上一篇
hbase主流数据库
HBase是基于HDFS的分布式列式数据库,支持海量数据实时读写,具备高扩展性与可靠性,广泛应用于大数据存储场景
HBase主流数据库技术解析与应用场景分析
HBase技术
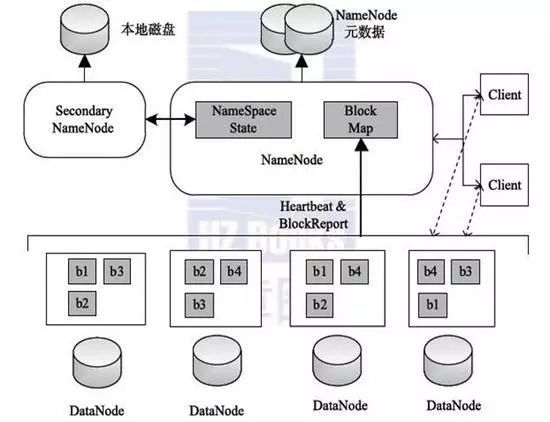
HBase是基于Hadoop生态体系的分布式NoSQL数据库,由Apache基金会维护,属于列式存储数据库,其设计目标是为大规模数据提供随机读写能力,支持每秒百万级的数据操作,尤其适合处理非结构化或半结构化数据,作为BigTable的开源实现,HBase通过HDFS实现底层存储,依赖ZooKeeper进行分布式协调,采用Master-Slave架构保障高可用性。
核心架构解析
| 组件名称 | 功能描述 |
|---|---|
| HMaster | 集群管理核心,负责元数据管理(表结构、Region分配)、权限控制、负载均衡 |
| RegionServer | 数据存储与检索节点,管理多个Region(数据分片),处理客户端读写请求 |
| ZooKeeper | 分布式协调服务,监控RegionServer状态,保证元数据一致性 |
| HDFS | 底层存储系统,提供可靠数据持久化支持 |
| WAL(预写日志) | 记录数据变更操作,确保故障恢复能力 |
| MemStore | 内存缓存区,临时存储写入数据,定期刷新到HDFS |
| HFile | 持久化存储文件,按KeyValue格式组织数据 |
数据流动路径:客户端请求→ZooKeeper路由→RegionServer处理→MemStore缓存+WAL记录→触发Flush写入HDFS。
关键特性对比
| 特性维度 | HBase | 传统关系型数据库(如MySQL) | 文档型数据库(如MongoDB) |
|---|---|---|---|
| 数据模型 | 列族式存储,稀疏列支持 | 行列严格对应 | JSON文档嵌套结构 |
| 扩展性 | 水平扩展,动态添加RegionServer | 垂直扩展为主 | 水平分片(Sharding) |
| 事务支持 | 单行ACID事务(受限于HBase 2.0+的MVCC机制) | 完整ACID支持 | 仅文档级原子性 |
| 查询语言 | 基于Java API,支持Filter/Scanner自定义查询 | SQL标准 | MQL(MongoDB Query Language) |
| 时延表现 | 毫秒级随机读写(SSD介质下P99<10ms) | 毫秒级(小数据量) | 毫秒级(索引优化后) |
| 存储成本 | 中等(HDFS存储+多副本机制) | 较高(B+Tree索引开销) | 较低(文档压缩优化) |
典型应用场景
实时数据分析
- 场景特征:海量事件流数据(如物联网传感器数据)、低延迟查询需求
- 技术优势:LSM树结构优化写性能,支持RowKey范围扫描
- 案例:电商实时交易监控、社交网络feeds存储
用户画像系统

- 场景特征:动态更新的用户属性标签、多维度组合查询
- 技术优势:列族独立存储,冷热数据分层管理
- 实践方案:将基础属性(姓名/年龄)与行为标签(浏览/购买)分离存储
历史数据归档
- 场景特征:PB级日志数据长期存储、按需检索
- 技术优势:与HDFS深度集成,支持时间戳范围查询
- 优化策略:设置合理的TTL(Time To Live)自动清理过期数据
版本演进与生态工具
| 版本阶段 | 关键改进 |
|---|---|
| 98之前 | 依赖Hadoop MapReduce进行批量操作,事务支持缺失 |
| x系列 | 引入MVCC实现ACID事务,增加BulkLoad优化批量导入 |
| x系列 | 支持异步RPC提升吞吐量,集成 Phoenix 提供SQL层访问能力 |
