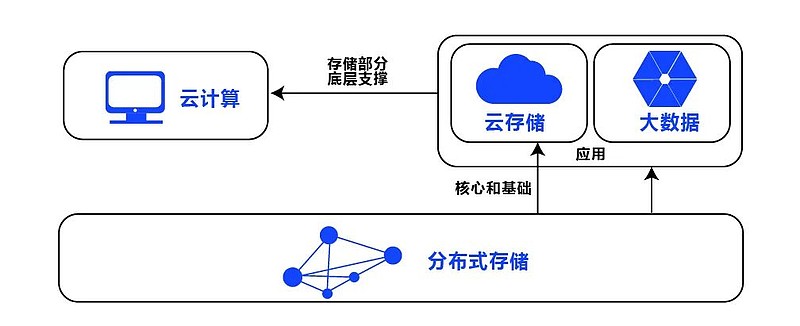
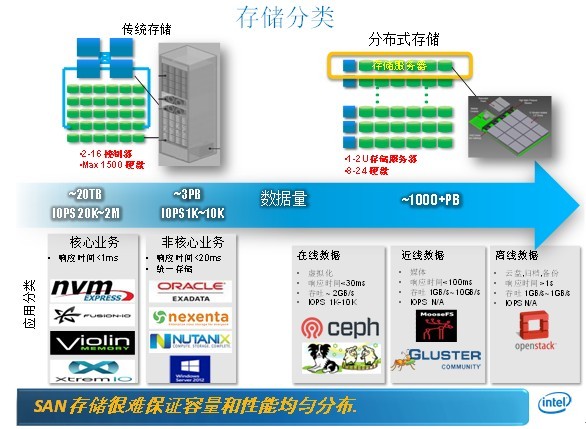
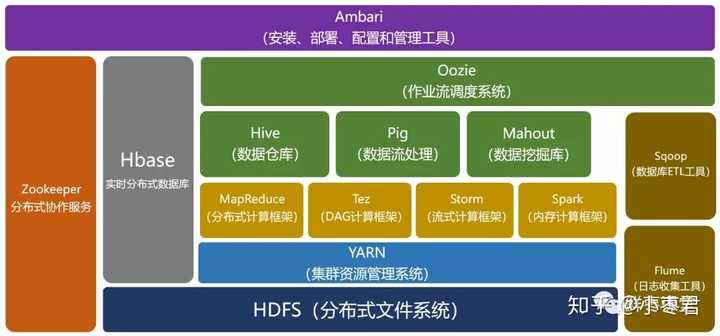
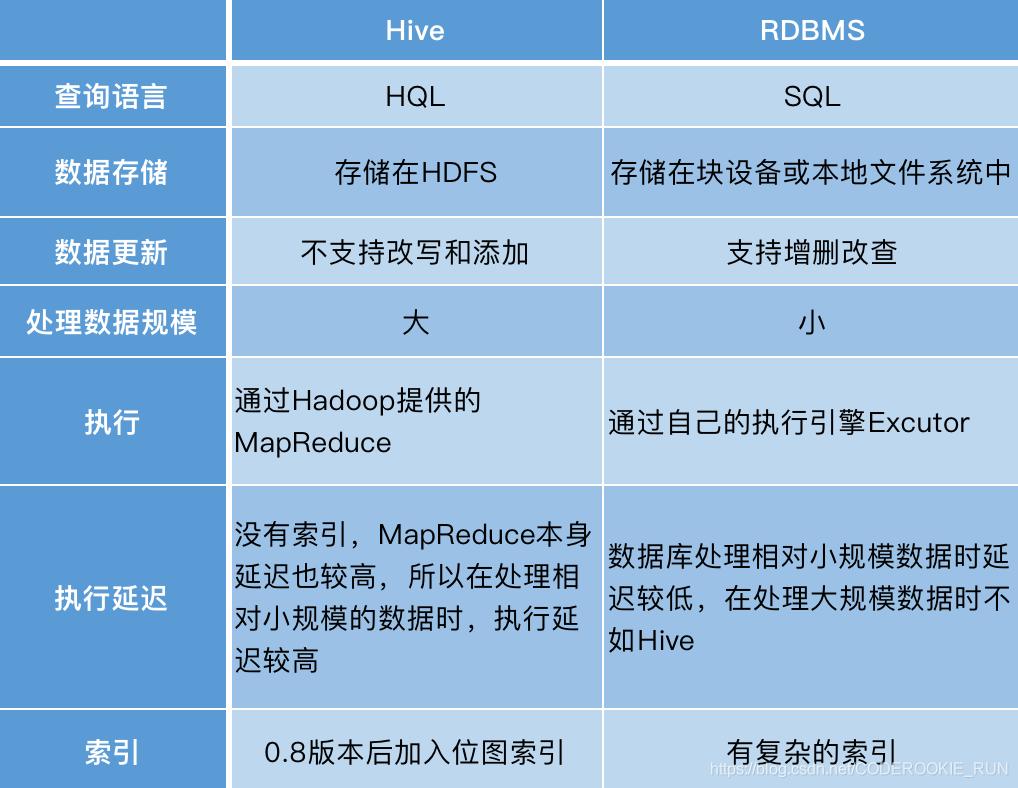
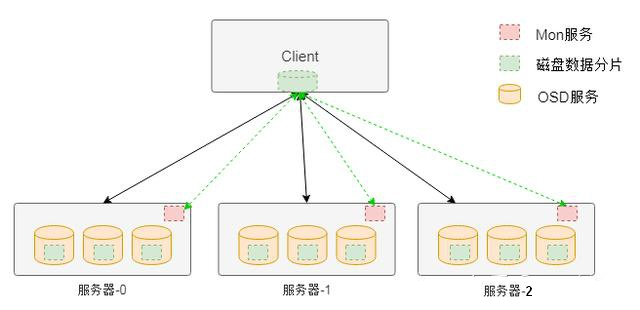
分布式存储与数据库是不同层级的技术,若仅需存储原始数据(如文件、日志),可无需 数据库;但若需结构化查询、事务管理或数据分析,则需结合数据库(如NoSQL/NewSQL)进行数据治理,两者常配合使用,存储提供底层支撑
分布式存储与数据库的关系解析
基础概念辨析
分布式存储与数据库是两种不同的技术体系,但存在功能重叠和互补性,以下是核心概念的对比:
| 维度 | 分布式存储 | 数据库 |
| 核心目标 | 大规模数据持久化存储 | 数据管理与高效查询 |
| 数据模型 | 原始二进制、对象、块 | 结构化表、文档、图等 |
| 功能特性 | 扩展性、容错性、低成本 | ACID事务、索引优化、复杂查询 |
| 典型场景 | 冷数据归档、多媒体存储、备份 | 实时交易、统计分析、业务逻辑处理 |
| 技术代表 | Ceph/MinIO(对象存储) | MySQL/PostgreSQL(关系型) |
分布式存储是否需要数据库的核心判断
是否需要数据库取决于业务需求层级,可分为以下三类场景:

无需数据库的纯存储场景
| 特征 | 示例 |
| 数据仅作为静态文件存储 | 视频平台素材库、基因组测序数据归档 |
| 无复杂查询需求 | 日志服务器、IoT设备状态快照 |
| 高吞吐量优先 | 大规模监控数据写入(>10万QPS) |
技术选择:MinIO(S3协议)、Ceph(块/对象存储)、GlusterFS(POSIX文件系统)
需要数据库的增强型场景
| 需求类型 | 数据库作用 | 技术组合示例 |
