上一篇
hive数据库和oracle
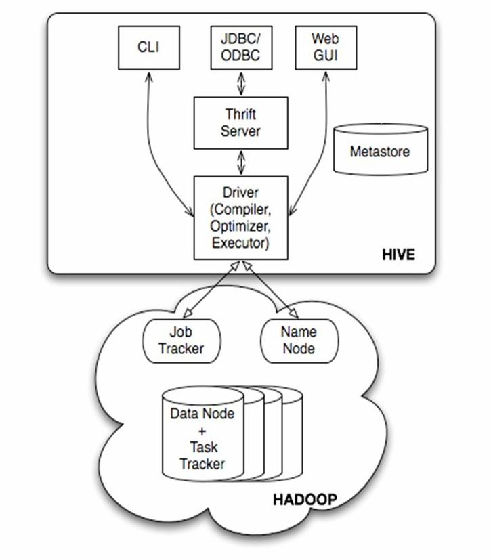
Hive为非关系型数据库,基于Hadoop,支持SQL-like查询,适合大数据分析;Oracle是关系型数据库,支持ACID事务,适用于高并发、复杂业务场景,两者在数据模型、扩展性及实时
架构设计对比
| 特性 | Hive | Oracle |
|---|---|---|
| 底层存储 | 依赖HDFS(Hadoop分布式文件系统) | 自有存储引擎(如Exadata) |
| 计算模型 | 基于MapReduce或Tez的批处理 | 基于行存储的OLTP(在线事务处理) |
| 扩展性 | 横向扩展(增加节点即可提升容量与算力) | 纵向扩展(依赖单机性能,扩展成本高) |
| 数据更新机制 | 写时复制(Append-Only),支持ACID(需开启事务) | 实时更新,支持完整ACID事务 |
| 部署模式 | 通常部署在Hadoop集群中 | 独立部署或集群化部署 |
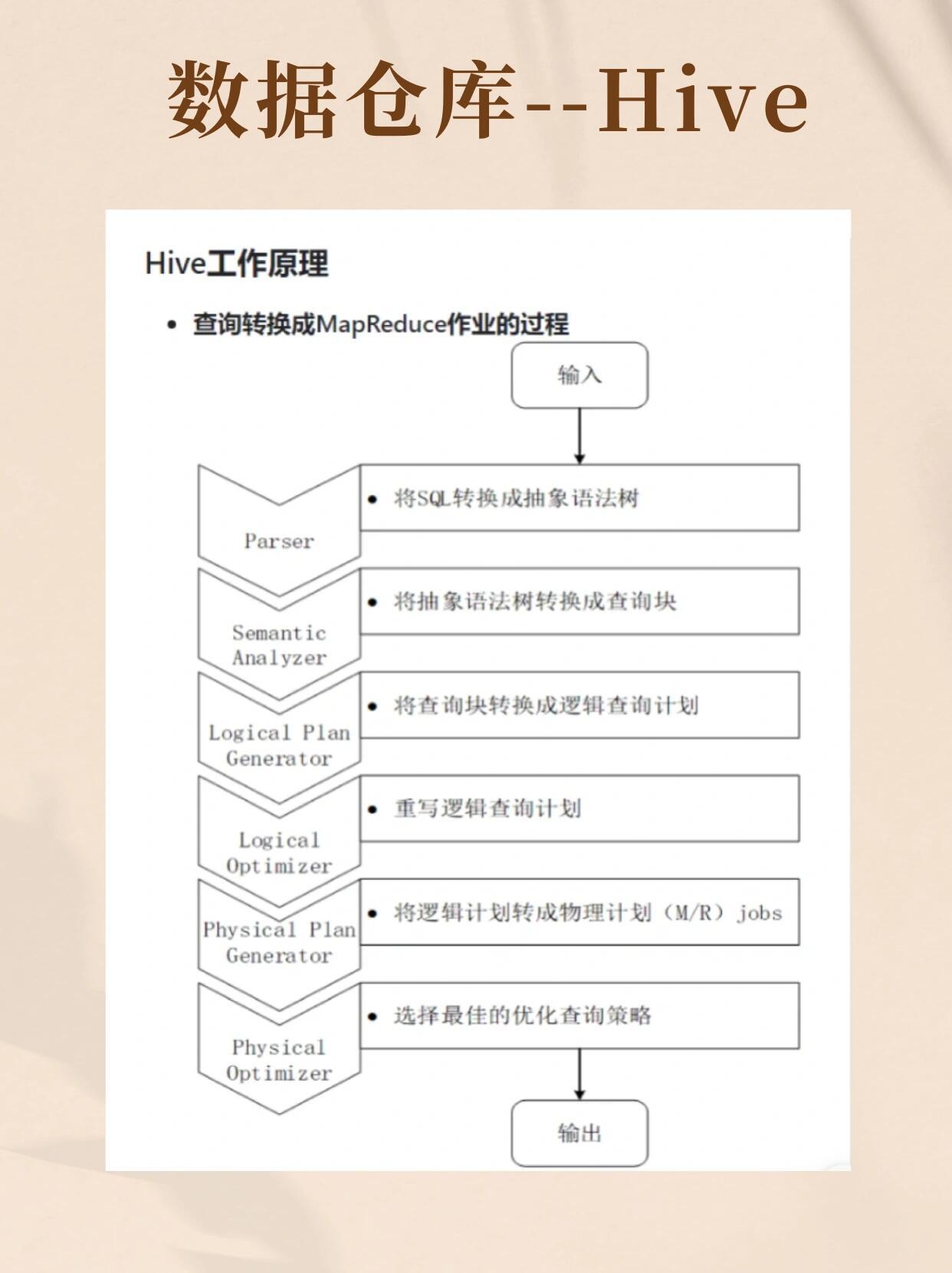
Hive 的架构以“一次编写,到处运行”为理念,通过将SQL语句转换为MapReduce任务,实现对HDFS上大规模数据的离线分析,其优势在于处理PB级数据时的低成本和高吞吐量,但实时性较差。
Oracle 则采用传统的B+树索引结构和MVCC(多版本并发控制)机制,专注于高并发事务处理和低延迟查询,适合金融、电商等对数据一致性要求极高的场景。

数据模型与存储差异
数据模型
- Hive:
- 基于关系型模型,支持表、分区、桶等概念,但弱化了主键、外键等约束。
- 数据以文本(如CSV、JSON)或二进制格式(如ORC、Parquet)存储,适合非结构化/半结构化数据处理。
- Oracle:
- 严格的关系型模型,支持主键、外键、触发器、视图等完整约束体系。
- 数据以行格式存储,支持BLOB、CLOB等复杂数据类型,适合结构化数据管理。
存储优化
- Hive:
- 通过ORC/Parquet列式存储减少I/O开销,支持压缩(如Snappy)、分区裁剪(Partition Pruning)等优化。
- 数据倾斜时需手动调整分区或桶策略。
- Oracle:
- 通过索引(如B+树、位图索引)加速查询,支持表分区(Range、Hash等)。
- 自动优化存储(如段合并、碎片整理),但维护成本较高。
查询语言与性能
查询语言
- Hive:
- 使用Hive SQL(类标准SQL),支持大部分DML操作,但无事务(需开启事务表)。
- 复杂查询依赖执行计划优化(如倾斜处理、动态分区)。
- Oracle:
- 支持完整SQL语法(包括PL/SQL、存储过程),具备强大的事务管理能力。
- 通过执行计划(EXPLAIN PLAN)和优化器(CBO)自动选择最优路径。
性能表现
- Hive:
- 优势:处理超大规模数据(TB-PB级)时成本低,适合离线批处理(如日志分析、数据仓库)。
- 劣势:查询延迟高(分钟级),不适合实时交互。
- Oracle:
- 优势:毫秒级响应速度,支持高并发事务(如每秒万级写入)。
- 劣势:硬件成本高昂,横向扩展能力弱。
扩展性与成本
| 维度 | Hive | Oracle |
|---|---|---|
| 硬件成本 | 依赖廉价PC服务器集群(Hadoop生态) | 需高端服务器(如Exadata一体机) |
| 软件授权 | 开源免费(Apache License) | 商业授权费用高昂(按CPU核心或并发数计费) |
| 运维复杂度 | 依赖Hadoop生态组件(如YARN、HDFS) | 需专业DBA维护,调优门槛高 |
| 扩展方向 | 横向扩展(添加节点即可) | 纵向扩展(升级硬件或分库分表) |
Hive 的低成本和高扩展性使其成为互联网企业处理海量数据的首选,而 Oracle 的高可靠性和事务能力则在传统行业(如银行、电信)中占据主导地位。
典型应用场景
Hive适用场景
- 离线数据分析:如用户行为日志、点击流数据的ETL处理与聚合。
- 数据仓库:构建历史数据存档或报表生成系统。
- 机器学习:为模型训练提供预处理后的大规模数据集。
Oracle适用场景
- 核心业务系统:如银行交易、订单管理系统,需强一致性与低延迟。
- 实时数据服务:如库存管理、实时风控系统。
- 混合负载场景:同时支持OLTP(事务)与OLAP(分析)需求。
常见问题解答(FAQs)
Q1:如何根据业务需求选择Hive或Oracle?
A1:
- 若业务以海量离线分析为主(如日志处理、用户画像),且对实时性要求低,优先选择Hive。
- 若业务涉及高并发事务(如支付、订单)或需要实时查询(如库存同步),则选择Oracle。
- 对于混合场景(如实时数据采集+离线分析),可通过Sqoop导入数据至Hive,或使用Oracle作为源库,Hive作为分析层。
Q2:Hive与Oracle能否集成使用?
A2:
- 数据同步:通过Sqoop将Oracle数据导入Hive,或使用Oracle GoldenGate实现实时增量同步。
- 互补架构:Oracle作为OLTP系统处理核心业务,Hive作为数据湖存储历史数据,两者通过中间件(如Kafka)协同。
- 注意事项:需解决数据格式兼容性(如Oracle的CLOB vs Hive的JSON)、事务一致性(Hive仅支持最终一致性)等问题。