
| Secondary NameNode | 辅助节点,用于合并NameNode的编辑日志(Edit Log)和元数据快照(FsImage),减轻NameNode启动负担。 |
| Client | 用户接口,发起文件读写请求,与NameNode和DataNode交互完成操作。 |
关键流程说明:
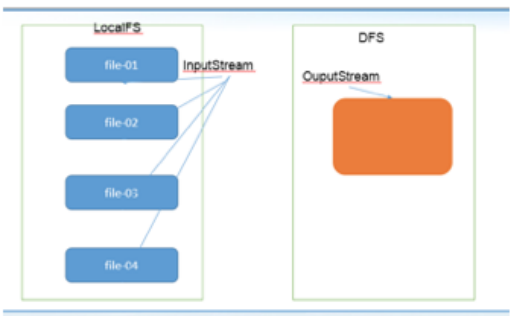
- 写入数据:Client向NameNode申请分配存储块(Block),获取可用DataNode列表后,按顺序将数据分块写入多个DataNode。
- 读取数据:Client向NameNode查询文件元数据,获取块位置信息后直接从DataNode读取数据。
数据存储与管理机制
HDFS将文件拆分为固定大小的数据块(Block),并通过多副本策略保证可靠性:

| 特性 | 详细说明 |
|---|---|
| 块大小 | 默认128MB(可配置),大块设计减少小块文件导致的元数据压力,适合顺序读写。 |
| 副本策略 | 默认3份副本,第一份存写入节点,第二份存同机架不同节点,第三份存不同机架节点。 |
| 元数据管理 | NameNode内存中维护文件树(Inode)和块映射表(Block->DataNodes),元数据持久化到磁盘(FsImage+EditLog)。 |
| 数据一致性 | 写入时采用“写前日志”(WAL)机制,确保元数据操作原子性。 |
元数据存储结构示例:
FsImage(快照) + EditLog(操作日志) → 合并后生成新FsImage容错与高可用机制
HDFS通过以下机制实现故障容忍:
| 故障类型 | 应对措施 |
|---|---|
| DataNode故障 | NameNode通过心跳检测识别失效节点,触发副本复制(从其他副本重新复制数据块)。 |
| NameNode故障 | Secondary NameNode定期合并EditLog和FsImage,减少主节点重启时的加载时间。 |
| 数据块损坏 | 每个数据块附带校验和(Checksum),读取时验证完整性,损坏则从其他副本恢复。 |
高可用(HA)方案:
- 采用双NameNode集群(Active/Standby模式),通过ZooKeeper协调状态切换。
- JournalNode共享日志,确保主备节点元数据一致。
读写流程详解
写入流程:
- Client向NameNode请求创建文件,获取第一个Block的存储节点列表。
- 按顺序将数据流式传输至DataNode,每个块完成后通知NameNode。
- 重复上述步骤直至文件写入完成。
读取流程:
- Client向NameNode查询文件元数据,获取Block位置信息。
- 直接从最近的DataNode读取数据块,并行下载提升效率。
读写性能优化:
- 数据本地性:优先从客户端所在节点或同机架节点读取数据。
- 短路读取:若Client与DataNode同节点,直接绕过网络传输。
与传统分布式存储对比
| 特性 | HDFS | 传统分布式存储(如Ceph/GFS) |
|---|---|---|
| 场景适配 | 批量数据处理、流式读写 | 混合负载(支持随机访问) |
| 元数据管理 | 单NameNode(潜在瓶颈) | 多节点元数据集群(如Ceph) |
| 扩展性 | 横向扩展DataNode,纵向受限于NameNode | 全对称扩展(无单点瓶颈) |
典型应用场景
- 大数据分析:支撑MapReduce作业的输入输出。
- 日志归档:高吞吐量写入,长期存储海量日志。
- 冷数据存储:低成本硬件存储低频访问数据。
FAQs
Q1:NameNode是否为单点故障?如何实现高可用?
A1:默认情况下,NameNode是单点故障,可通过部署HA集群(Active/Standby双节点+JournalNode)实现高可用,ZooKeeper协调主备切换,确保元数据服务持续可用。
Q2:HDFS如何处理小文件存储问题?
A2:小文件会占用过多元数据资源(每个文件对应一个Inode),解决方案包括:
- 合并小文件为大文件(如Hadoop的CombineFileInputFormat)。
- 使用HFile等序列化格式存储小文件元数据。
- 采用对象存储(如Amazon S3)替代HD