| 元数据管理 | 存储文件属性、目录结构 | Ceph + MySQL(存储池元数据) |
| 实时查询与分析 | 加速数据检索 | Elasticsearch + MinIO(日志系统) |
| 事务一致性要求 | 确保操作原子性 | TiDB + JuiceFS(订单处理系统) |
混合架构设计原则
| 层级划分 | 技术实现 | 适用场景 |
| 热数据层(高频读写) | Redis/Memcached | 实时排行榜、会话管理 |
| 温数据层(索引查询) | Elasticsearch/ClickHouse | 日志分析、用户行为搜索 |
| 冷数据层(长期存储) | HDD/SSD+分布式文件系统 | 历史订单存档、监控录像 |
关键技术对比分析
数据一致性模型
| 特性 | 分布式存储 | 数据库 |
| 一致性强度 | 最终一致性(如DynamoDB) | 强一致性(如Spanner) |
| 事务支持 | 无原生事务 | 完整ACID支持 |
| 冲突解决 | 版本控制/合并策略 | 锁机制/MVCC |
扩展性对比
| 指标 | 横向扩展 | 纵向扩展 |
| 分布式存储 | 线性扩展(增加节点即扩容) | 单节点性能瓶颈明显 |
| 数据库 | 复杂分片策略(Sharding) | 内存/CPU优化空间大 |
成本效益分析
| 成本类型 | 分布式存储 | 数据库 |
| 硬件成本 | 可使用廉价HDD/对象存储 | 依赖SSD保障性能 |
| 运维复杂度 | 自动化修复(如Erasure Code) | 需专业DBA调优 |
| 开发成本 | 简单API接口(S3/POSIX) | SQL/查询语言开发适配 |
典型实践案例
案例1:云存储服务(无需数据库)
- 架构:MinIO集群 + NGINX负载均衡
- 数据流:
- 客户端通过S3 API上传对象
- 数据分片存储在多个MinIO节点
- 元数据保存在内部Etcd集群
- 优势:零数据库依赖,TB/s级吞吐能力
案例2:电商订单系统(需数据库)
