上一篇
分布式数据库无法启动
分布式数据库无法启动,需排查网络、配置及节点状态,查看日志
分布式数据库无法启动的常见原因及解决方案
分布式数据库系统因涉及多节点协同、复杂网络通信和一致性协议,启动失败的问题可能由多种因素引发,以下是常见问题分类、排查思路及解决方案:
核心问题分类
| 问题类别 | 典型表现 |
|---|---|
| 网络通信故障 | 节点间无法互通、心跳检测超时、协调服务(如ZooKeeper)不可用 |
| 配置参数错误 | 集群元数据不一致、端口冲突、存储路径配置错误 |
| 节点状态异常 | 部分节点未同步、数据副本损坏、节点角色冲突(如多个主节点) |
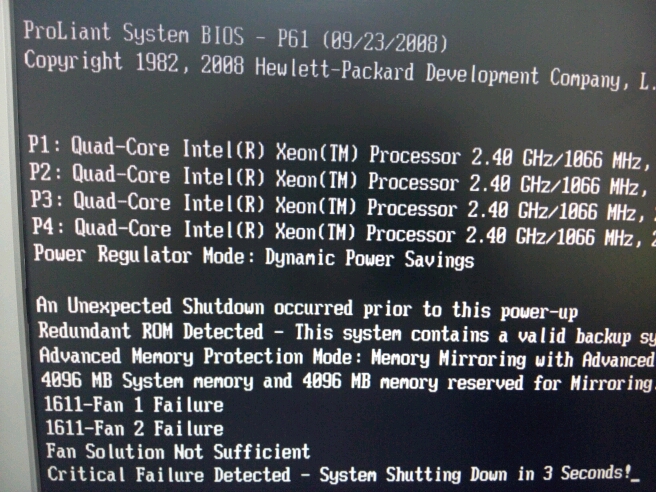
| 资源限制 | 内存不足、磁盘空间耗尽、CPU负载过高导致初始化失败 |
| 版本兼容性问题 | 新旧节点软件版本不匹配、依赖库缺失或损坏 |
| 权限与安全限制 | 用户权限不足、防火墙拦截关键端口、SSL证书配置错误 |
分步排查与解决方案
步骤1:检查网络连通性
- 操作:
- 使用
ping或telnet测试节点间网络(如协调服务地址、各节点监听端口)。 - 检查防火墙规则是否允许数据库通信端口(如26257、26401等)。
- 验证DNS解析是否正确,避免因主机名解析失败导致节点失联。
- 使用
- 示例工具:
# 测试端口连通性 telnet node2:26257 nc -zv node3 26401
步骤2:验证配置文件一致性

- 关键检查项:
| 配置项 | |
|—————————|—————————————————————————–|
| 集群元数据 |cluster.yaml或cockroach.crt等文件中的节点ID、JoinPeer列表是否一致 |
| 存储路径 | 数据目录(如--store=/var/lib/cockroach)是否存在且权限正确 |
| 端口占用 | 检查监听端口(如RPC、HTTP)是否被其他进程占用(netstat -tulnp) | - 修复方法:
- 同步所有节点的配置文件,确保
join参数指向正确的IP和端口。 - 清理残留的临时文件(如
lost+found目录中的损坏数据)。
- 同步所有节点的配置文件,确保
步骤3:查看日志定位根因
- 日志路径:
- 通常位于
$DATA_DIR/logs/或/var/log/<db_name>/。
- 通常位于
- 常见错误提示:
- 网络类:
failed to connect to node X、RPC timeout。 - 配置类:
invalid cluster configuration、certificate mismatch。 - 数据类:
raft group failed to start、missing WAL files。
- 网络类:
- 高级技巧:
- 启用调试日志(如CockroachDB的
--v=2)获取详细信息。 - 对比正常节点与故障节点的日志差异。
- 启用调试日志(如CockroachDB的
步骤4:恢复节点状态
- 场景1:单节点故障
- 停止故障节点,清理数据目录后重新加入集群:
# 停止并清理数据 systemctl stop cockroach rm -rf /var/lib/cockroach/node2/ # 重启节点 systemctl start cockroach
- 停止故障节点,清理数据目录后重新加入集群:
- 场景2:元数据损坏
- 使用
init-sql重新初始化集群(需谨慎,可能丢失数据):cockroach quit --insecure --host=node1:26257 --execute="INIT SQL"
- 使用
步骤5:资源与权限修复
- 内存/磁盘:
- 检查
ulimit -n是否足够(建议≥65535)。 - 清理磁盘空间,保留至少10%空闲。
- 检查
- 权限:
- 确保运行用户对数据目录有读写权限:
chown -R cockroach:cockroach /var/lib/cockroach
- 确保运行用户对数据目录有读写权限:
常见问题对照表
| 错误现象 | 可能原因 | 解决方案 |
|---|---|---|
| 集群初始化后所有节点均离线 | 网络分区或防火墙未开放端口 | 检查各节点间TCP连通性,开放必要端口(如26257、26401) |
| 部分节点反复重启 | 数据目录损坏或WAL日志缺失 | 删除损坏节点的数据目录,通过join重新同步数据 |
| 协调服务(如Etcd)无法选举成功 | 单节点部署或时钟不同步 | 部署至少3个Etcd节点,使用NTP校准时间 |
| 启动时报“证书无效” | SSL配置错误或CA证书过期 | 替换有效的server.crt/ca.crt文件,或禁用SSL(仅限开发环境) |
| 集群扩容后新节点无法加入 | 旧节点配置未更新 | 修改所有节点的cluster.yaml,添加新节点信息后重启集群 |
FAQs
Q1:如何避免分布式数据库启动时的配置冲突?
A1:
- 使用配置管理工具(如Ansible、Chef)统一分发配置文件。
- 版本控制配置文件(如Git),变更前进行集群范围的同步。
- 启用集群健康检查(如CockroachDB的
SHOW RANGES)验证配置生效。
Q2:如何验证分布式数据库集群是否完全健康?
A2:
- 检查所有节点状态:
SHOW NODES(CockroachDB)或SELECT FROM system.nodes(TiDB)。 - 确认数据副本分布均匀,无离线范围(CockroachDB的
SHOW RANGES)。 - 模拟故障注入(如关闭一个节点),观察集群能否自动恢复