
上一篇
hive导入mysql
通过Sqoop连接MySQL,执行
sqoop import将数据导出至HDFS,再用 LOAD DATA语句加载至Hive表中,需配置MySQL驱动并
Hive导入MySQL数据详解
在大数据场景中,常需将传统关系型数据库(如MySQL)中的数据迁移至Hive进行分布式存储与分析,本文将从环境准备、数据导出、Hive表设计到数据加载全流程展开,并提供多种实现方案对比。
前置条件准备
| 组件 | 版本要求 | 作用说明 |
|---|---|---|
| MySQL | 7+ | 数据源数据库 |
| Hadoop | x+(含HDFS) | 分布式文件系统 |
| Hive | 1+ | 数据仓库 |
| Sqoop | 与Hadoop版本匹配 | 数据迁移工具 |
| JDBC驱动 | mysql-connector-java-8.0.xx.jar | MySQL与Hive通信依赖 |
环境配置要点:
- 将MySQL JDBC驱动包放入Hive服务器的
$HIVE_HOME/lib目录 - 在Hive执行
ADD JAR mysql-connector-java-8.0.xx.jar加载驱动 - 配置Hive连接MySQL的权限(需开放3306端口)
数据迁移方案对比
| 方案类型 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| Sqoop全量导入 | 大规模数据迁移 | 高效并行、支持增量同步 | 需预建Hive表结构 |
| CSV导出+LOAD | 小数据量/简单表结构 | 操作简单、可视化管理 | 需手动处理数据格式转换 |
| 直接查询映射 | 实时分析需求 | 低延迟、无需物理迁移 | 依赖中间件、存在性能瓶颈 |
Sqoop全量导入实现步骤
MySQL数据准备
-创建示例表
CREATE TABLE user_behavior (
id BIGINT PRIMARY KEY,
user_id VARCHAR(32),
action_time TIMESTAMP,
page_url VARCHAR(255),
停留时长 INT
) ENGINE=InnoDB;
-插入测试数据
INSERT INTO user_behavior VALUES
(1,'user_001','2023-08-01 14:00:00','/home',300),
(2,'user_002','2023-08-01 14:05:00','/cart',120);Hive目标表设计
-创建原始数据表(建议使用ORC格式)
CREATE TABLE IF NOT EXISTS user_behavior_orc (
id BIGINT,
user_id STRING,
action_time TIMESTAMP,
page_url STRING,
停留时长 INT
)
STORED AS ORC
TBLPROPERTIES ('orc.compress'='SNAPPY');Sqoop导入命令
sqoop import --connect jdbc:mysql://mysql-server:3306/test_db --username root --password mysql_pwd --table user_behavior --target-dir /user/hive/warehouse/user_behavior_orc --hive-import --hive-overwrite --split-by id --num-mappers 4 --null-string '\N' --null-non-string '\N' --columns "id,user_id,action_time,page_url,停留时长" --hive-partition-key action_date --hive-partition-value '2023-08-01'
参数解析:
--split-by:指定分片字段,影响并行度--num-mappers:设置Map任务数量(默认4)--hive-import:自动触发Hive加载--null-string:处理字符串类型空值--hive-partition-key:按日期分区存储
CSV导出+LOAD方案
MySQL数据导出
mysql -uroot -pmysql_pwd -e "SELECT FROM user_behavior;" --where="action_time >= '2023-08-01' AND action_time < '2023-08-02'" --output=/tmp/user_behavior_20230801.csv --column-names=false --line-terminator=' ' --fields-terminated-by=',' --fields-enclosed-by='"'
HDFS上传
hdfs dfs -mkdir -p /data/mysql_export/20230801 hdfs dfs -put /tmp/user_behavior_20230801.csv /data/mysql_export/20230801/
Hive加载数据
CREATE TABLE IF NOT EXISTS user_behavior_csv (
id BIGINT,
user_id STRING,
action_time TIMESTAMP,
page_url STRING,
停留时长 INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '0x0a'
STORED AS TEXTFILE;
LOAD DATA INPATH '/data/mysql_export/20230801/user_behavior_20230801.csv'
INTO TABLE user_behavior_csv;数据验证与优化
数据校验
-校验记录数 SELECT COUNT() FROM user_behavior_orc; SELECT COUNT() FROM user_behavior_csv; -校验空值 SELECT FROM user_behavior_orc WHERE user_id IS NULL;
性能优化建议
| 优化方向 | 具体措施 |
|—————|————————————————————————|
| 存储格式 | 优先使用ORC/Parquet格式,开启压缩(SNAPPY/ZLIB) |
| 分区策略 | 按业务时间(如action_date)分区,避免小文件过多 |
| 字段类型 | 保持Hive与MySQL字段类型一致(如DATETIME→TIMESTAMP,BIGINT→BIGINT) |
| 并行度 | 根据数据量调整--num-mappers,建议单节点不超过50MB/s |
| 索引优化 | 对频繁查询字段建立bitmap索引(如user_id) |
常见问题解决方案
Q1:Sqoop导入出现Access denied错误
- 原因:MySQL用户未授予远程访问权限
- 解决:
-在MySQL端执行 GRANT ALL PRIVILEGES ON test_db. TO 'root'@'%' IDENTIFIED BY 'mysql_pwd'; FLUSH PRIVILEGES;
Q2:Hive表加载后出现乱码
- 原因:字符集不匹配(MySQL默认utf8mb4,Hive默认UTF-8)
- 解决:
-修改Hive默认字符集 SET mapreduce.map.output.encoding=UTF-8; SET mapreduce.job.output.key.comparator.class=org.apache.hadoop.mapreduce.lib.map.KeyFieldBasedComparator;
最佳实践归纳
数据量分级处理:
- <10万条:CSV导出+LOAD
- 10万~1亿条:Sqoop全量导入
-
1亿条:结合增量导入(
--incremental lastmodified)
ETL流程规范:
- 先创建原始数据层(raw_data)
- 再构建清洗层(clean_data)
- 最终生成应用层(application_data)
监控机制:
- 使用
beeline验证数据完整性 - 通过
hdfs dfsck检查文件块完整性 - 配置YARN队列资源限制(mapreduce.job.queuename=etl_queue
- 使用
相关文章

