上一篇
having在mysql的作用
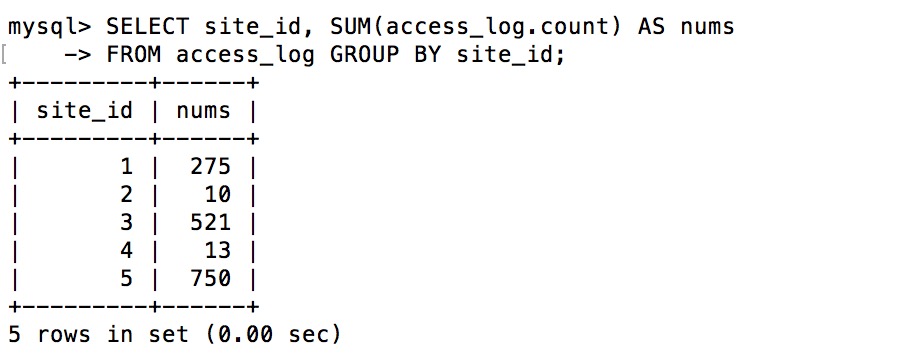
HAVING在MySQL中用于分组后筛选,针对聚合结果过滤,常与GROUP BY
MySQL中HAVING的作用详解
基本概念
HAVING 是SQL语句中用于对分组后的数据进行条件过滤的关键字,它通常与 GROUP BY 子句配合使用,允许用户根据聚合函数的结果(如 COUNT、SUM、AVG 等)对数据进行筛选,与 WHERE 子句不同,HAVING 作用于分组后的结果集,而非原始数据。
HAVING与WHERE的区别
| 特性 | WHERE | HAVING |
|---|---|---|
| 作用对象 | 原始表中的每一行数据 | 分组后的组数据 |
| 执行顺序 | 在 GROUP BY 之前执行 | 在 GROUP BY 之后执行 |
| 可用函数 | 不支持聚合函数(如 COUNT) | 支持聚合函数 |
| 典型用途 | 过滤原始数据行 | 过滤分组后的数据 |
| 语法位置 | 在 FROM 和 GROUP BY 之间 | 在 GROUP BY 和 ORDER BY 之间 |
示例对比:
假设有一个员工表 employees,包含字段 department(部门)、salary(薪资)。
- 需求1:筛选出部门为 “IT” 的员工。
SELECT FROM employees WHERE department = 'IT';
- 需求2:筛选出部门平均薪资超过 5000 的部门。
SELECT department, AVG(salary) FROM employees GROUP BY department HAVING AVG(salary) > 5000;
语法结构与执行顺序
HAVING 的典型语法位置如下:
SELECT [列名] FROM [表名] WHERE [条件] -过滤原始数据 GROUP BY [列名] -按列分组 HAVING [条件] -过滤分组后的数据 ORDER BY [列名]; -排序结果
执行流程:

FROM指定数据源。WHERE过滤原始行。GROUP BY对剩余行分组。HAVING过滤分组后的数据。ORDER BY对最终结果排序。
核心使用场景
基于聚合函数的筛选
当需要根据分组统计结果(如总和、平均值等)进行过滤时,必须使用HAVING。
示例:查询订单表中总金额超过 1000 的客户。SELECT customer_id, SUM(order_amount) FROM orders GROUP BY customer_id HAVING SUM(order_amount) > 1000;
动态条件过滤
结合参数或子查询,实现灵活的分组过滤。
示例:筛选出销售额高于全体平均水平的部门。SELECT department, SUM(sales) FROM sales_data GROUP BY department HAVING SUM(sales) > (SELECT AVG(total_sales) FROM sales_data);
统计排名
通过HAVING结合聚合函数,实现分组数据的排名逻辑。
示例:查询库存量排名前三的商品类别。SELECT category, SUM(stock) AS total_stock FROM products GROUP BY category HAVING total_stock >= ( SELECT total_stock FROM ( SELECT SUM(stock) AS total_stock FROM products GROUP BY category ORDER BY total_stock DESC LIMIT 2,1 ) AS temp );
注意事项
非聚合列的限制
在HAVING子句中,若使用非聚合列,需确保该列在GROUP BY中声明,否则会导致语法错误。
错误示例:SELECT department, AVG(salary) FROM employees GROUP BY department HAVING salary > 5000; -错误:salary未在GROUP BY中
性能优化
HAVING会对分组后的所有数据进行扫描,因此大数据量时可能影响性能,建议结合WHERE预先过滤数据。- 避免在
HAVING中使用复杂计算,可考虑将部分逻辑转移到应用层处理。
与别名的兼容性
在HAVING中可以直接使用SELECT列表中的别名,但需注意不同数据库的兼容性。SELECT department, AVG(salary) AS avg_salary FROM employees GROUP BY department HAVING avg_salary > 5000; -MySQL支持,但部分数据库可能不兼容
相关问答FAQs
问题1:HAVING 和 WHERE 可以同时使用吗?
解答:可以。WHERE 用于过滤原始数据行,HAVING 用于过滤分组后的数据。
SELECT department, COUNT() FROM employees WHERE status = 'active' -过滤原始数据 GROUP BY department HAVING COUNT() > 10; -过滤分组结果
问题2:HAVING 是否支持使用聚合函数?
解答:支持。HAVING 的核心作用就是基于聚合函数的结果进行过滤。
SELECT category, SUM(quantity) FROM sales GROUP BY category HAVING SUM(quantity) > 100; -根据聚合结果