上一篇
hive库建立数据库表
在Hive中创建数据库表:
CREATE DATABASE db_name; USE db_name; CREATE TABLE table_name(field1 type1, field2 type2) STORED AS ORC; 指定字段类型及
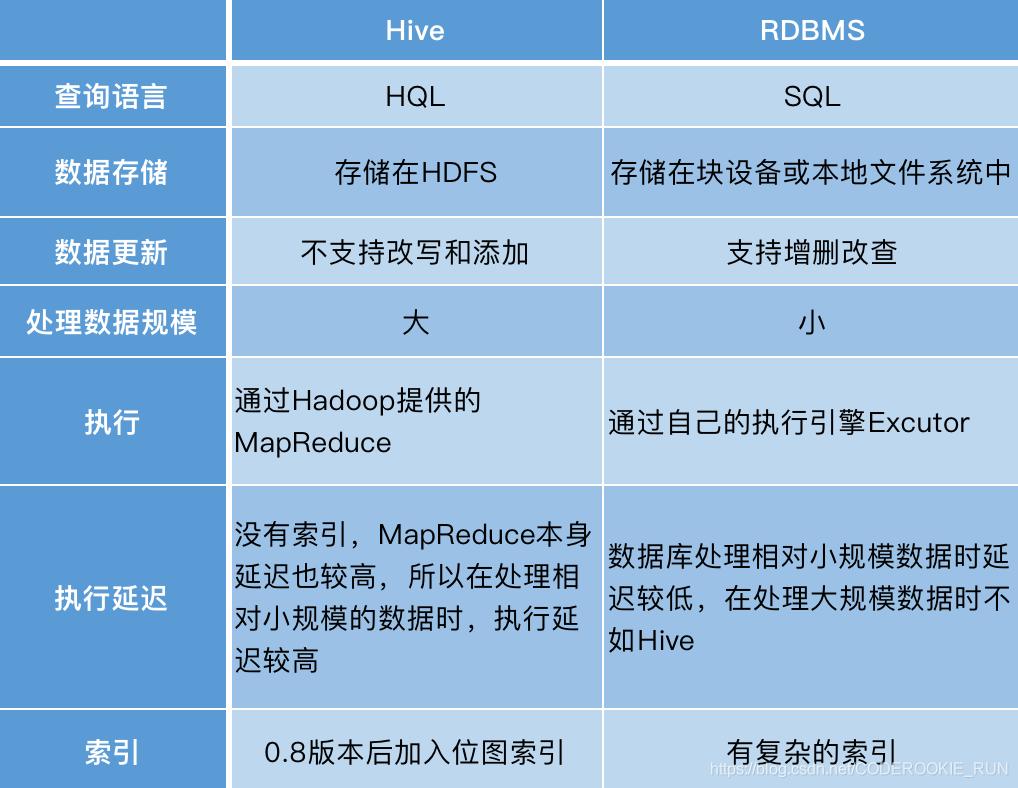
在Hive中创建数据库和表是数据仓库开发的基础操作,Hive作为基于Hadoop的数据仓库工具,支持通过DDL(数据定义语言)语句创建数据库和表结构,本文将详细讲解Hive库建立数据库表的核心步骤、关键参数及最佳实践。
Hive数据库与表基础概念
| 概念 | 说明 |
|---|---|
| 数据库 | 逻辑命名空间,用于组织和管理表对象 |
| 表 | 存储数据的结构化容器,分为内部表和外部表 |
| 字段 | 表中的列,定义数据类型(STRING/INT/DOUBLE等) |
| 分区 | 按指定字段划分数据子集,提升查询效率 |
| 桶(Bucket) | 通过哈希函数划分数据块,优化JOIN操作 |
| 存储格式 | 数据物理存储形式(TextFile/ORC/Parquet等) |
创建数据库
语法格式
CREATE DATABASE [IF NOT EXISTS] database_name [COMMENT 'description'] [LOCATION hdfs_path] [WITH DBPROPERTIES (key=value)];
关键参数说明
- IF NOT EXISTS:避免重复创建报错
- COMMENT:添加描述信息
- LOCATION:指定HDFS存储路径(非必需,默认存放在/user/username/database_name)
- DBPROPERTIES:设置数据库属性(如所有者、参数配置)
示例
CREATE DATABASE IF NOT EXISTS sales_db
COMMENT '存储销售业务数据'
LOCATION '/data/sales_db'
WITH DBPROPERTIES ('owner'='analyst_team');创建表
基本语法
CREATE TABLE [IF NOT EXISTS] table_name (
column1 data_type [COMMENT 'desc'],
column2 data_type [COMMENT 'desc'],
...
