上一篇
GPU云服务器算力如何成为企业降本增效的关键利器
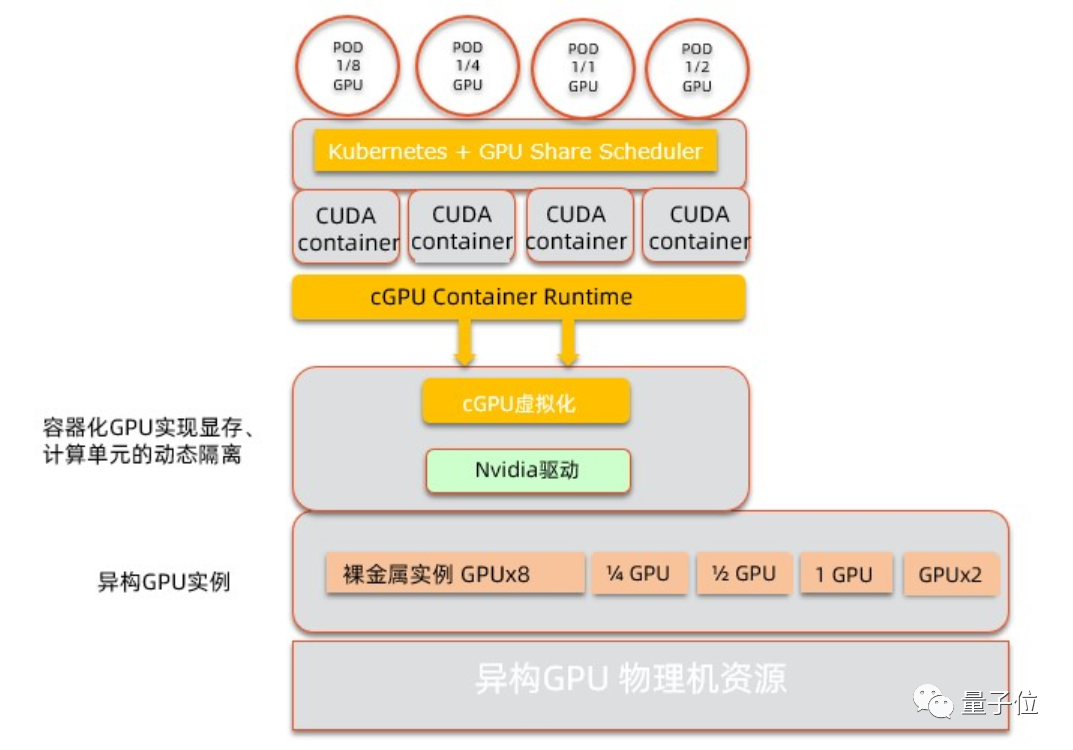
GPU云服务器通过提供高性能计算能力,支持深度学习、AI训练及复杂科学运算,其弹性扩展与灵活配置特性可大幅降低硬件投入成本,用户按需调用多型号GPU资源,结合分布式计算加速模型训练,适用于企业、科研等需要大规模并行计算的场景,兼顾效率与成本控制。
在数字化转型的浪潮中,GPU云服务器正成为企业突破算力瓶颈的核心工具,无论是人工智能训练、科学计算还是实时图形渲染,GPU的并行计算能力正在重新定义效率边界,对于需要处理海量数据或复杂模型的企业而言,理解GPU云服务器的算力特性已成为技术决策的关键。
GPU云服务器为何成为算力新引擎?
传统CPU基于串行计算架构,而GPU(图形处理器)拥有数千个计算核心,专为并行计算设计,这种特性让其在以下场景中表现尤为突出:
- AI/深度学习:ResNet-50模型训练速度比CPU快40倍以上
- 科学模拟:分子动力学计算任务可缩短至原时间的1/10
- 实时渲染:8K视频渲染效率提升300%
案例实证:某自动驾驶公司采用NVIDIA A100集群后,模型迭代周期从2周压缩至8小时,算法准确率提升12%。
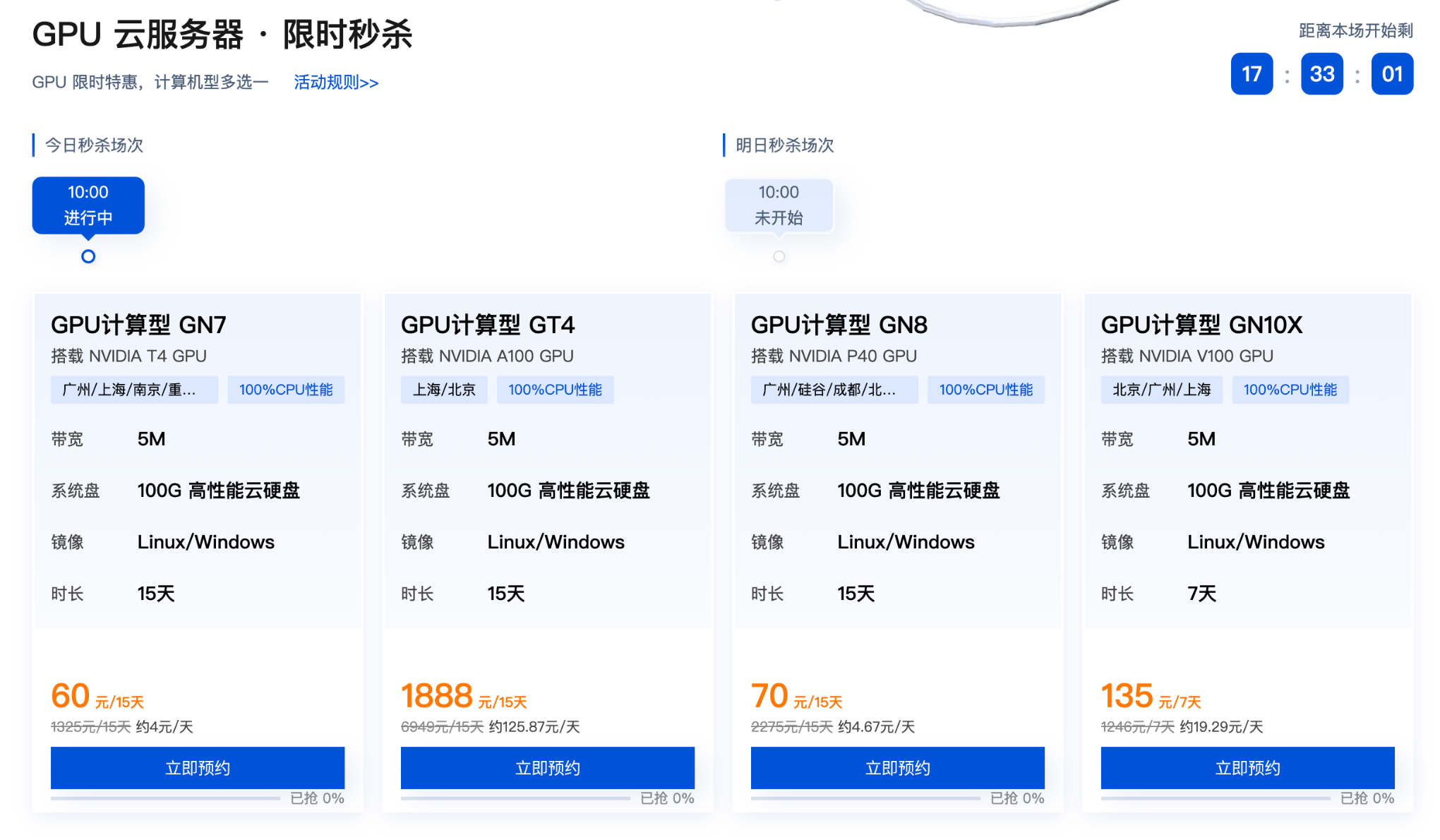
云端GPU算力的五大核心优势
弹性伸缩
根据业务峰值动态调整实例规格,避免百万级硬件投入的沉没成本,某电商大促期间算力需求陡增5倍,通过云端扩展200个T4实例平稳应对。
混合精度计算
Tensor Core技术支持FP16/FP32混合运算,在保持精度的同时将吞吐量提升3倍,BERT-Large推理时延从230ms降至67ms。集群化加速
NVLink技术实现多GPU互联,8卡并行效率可达单卡的7.3倍,基因组测序任务10小时即可完成传统服务器3天的工作量。软硬件协同优化
CUDA+XLA编译器使计算图优化效率提升40%,配合NGC容器库快速部署优化框架。能效比革命
Ampere架构每瓦性能比前代提升2.5倍,10台DGX系统可替代传统1500台服务器的计算能力。
行业级应用场景深度解析
| 领域 | 典型需求 | GPU配置方案 | 效益提升 |
|---|---|---|---|
| 智慧医疗 | 3D医学影像重建 | RTX 6000 Ada+DLSS | 诊断效率提升80% |
