上一篇
分布式数据库适用于大数据分析
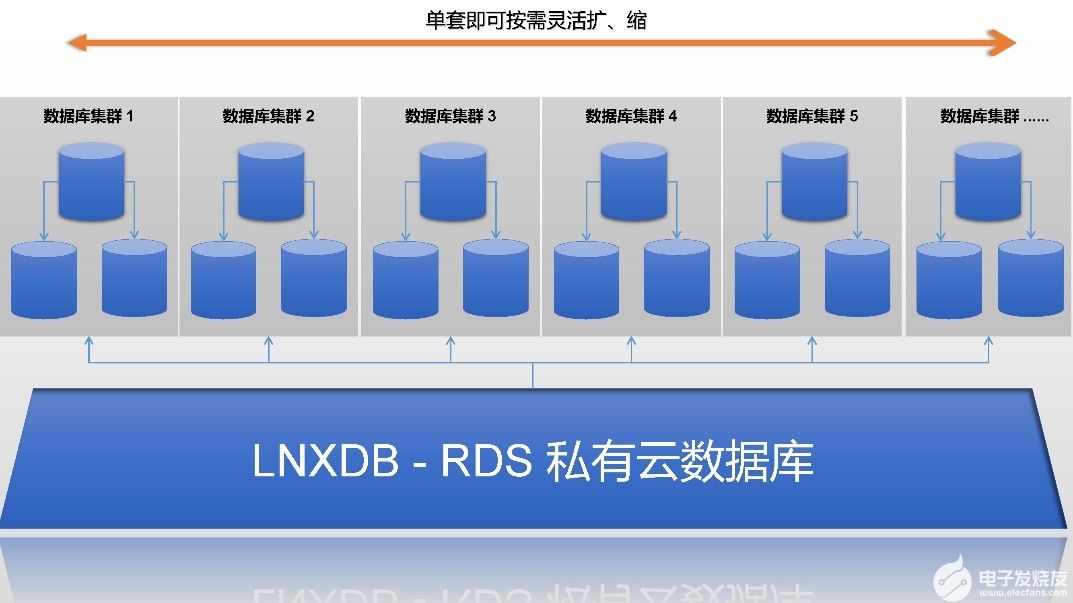
分布式数据库凭借横向扩展性、高并发处理能力和数据分片机制,可高效支撑PB级数据存储与实时分析,天然适配大数据场景
分布式数据库在大数据分析中的适用性分析
大数据与分布式数据库的技术契合点
大数据分析的核心特征可概括为”4V”:Volume(数据量巨大)、Velocity(处理速度快)、Variety(数据类型多样)、Value(价值密度低),传统集中式数据库在处理PB级数据时面临存储容量瓶颈、计算资源受限、扩展成本高昂等问题,而分布式数据库通过以下技术特性完美匹配大数据需求:
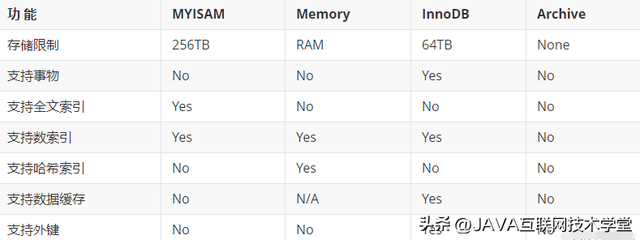
| 技术特性 | 传统数据库 | 分布式数据库 |
|---|---|---|
| 存储扩展 | 纵向扩展(硬件升级) | 横向扩展(节点增减) |
| 计算能力 | 单节点CPU/内存限制 | 多节点并行计算 |
| 数据吞吐量 | 受限于单机磁盘IO | 分布式存储吞吐叠加 |
| 容错能力 | 单点故障导致服务中断 | 自动故障转移与数据冗余 |
| 成本模型 | 高端硬件采购成本高 | 普通PC服务器集群成本可控 |
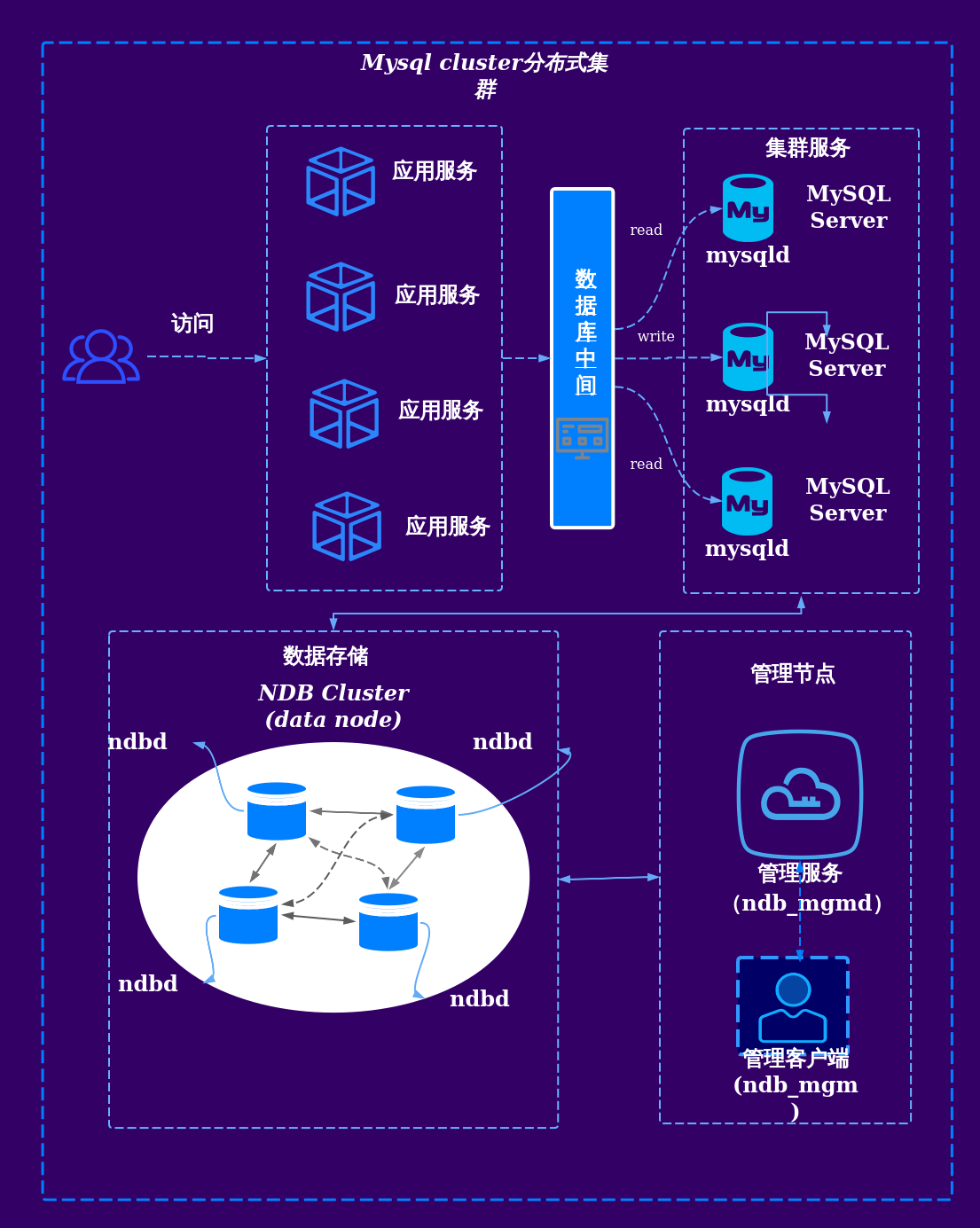
分布式数据库的核心技术架构
数据分片(Sharding)
- 水平分片:按主键范围/哈希值分割数据表
- 垂直分片:按业务模块分割不同数据表
- 混合分片:结合业务特征的多维分片策略
分布式事务管理
- 两阶段提交(2PC)协议保障强一致性
- 基于Paxos/Raft的共识算法实现分布式锁
- 最终一致性模型(如Amazon Dynamo)提升性能
查询优化机制

- 全局查询计划生成与执行
- 数据本地化处理减少网络传输
- 智能路由算法选择最优执行路径
存储引擎特性
- 列式存储(如HBase)优化分析查询
- LSM树结构提升写入性能
- 数据压缩与编码减少存储空间
典型应用场景与性能优势
实时数据仓库场景
- 传统方案:ETL过程耗时数小时,数据延迟严重
- 分布式方案:
• 流批一体处理(如Flink+Kafaka)
• 列式存储加速聚合计算
• 数据新鲜度提升至分钟级
