上一篇
分布式架构云原生设置
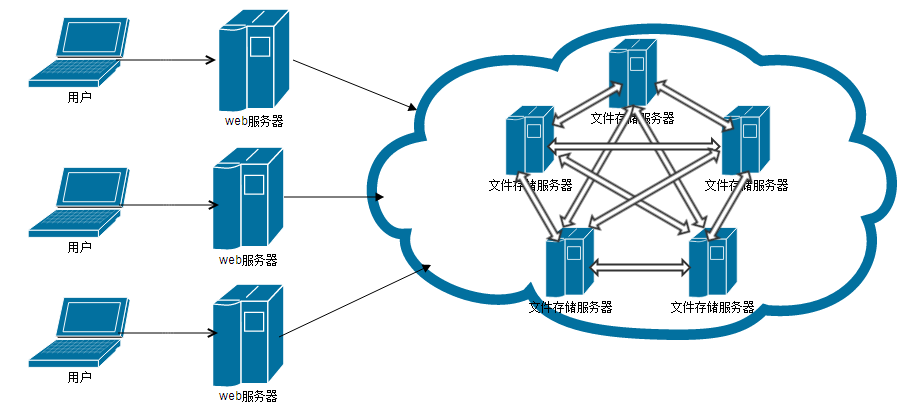
分布式架构云原生设置通过容器化部署、微服务拆分、自动化运维,基于
分布式架构云原生设置详解
在云计算时代,分布式架构与云原生技术的结合成为企业构建高可用、高扩展性系统的核心方案,云原生(Cloud-Native)强调通过容器化、微服务、不可变基础设施等技术,实现应用的敏捷开发与运维,本文将从分布式架构的设计原则、云原生关键技术实现及最佳实践三个维度展开,结合具体工具与案例,解析如何在云环境中高效部署分布式系统。
分布式架构的核心设计原则
分布式架构的核心目标是解决传统单体架构的扩展性、容错性瓶颈,其设计需遵循以下原则:
| 原则 | 说明 |
|---|---|
| 分区容忍性 | 系统在部分节点故障时仍能正常运行,通过冗余设计和自动故障转移实现。 |
| 无状态设计 | 服务节点不保存用户会话状态,状态数据存储在外部数据库或缓存中,便于横向扩展。 |
| 负载均衡 | 通过DNS轮询、反向代理(如Nginx)或云负载均衡器分发请求,避免单点压力。 |
| 最终一致性 | 允许数据在分布式系统中短暂不一致,通过异步同步机制达成最终一致(如CAP理论)。 |
典型场景:电商订单系统采用分库分表存储订单数据,通过Redis缓存热点商品信息,结合Kafka处理异步订单消息,确保高并发下的系统稳定性。
云原生关键技术实现
云原生技术为分布式架构提供了标准化的工具链,以下是核心组件的设置方法:

容器化与编排(Docker & Kubernetes)
- 容器化:将应用及其依赖打包为Docker镜像,确保环境一致性,Java应用通过
Dockerfile定义JDK、依赖库及启动命令。 - Kubernetes编排:
- Deployment:声明式定义服务副本数,支持滚动升级。
- Service:通过ClusterIP、NodePort或LoadBalancer暴露服务。
- ConfigMap & Secret:分离配置与镜像,动态更新配置无需重启容器。
示例:一个微服务集群通过Kubernetes的Horizontal Pod Autoscaler(HPA)实现自动扩缩容,结合Probes(探针)检测服务健康状态。
服务网格(Service Mesh)
- Istio/Linkerd:通过Sidecar模式注入代理(如Envoy),实现服务间的流量控制、熔断、认证。
- 核心功能:
- 灰度发布:按百分比分流新版本流量。
- A/B测试:不同版本服务接收特定请求。
- 分布式追踪:集成Jaeger采集调用链数据。
实践建议:在Kubernetes集群中部署Istio时,需启用istio-injection Webhook,自动为Pod注入Sidecar代理。
无服务器架构(Serverless)
- 适用场景:事件驱动型任务(如图像处理、定时任务)。
- 工具选择:
- AWS Lambda:支持Python、Java等语言,按执行时长计费。
- Knative:Kubernetes上的Serverless框架,兼容HTTP触发器。
案例:某视频平台使用AWS Lambda处理用户上传的封面图,自动调用ImageMagick裁剪并存储至S3。
持续集成与交付(CI/CD)
- 流水线设计:
- 代码阶段:GitLab CI/Jenkins拉取代码并运行单元测试。
- 构建阶段:Docker镜像构建与推送至镜像仓库(如Harbor)。
- 部署阶段:通过Argo CD或Flux实现GitOps,自动同步Kubernetes配置。
工具链:GitLab CI + Helm + Skaffold组合,支持多环境分级发布。
监控与运维优化
分布式系统的复杂性要求全方位的可观测性:
| 监控类型 | 工具 | 作用 |
|---|---|---|
| 基础设施监控 | Prometheus + Grafana | 采集CPU、内存、网络等指标,设置告警规则。 |
| 应用性能监控 | Jaeger/Zipkin | 追踪分布式调用链,分析延迟瓶颈。 |
| 日志管理 | ELK Stack(Elasticsearch/Logstash/Kibana) | 集中化日志存储与检索,支持错误排查。 |
| 混沌工程 | Chaos Monkey/Gremlin | 模拟节点故障、网络延迟,验证系统韧性。 |
优化策略:
- 弹性伸缩:根据Prometheus指标动态调整Kubernetes HPA阈值。
- 成本控制:使用Spot Instances(如AWS)降低计算成本,结合Kubernetes的
Taints & Tolerations调度低优先级任务。
FAQs
Q1:如何降低分布式系统在云原生环境下的运维复杂度?
A1:通过以下方式简化运维:
- 采用声明式配置(如Kubernetes YAML),减少手动操作。
- 使用Service Mesh统一管理服务间通信。
- 集成CI/CD工具链实现自动化部署与回滚。
- 利用云厂商的托管服务(如AWS RDS、S3)减少自建组件。
Q2:云原生架构如何保障数据一致性?
A2:需结合业务场景选择方案:
- 强一致性:使用分布式事务(如Seata)或基于Raft协议的数据库(如etcd)。
- 最终一致性:通过消息队列(如Kafka)异步同步数据,适用于非实时场景。
- 分区策略:按业务维度分片(如按用户ID哈希分库),减少跨节点