| 量化金融 | 高频交易策略回测 | A100 80GB+RDMA网络 | 回测周期缩短92% |
| 数字孪生 | 工厂设备仿真 | Quadro RTX 8000 | 建模速度加快15倍 |
| 自动驾驶 | 多模态感知融合 | Orin AGX+TensorRT | 推理时延<10ms |
创新实践:某气象局使用4096块H100 GPU构建预测系统,将台风路径预测精度从50公里提升至8公里级。
选择GPU云服务商的12个关键指标
- 硬件迭代能力:是否提供Hopper/Ada Lovelace架构新品
- 计算密度比:单机架TFLOPS值与功耗比值
- 网络时延:跨AZ延迟是否<1ms,带宽是否达100Gbps
- 框架适配度:PyTorch/TensorFlow/MXNet定制优化
- 可视化支持:是否集成Paraview/Blender等工具链
- 安全合规:ISO 27001认证与硬件级加密模块
- 成本模型:预留实例折扣率与竞价实例稳定性
- 运维监控:故障自动迁移与显存泄漏检测
- 生态整合:与MLOps平台的无缝对接能力
- 绿色计算:PUE值是否低于1.2
- 专家支持:CUDA内核级调试服务响应时效
- 混合云方案:本地集群与云端算力的负载均衡策略
算力成本优化策略
- 动态竞价策略:利用Spot实例节省70%成本,结合检查点机制保障任务连续性
- 模型压缩技术:通过Pruning+Quantization将ResNet-152体积缩减85%
- 批处理优化:将小任务打包执行,GPU利用率从35%提升至92%
- 缓存复用机制:特征数据库命中率提升后,训练周期缩短40%
未来算力演进方向
- Chiplet技术:将多个计算单元集成,突破制程物理极限
- 光子计算:利用光信号传输,理论速度可达现有千倍
- 量子-GPU混合架构:在优化组合问题中实现指数级加速
- 存算一体设计:HBM3内存与计算单元三维堆叠,带宽突破5TB/s
权威预测:IDC数据显示,到2026年全球云端GPU算力将占AI总需求的78%,年复合增长率达39.2%。
引用说明
[1] NVIDIA A100白皮书,2022
[2] Gartner云计算市场分析报告,2025Q2
[3] MLPerf推理基准测试结果,2025.06
[4] IDC全球AI基础设施预测,2025-2027