机器学习训练
- 数据并行处理:
• 参数服务器架构(如TensorFlow)
• 分布式文件系统加速数据读取
• 训练时间从天级缩短至小时级
日志分析系统
- 弹性扩展能力:
• 自动扩容应对突发流量
• 冷热数据分层存储
• 万亿级日志秒级查询响应
主流分布式数据库对比
| 产品类别 | OLAP优化型 | NewSQL型 | NoSQL型 |
|---|---|---|---|
| 典型代表 | Greenplum, ClickHouse | CockroachDB, TiDB | Cassandra, HBase |
| 事务支持 | ACID(受限) | 完整ACID支持 | 最终一致性 |
| 查询语言 | SQL(扩展) | 标准SQL | API/CQL |
| 扩展方式 | 共享存储架构 | 共享无存储架构 | 纯分布式架构 |
| 最佳场景 | 复杂分析查询 | 混合负载业务 | 海量非结构化数据 |
实施关键考量因素
数据模型设计
- 宽表设计原则:减少JOIN操作,降低网络开销
- 预聚合字段:提前计算常用统计指标
- 时间分区策略:按时间维度划分数据片
硬件资源配置
- 计算节点:CPU密集型任务优先配置
- 存储节点:HDD+SSD混合存储架构
- 网络架构:RDMA技术提升节点间带宽
成本控制策略
- 存算分离架构:独立扩展存储和计算资源
- 云原生部署:利用Kubernetes实现弹性伸缩
- 冷热数据分层:结合对象存储降低成本
技术演进趋势
- Serverless架构:自动弹性伸缩,按查询计费
- AI驱动优化:自适应查询优化与索引推荐
- 多模数据处理:支持时序数据、图数据等新类型
- 联邦学习集成:隐私保护下的分布式模型训练
FAQs
Q1:如何判断业务是否需要分布式数据库?
A1:当出现以下情况时建议评估分布式方案:
- 单表数据量超过10亿条
- 每日新增数据量超TB级
- 查询响应时间要求低于秒级
- 需要7×24小时不间断服务
- 存在多地域数据同步需求
Q2:分布式数据库部署有哪些常见陷阱?
A2:需特别注意:
- 数据分片策略不当导致热点问题
- 忽视网络分区对可用性的影响
- 未预留足够的系统监控接口
- 低估运维复杂度(建议配套自动化工具链)
- 忽略数据治理体系建设(元数据管理、血缘分析