如何处理MapReduce和Hive中的故障,HiveServer与HiveHCat进程问题解析?

查看hive数据库_Hive数据库导入导出

hive导入数据
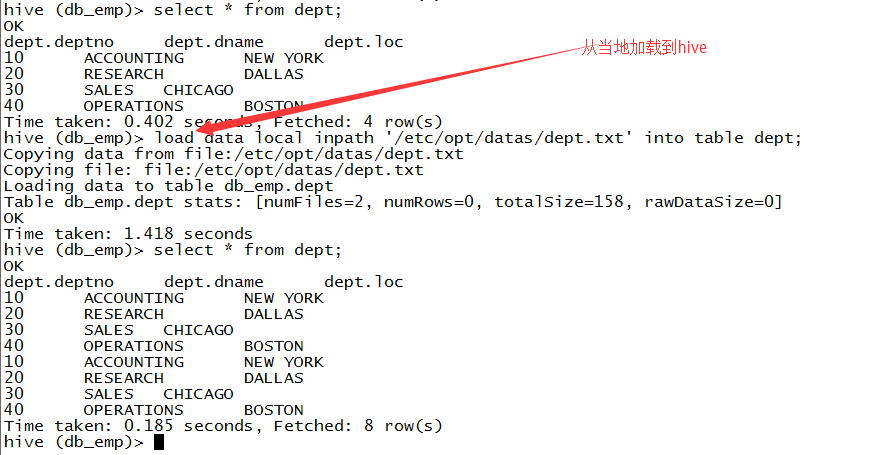
导入导出工具mysql数据库_导入导出Hive数据库

db文件导入mysql数据库_使用mysqldump迁移GaussDB(for MySQL)数据

GaussDB(for MySQL)支持哪些数据库引擎的数据导入?如何导入MySQL数据库表?
flink1.12,1.19有没有办法办法,打开sql-client即默认进入myhive呢?
如何将SQL文件导入MySQL数据库并确保其兼容MySQL模式?
pymysql连接mysql_将Spark作业结果存储在MySQL数据库中,缺少pymysql模块,如何使用python脚本访问MySQL数据库?







