上一篇
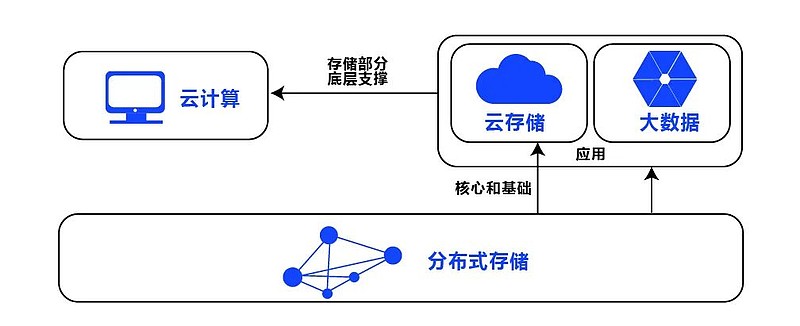
分布式智能存储
分布式智能存储通过数据分片、冗余备份及自修复机制,实现高可用、高扩展与低成本的优势,应用于
技术原理、架构与应用场景深度解析
分布式智能存储的定义与核心特征
分布式智能存储是一种通过软件定义、多节点协同工作的存储系统,其核心目标是实现数据的高效管理、容错能力和弹性扩展,与传统集中式存储相比,它具备以下关键特征:
| 特征 | 传统存储 | 分布式智能存储 |
|---|---|---|
| 架构模式 | 单点部署,性能瓶颈明显 | 多节点并行,无单点故障 |
| 扩展性 | 纵向扩展(硬件升级) | 横向扩展(添加节点) |
| 数据冗余 | RAID阵列依赖本地硬盘 | 全局数据复制(如副本、纠删码) |
| 智能化能力 | 手动配置为主 | 自动负载均衡、故障恢复 |
| 成本模型 | 高端硬件投入高 | 通用服务器+软件定义 |
技术架构解析
节点类型与角色分配
- 存储节点:负责物理数据存储,采用标准x86服务器或专用存储设备。
- 元数据节点:管理文件系统的元信息(如目录结构、权限),通常采用多副本或Paxos协议保障高可用。
- 协调节点:负责集群状态管理(如ZooKeeper),处理节点加入/退出、负载均衡。
数据分布策略
- 哈希分片:通过一致性哈希算法将数据均匀分布到不同节点,避免热点问题。
- 副本机制:每份数据保存多个副本(如3副本),典型应用于Amazon S3。
- 纠删码:将数据分割为多个块并生成冗余校验码,存储效率比副本更高(如HDFS的EC模式)。
一致性模型

- 强一致性:通过分布式锁或共识算法(如Raft)保证数据更新同步,适用于金融交易场景。
- 最终一致性:允许短暂数据延迟,适合社交媒体、日志存储等场景。
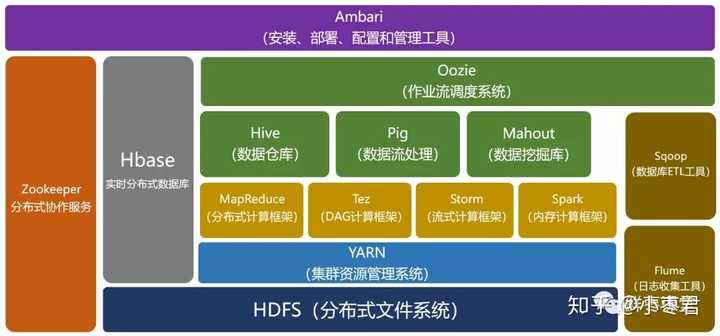
核心技术组件
分布式文件系统
- Ceph:基于CRUSH算法实现数据分布,支持对象、块、文件存储统一接口。
- GlusterFS:通过分布式哈希表(DHT)管理文件分片,适合海量小文件场景。
智能调度与优化
- 动态负载均衡:根据节点负载(CPU、磁盘IO)实时迁移数据。
- 冷热数据分层:将高频访问数据(热数据)存储在SSD,低频数据(冷数据)迁移至HDD或云端。
容错与恢复机制
- 心跳检测:节点间定期发送心跳包,快速识别故障节点。
- 自动数据重建:故障节点恢复后,系统自动从其他节点复制缺失数据。
典型应用场景
| 场景 | 需求特点 | 技术方案 |
|---|---|---|
| 云计算基础设施 | 弹性扩展、高吞吐量 | 结合Kubernetes的持久化存储(如Rook+Ceph) |
| 大数据分析 | 低延迟读写、PB级数据处理 | Hadoop HDFS + Spark优化 |
| 人工智能训练 | 高并发小文件访问 | Alluxio缓存加速 + 分布式对象存储 |
| 边缘计算 | 低带宽、高可靠性 | 轻量级Edge-Native存储(如KubeEdge) |
优势与挑战
优势:
- 高可用性:数据副本+故障自动切换,可用性达99.999%。
- 成本优化:通过软件定义减少硬件依赖,TCO降低30%-50%。
- 弹性扩展:分钟级扩容,支持EB级容量。
挑战:
- 数据安全:多租户环境下的权限隔离(需RBAC+加密传输)。
- 技术复杂度:集群规模越大,运维难度指数级上升。
- 网络依赖:跨节点通信导致性能受网络带宽限制。
未来发展趋势
- AI驱动型存储:通过机器学习预测数据访问模式,提前预加载热点数据。
- 存算一体化:将计算任务下沉到存储节点,减少数据传输延迟。
- 绿色存储技术:采用MAID(大规模空闲磁盘阵列)降低待机能耗。
FAQs
Q1:分布式存储的数据恢复速度如何保障?
A1:通过以下技术实现快速恢复:
- 并行重建:利用多节点同时参与数据重构
- 增量校验:仅传输缺失数据块而非全量复制
- 预取策略:根据历史访问模式预加载可能损坏的副本
Q2:如何优化分布式存储的小文件读写性能?
A2:可采用以下方案:
- 元数据缓存:将文件元数据缓存到内存,减少磁盘IO
- 合并归档:定期将小文件合并为大对象(如Parquet格式)
- 分级存储:使用Mem