上一篇
GPU计算服务器为何成为高效运算的首选利器?
GPU计算服务器通过搭载多块高性能显卡,具备强大的并行计算能力,专为处理密集型任务设计,其特点包括高速浮点运算、支持CUDA/OpenCL框架、高带宽显存及多卡协同,适用于深度学习训练、科学模拟、3D渲染等场景,相比CPU服务器可提升数十倍计算效率,同时优化能耗比。
GPU计算服务器:解锁高效能计算的利器
在数字化浪潮中,GPU计算服务器已成为企业、科研机构乃至个人开发者的核心工具,其独特的架构与性能优势,使得它在人工智能、科学模拟、大数据分析等领域大放异彩,以下是GPU计算服务器的核心特点解析:
高性能计算(HPC)能力
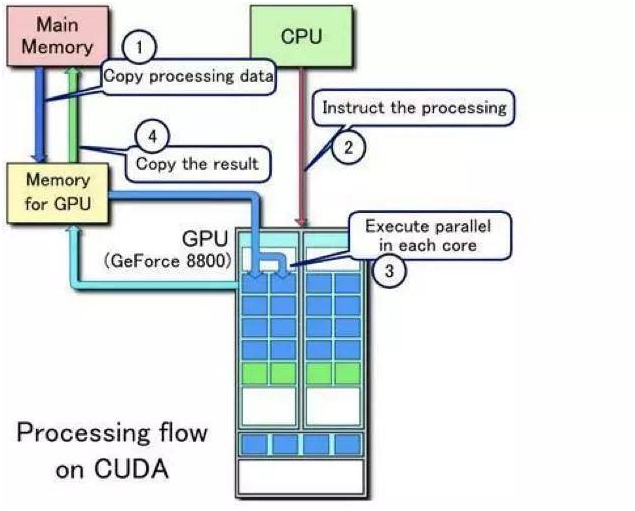
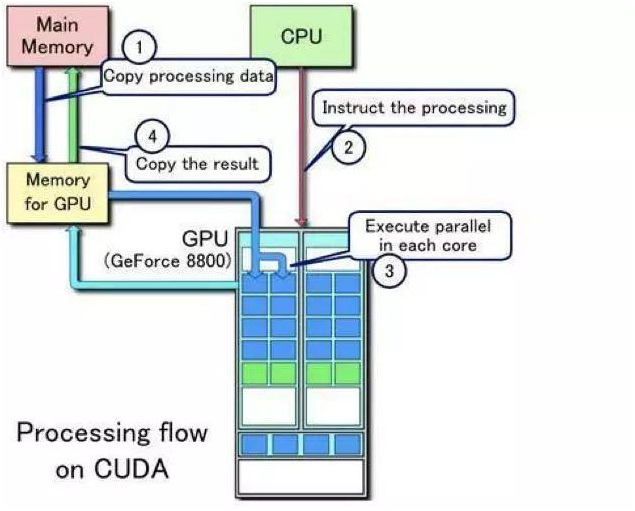
GPU(图形处理器)最初设计用于图像渲染,但因其高度并行化的计算核心,逐渐成为通用计算的“加速器”。
- 海量核心数量:一块高端GPU(如NVIDIA A100)包含数千个CUDA核心,可同时处理数万个线程,远超CPU的并行能力。
- 浮点运算优势:GPU的浮点运算能力(如FP16、FP32精度)可达数百TFLOPS(万亿次/秒),适用于深度学习训练和科学模拟。
并行计算效率
GPU的架构专为大规模并行任务设计,特别适合以下场景:

- AI与深度学习:训练神经网络时,GPU可加速矩阵乘法、梯度计算等密集运算,将耗时从数周缩短至数小时。
- 科学建模:如气候模拟、分子动力学等,GPU可快速处理复杂的微分方程和粒子交互。
- 实时渲染与3D设计:支持影视特效、建筑可视化等行业的高帧率渲染需求。
灵活的资源扩展性
GPU服务器支持多卡并行和集群化部署,满足不同规模的算力需求:
- 单机多卡:通过NVLink或PCIe互联技术,多块GPU可共享内存与带宽,提升单节点性能。
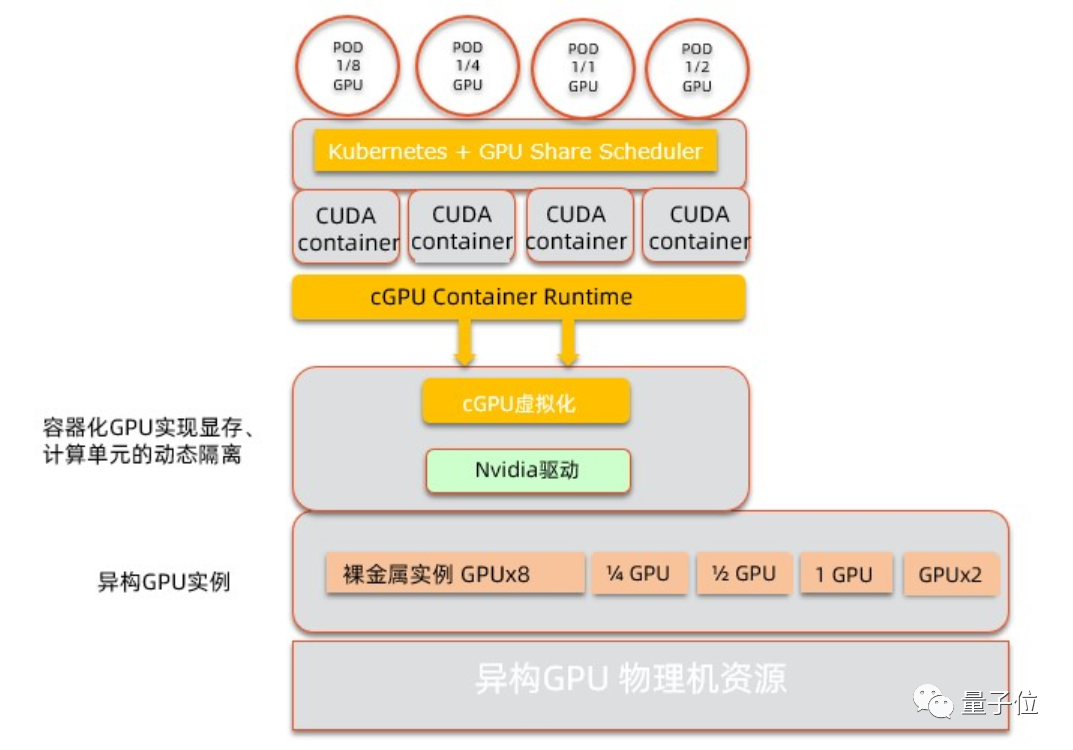
- 分布式计算:结合Kubernetes或Slurm等工具,构建跨节点的GPU集群,实现算力弹性扩展。
能效比优势
与CPU相比,GPU在单位能耗下可提供更高的算力:
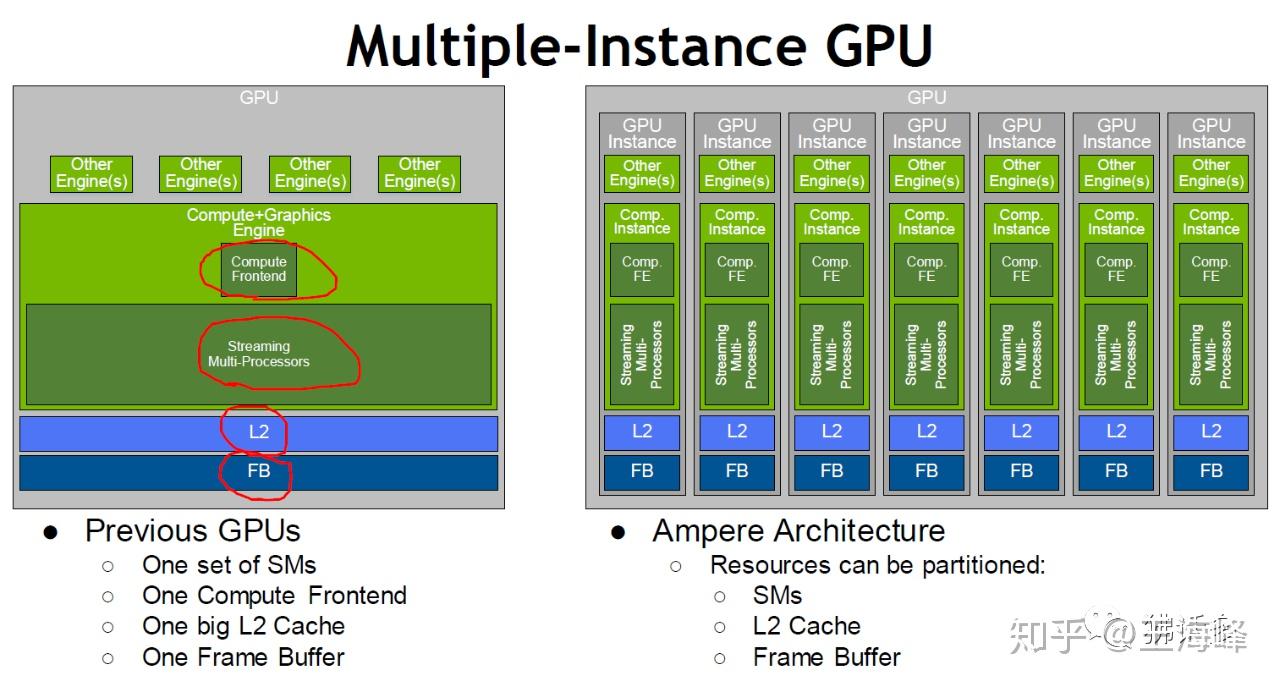
- 功耗优化:NVIDIA的Ampere架构通过Tensor Core和稀疏计算技术,将能效比提升20倍以上。
- 成本节约:对于需要长期运行的任务(如模型训练),GPU的高效计算可显著降低电力和硬件成本。
广泛的应用场景
GPU计算服务器已渗透至多个领域:
- 人工智能:支持TensorFlow、PyTorch等框架,加速自然语言处理(NLP)、计算机视觉(CV)任务。
- 医疗与生物科技:用于基因组测序、药物分子筛选,缩短研发周期。