)
[PARTITIONED BY (partition_column data_type)]
[CLUSTERED BY (bucket_column) INTO num_buckets BUCKETS]
[STORED AS file_format]
[LOCATION hdfs_path]
[COMMENT 'description'];核心参数解析
| 参数 | 作用 |
|---|---|
| PARTITIONED BY | 按时间、地区等维度划分数据,提升查询效率 |
| CLUSTERED BY | 指定哈希字段,将数据分配到指定数量的桶中 |
| STORED AS | 设置存储格式(TEXTFILE/SEQUENCEFILE/ORC/PARQUET等) |
| LOCATION | 指定HDFS存储路径(内部表可省略,外部表必须指定) |
| TBLPROPERTIES | 表级属性配置(如ORC压缩格式、BloomFilter等) |
表类型对比
| 类型 | 特点 |
|---|---|
| 内部表 | 数据存储在Hive默认目录,删除表时数据会被删除 |
| 外部表 | 数据存储在自定义HDFS路径,删除表时保留数据 |
| 分区表 | 按业务维度划分子目录,适合大规模数据处理 |
| 桶表 | 通过哈希分配数据块,优化抽样查询和JOIN操作 |
| 临时表 | 使用CREATE TEMPORARY TABLE创建,会话结束后自动删除 |
完整示例
场景:创建销售明细分区表(按日期分区)和订单事实表(带桶)
-创建分区表(内部表)
CREATE TABLE sales_detail (
id BIGINT,
product_id STRING,
amount DOUBLE,
sale_date DATE
)
PARTITIONED BY (dt STRING) -按天分区
STORED AS ORC
TBLPROPERTIES ('orc.compress'='SNAPPY');
-创建外部桶表
CREATE EXTERNAL TABLE order_fact (
order_id BIGINT,
user_id STRING,
order_time TIMESTAMP
)
CLUSTERED BY (user_id) INTO 10 BUCKETS
STORED AS PARQUET
LOCATION '/external/order_data/';字段设计规范
数据类型选择:
- 字符串:
STRING(VARCHAR(255)等效) - 数字:
INT(32位整数)、BIGINT(64位)、DOUBLE(浮点数) - 时间:
TIMESTAMP(精确到毫秒)、DATE(年月日) - 布尔值:
BOOLEAN
- 字符串:
字段约束:

- Hive不支持主键/外键,需通过应用层保证数据质量
- 建议添加
NULL标注(如INT NULL)
注释规范:
created_at TIMESTAMP COMMENT '记录创建时间', region STRING COMMENT '客户所在区域'
分区与桶策略
| 特性 | 分区表 | 桶表 |
|---|---|---|
| 适用场景 | 粗粒度数据划分(如日期、地区) | 细粒度哈希分布(如用户ID) |
| 查询效率 | 减少全表扫描范围 | 加速等值查询和JOIN |
| 维护成本 | 动态添加分区 | 固定数量桶,需重建 |
| 典型SQL | WHERE dt='2023-10-01' | CLUSTERED BY user_hash |
最佳实践:
- 分区字段需高频出现在
WHERE子句 - 桶数量根据数据规模设定(通常10-100个)
- 组合使用分区+桶(如先按日期分区,再按用户ID分桶)
存储格式选择
| 格式 | 特点 |
|---|---|
| TextFile | 简单易用,但无压缩和索引,适合小规模数据 |
| ORC | 列式存储,支持压缩(SNAPPY/ZLIB)、索引,适合OLAP分析 |
| Parquet | 列式+嵌套结构支持,与ORC性能相当,生态兼容性更好 |
| Avro | 支持Schema演化,适合日志类半结构化数据 |
推荐配置:
STORED AS ORC
TBLPROPERTIES (
'orc.compress'='SNAPPY', -压缩算法
'orc.bloom.filter.columns'='product_id,sale_date', -布隆过滤优化
'orc.create.index'='true' -创建索引文件
);权限管理
授权语法:
GRANT [SELECT|INSERT|UPDATE|DELETE] ON TABLE table_name TO USER/ROLE;
示例:
GRANT ALL ON TABLE sales_detail TO ROLE analyst_team; -赋予角色所有权限 REVOKE INSERT ON TABLE order_fact FROM USER john; -收回插入权限
FAQs
Q1:内部表和外部表删除时有什么区别?
A:删除内部表(DROP TABLE)会同时删除元数据和HDFS中的数据文件;删除外部表仅删除元数据,保留原始数据,建议生产环境优先使用外部表。
Q2:如何选择ORC和Parquet格式?
A:两者性能相近,主要差异在生态支持:ORC是Hive原生优化格式,Parquet在Spark/Impala等引擎中兼容性更好,若需跨计算引擎使用,推荐Parquet;若专注Hive场景,优先OR