- 混合架构:
- 热数据:TiDB(分布式MySQL)处理实时交易
- 冷数据:JuiceFS(基于Redis的元数据)存储历史订单
- 关键设计:
- 事务保证:TiDB的Raft协议确保订单原子性
- 成本优化:JuiceFS使用SSD缓存加速冷数据查询
技术选型决策树
graph TD
A[业务需求] --> B{是否需要事务?}
B -->|是| C[选择分布式数据库]
B -->|否| D{是否需要复杂查询?}
D -->|是| E[增加搜索引擎]
D -->|否| F[纯分布式存储]
C --> G[评估ACID需求]
G --> H[NewSQL/传统SQL]
E --> I[Elasticsearch/Lucene]性能指标对比
| 测试场景 | Ceph(分布式存储) | CockroachDB(分布式数据库) |
| 1000节点扩展延迟 | <2s | 15s~1min(schema变更) |
| 百万QPS成本 | $0.005/千次写 | $0.15/千次事务 |
| 单表容量上限 | 无限制(分桶策略) | 2TB(需分区) |
潜在风险与应对
| 风险类型 | 规避策略 |
| 数据孤岛 | 采用标准接口(如S3/SQL) |
| 性能瓶颈 | 分层架构+智能路由 |
| 厂商锁定 | 选择开源方案(如Ceph+PostgreSQL) |
FAQs
Q1:分布式存储如何保证元数据的高可用?
A1:通常采用以下方案:
- 多副本同步(如Etcd/ZooKeeper集群)
- 动态选举机制(Raft/Paxos协议)
- 分片策略(Hash环/一致性哈希)
- 定期快照+增量日志(WAL)
Q2:什么场景必须同时使用分布式存储和数据库?
A2:当业务同时满足:
- 需要持久化存储海量非结构化数据(如视频/日志)
- 存在实时关联查询需求(如用户画像+行为日志分析)
- 要求事务一致性(如订单状态与支付记录联动)
典型如智能安防系统:摄像头流媒体存到分布式存储,元数据和告警事件存入时序