| x系列 | 增强二级索引能力,优化Region拆分算法 |
| x系列 | 原生支持容器化部署(Kubernetes),改进Schema变更流程 |
生态工具链:
- Phoenix:提供SQL接口,支持二级索引和事务
- HBase-Spark-Connector:实现Spark计算框架与HBase无缝对接
- HappyBase:Python语言驱动库,简化开发复杂度
- Atlas DB:Facebook基于HBase的优化分支,提升写密集型场景性能
性能优化实践
Schema设计原则
- 列族数量≤3(避免过多列族导致MemStore压力)
- 合理设置RowKey(建议MD5哈希+时间戳组合)
- 版本控制:设置Max Version=1减少存储冗余
硬件配置策略
| 组件 | CPU配置建议 | 内存分配规则 | 磁盘选型 |
|————–|——————-|—————————|——————-|
| HMaster | 4核+8GB内存 | JVM Heap≤6GB | SSD(元数据存储) |
| RegionServer | 16核+128GB内存 | Heap=80GB,MemStore=32GB | SAS HDD(数据存储)|JVM调优参数
-XX:+UseG1GC:启用G1垃圾回收器hbase.rpc.threads=300:提升并发处理能力hbase.client.retries.number=5:重试机制配置
常见问题与解决方案
问题1:写入性能突然下降
- 根因分析:MemStore刷写阻塞、Region热点倾斜、HDFS NameNode瓶颈
- 解决路径:
- 检查
hbase(regionserver).hfilecleaner.plugin配置 - 使用
hbase shell "alter 'table', {METHOD => 'table_att r=10'}"调整读写比例 - 开启
hbase.balancer.enabled=true自动负载均衡
- 检查
问题2:读取延迟不稳定
- 优化手段:
- BlockCache命中率提升:增大
hbase.blockcache.size至物理内存的40% - BloomFilter配置:启用
ROWCOLUMNFIRST策略减少无效IO - Compaction优化:设置
hbase.store.time_to_wait=60000避免频繁合并
- BlockCache命中率提升:增大
技术选型对比决策树
graph TD
A[业务需求] --> B{数据特征}
B -->|结构化为主| C[选择MySQL]
B -->|高并发写| D[选择Kafka+HBase]
B -->|复杂查询| E[选择Elasticsearch]
B -->|海量时序数据| F[选择InfluxDB]
B -->|混合型数据| G[选择HBase+Phoenix]
D --> H[需要事务] --> I[启用HBase WAL]
G --> J[需要SQL] --> K[集成Phoenix]FAQs
Q1:HBase与Cassandra的核心区别是什么?
A:两者均属分布式NoSQL,但HBase更适合写密集型场景:
- HBase强依赖HDFS生态,天然支持Hadoop体系;Cassandra可跨数据中心部署
- HBase采用集中式Meta表管理,Cassandra使用去中心化的gossip协议
- HBase提供行级事务,Cassandra仅支持最终一致性
- HBase适合实时计算场景,Cassandra更侧重互联网级广域网部署
Q2:如何判断业务是否适合使用HBase?
A:需满足以下特征中的至少3项:
- 单表数据量超过TB级且持续增长
- 读写操作具有明显的时间局部性(如最近数据高频访问)
- 需要支持复杂的条件过滤(如多列组合查询)
- 存在大量稀疏数据(如用户行为标签)
- 对