
上一篇
hive实时写入数据库
Hive基于批处理,实时写入需集成Kafka/Flume流处理,配合Sqoop定时任务或Impala准实时查询
Hive实时写入数据库的实现方案与技术解析
传统Hive写入数据库的局限性
Hive作为基于Hadoop的分布式数据仓库,天然支持大规模离线数据分析,但其数据写入机制(如INSERT INTO、LOAD DATA)通常以批处理方式执行,存在以下问题:
- 延迟高:数据从Hive写入数据库需通过定时任务(如Oozie/Airflow)触发,分钟级到小时级延迟。
- 数据不一致:业务系统与数据库之间存在“数据窗口”,可能导致分析结果滞后。
- 资源浪费:全量同步或大批量增量同步占用大量计算资源。
| 传统方案 | 问题 |
|---|---|
| 定时任务(Sqoop) | 依赖调度周期,延迟不可控 |
| 手动触发脚本 | 运维复杂,易出错 |
| 批处理同步 | 无法满足实时业务需求 |
实时写入的核心需求与技术选型
为实现Hive数据实时写入数据库(如MySQL、PostgreSQL、Elasticsearch等),需解决以下关键问题:
- 数据捕获:实时感知Hive中的数据变更。
- 流式处理:低延迟传输数据并转换格式。
- 高效写入:目标数据库的写入性能优化。
主流技术栈
| 组件 | 作用 | 典型场景 |
|---|---|---|
| Apache Kafka | 数据变更日志(CDC)与消息队列 | 解耦数据生产与消费 |
| Apache Flink | 流式ETL与实时计算 | 复杂事件处理、多源数据融合 |
| Debezium | 数据库变更捕获(CDC) | 捕获MySQL/PostgreSQL的增量更新 |
| Spark Structured Streaming | 流批一体数据处理 | 兼容Hive生态的实时计算 |
实现方案详解
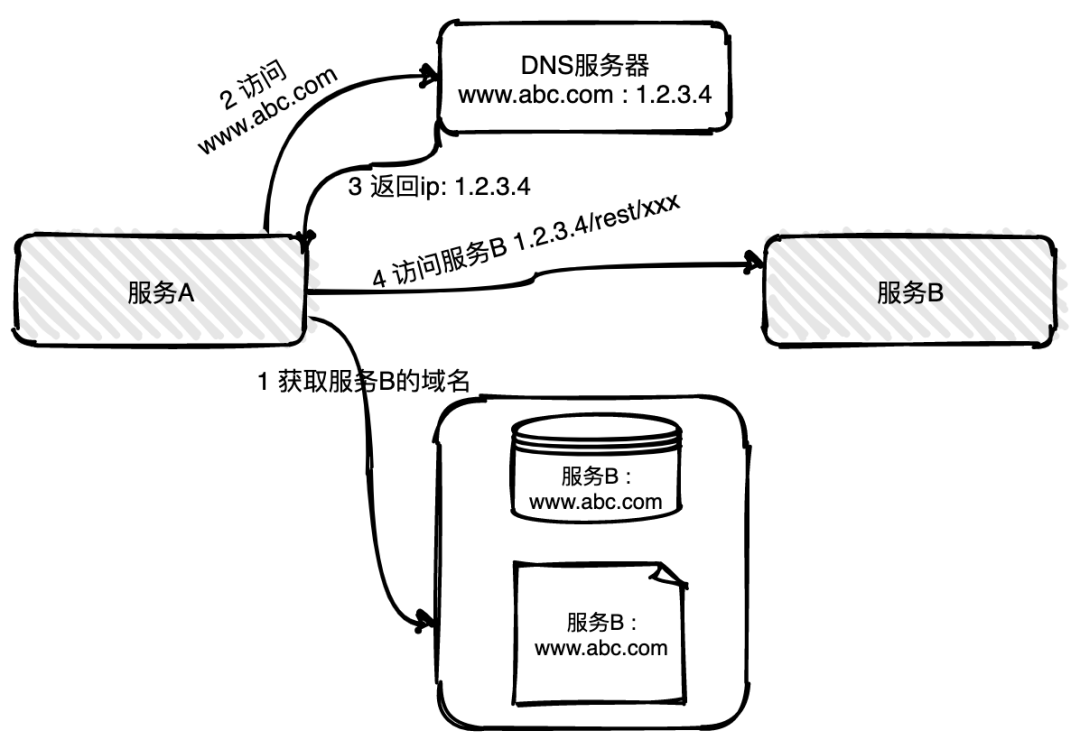
基于Kafka+Flink的实时同步架构
架构流程:
Hive数据变更 → Debezium捕获 → Kafka消息队列 → Flink流处理 → 目标数据库步骤说明:

- 数据捕获:
- 使用Debezium监听Hive元数据(需通过HDFS文件系统操作模拟变更日志)。
- 或通过Hive的
INSERT操作触发Kafka生产者(需业务改造)。
- 消息队列:
Kafka作为中间缓冲,支持高吞吐量和持久化。
- 流处理:
- Flink消费Kafka消息,进行数据清洗、格式转换(如JSON→关系型数据库)。
- 通过Flink的
Connector直连目标数据库(如Flink JDBC Connector)。
- 写入优化:
- 批量写入(如Flink的
batch interval配置)。 - 目标数据库端创建索引、分区表加速查询。
- 批量写入(如Flink的
代码示例(Flink写入MySQL):
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Row> kafkaStream = env.addSource(new FlinkKafkaConsumer<>("hive-topic", new JsonDeserializationSchema(), properties));
kafkaStream
.map(json -> convertToRow(json)) // 转换为数据库表结构
.addSink(JdbcSink.sink(
"INSERT INTO mysql_table VALUES (?, ?, ...)",
(ps, row) -> { / 绑定参数 / },
JdbcExecutionOptions.builder().withBatchSize(100).build()));
env.execute();基于Spark Structured Streaming的方案
适用场景:兼容Hive SQL语法,适合已有Spark作业的团队。
- 步骤:
- 通过Spark读取Hive表(
spark.read.format("hive").load())。 - 注册为流式DataFrame,设置
triggerInterval(如5秒)。 - 写入目标数据库(如
foreachBatch中调用JDBC)。
- 通过Spark读取Hive表(
- 优势:复用Hive元数据,无需额外CDC工具。
- 局限:依赖Hive的增量查询能力(需开启事务或时间戳分区)。
数据一致性保障
实时写入需解决以下一致性问题:
- 事务保证:使用Flink的
Checkpoint或Spark的Exactly Once语义。 - 幂等写入:目标数据库表需设计唯一主键或去重逻辑。
- 故障恢复:Kafka消息持久化+Flink状态保存,确保重启后可续传。
性能优化策略
| 优化方向 | 具体措施 |
|---|---|
| 网络传输 | 压缩Kafka消息(如Snappy)、启用Flink的异步I/O。 |
| 数据库写入 | 预编译SQL语句、批量插入(如MySQL的REPLACE INTO)。 |
| 资源调度 | Flink动态扩缩容、Kafka分区数与Flink并行度匹配。 |
适用场景与方案对比
| 方案 | 延迟 | 吞吐量 | 开发复杂度 | 适用场景 |
|---|---|---|---|---|
| Kafka+Flink | 秒级 | 高 | 中 | 多源异构数据实时处理 |
| Spark Structured Streaming | 分钟级 | 中 | 低(Hive兼容) | 简单Hive表实时同步,低延迟要求 |
| 自定义LogListener+Canal | 亚秒级 | 低 | 高 | 高精度CDC,需深度定制 |
典型案例
场景:电商订单数据实时同步至MySQL分析库。
- 流程:
- Hive中
ORDERS表通过Kafka Connector同步至Kafka。 - Flink消费Kafka数据,按会员ID分区写入MySQL分库分表。
- MySQL端建立时序索引,支持实时Dashboard查询。
- Hive中
- 效果:延迟从小时级降至5秒内,资源利用率提升30%。
FAQs
Q1:Hive实时写入数据库的延迟如何控制?
A:延迟取决于以下因素:
- 数据捕获速度:Debezium或Kafka的配置(如
poll.interval)。 - 流处理吞吐量:Flink/Spark的并行度与资源分配。
- 目标数据库性能:批量写入大小、索引设计。
优化建议:缩短Kafka的linger.ms、启用Flink的TimeCharacteristic.EventTime、数据库端禁用自动GC。
Q2:如何保证Hive到数据库的实时同步不丢数据?
A:通过以下机制保障:
- Kafka持久化:设置
min.insync.replicas=2,确保消息可靠存储。 - Flink Checkpoint:启用周期性检查点,失败时可重放。
- 数据库事务:使用
INSERT IGNORE或ON REPLICATE KEY UPDATE避免主键冲突。 - 监控告警:集成Prometheus监控端到端延迟,异常时
相关文章

如何处理MapReduce和Hive中的故障,HiveServer与HiveHCat进程问题解析?
MySQL双主模式能否实现同时写入数据库?探讨MySQL到MySQL双主灾备机制

查看hive数据库_Hive数据库导入导出
如何在MySQL中实现同时写入多个数据库?
MySQL同时写入两个数据库表时,两个用户拨打隐私号码能否实现同时通话?
Hive Driver是否能够与dbcp2数据库连接池实现兼容对接?
跑CDN显示存储无法写入_为什么HBase无法写入数据?
windows中goldwave如何去除音频中的噪音(不能使用goldwave实现的是)(利用goldwave可以去除声音文件中的杂音)