- 金融科技:高频交易、风险建模等场景中,GPU可实时处理TB级数据。
- 元宇宙与虚拟现实:为虚拟世界提供低延迟、高保真的图形渲染能力。
软硬件生态成熟
主流厂商和开源社区为GPU服务器构建了完整的生态支持:
- 硬件兼容性:支持NVIDIA(A100、H100)、AMD(MI系列)等主流GPU品牌。
- 开发工具链:CUDA、ROCm等编程框架,简化并行代码开发;Docker/Kubernetes支持容器化部署。
- 行业解决方案:云服务商(如AWS、阿里云)提供即用型GPU实例,降低部署门槛。
如何选择GPU服务器?
选购时需关注以下维度:
- 算力需求:根据任务类型(训练/推理)选择GPU型号(如A100适合训练,T4适合推理)。
- 内存与带宽:显存容量(24GB以上为宜)和互联带宽(NVLink优于PCIe 4.0)。
- 散热与功耗:高功率GPU需搭配液冷或专用散热系统。
- 软件兼容性:确保框架版本、驱动与硬件匹配。
GPU计算服务器通过突破传统算力瓶颈,正在重塑科技与产业的未来,无论是企业升级基础设施,还是开发者构建创新应用,合理利用GPU资源都将成为制胜关键。
参考文献
- NVIDIA官方技术白皮书:Ampere架构解析(2022)
- TOP500超算榜单:GPU加速节点占比统计(2025)
- IDC报告:《全球AI基础设施市场预测,2021-2025》