上一篇
Hadoop集群各节点的负载均衡
Hadoop通过HDFS数据块自动均衡和YARN动态任务调度,结合心跳检测与资源感知机制,实现集群节点间计算存储负载的智能分配与再平衡
Hadoop集群各节点的负载均衡:原理、方法与实践
在Hadoop集群中,节点的负载均衡是保障系统高效运行的核心要素之一,负载均衡的目标是通过合理分配计算任务、存储资源和网络流量,避免部分节点过载而其他节点闲置,从而提升集群整体性能和资源利用率,本文将从负载均衡的原理、实现方法、工具支持及优化策略等方面展开详细分析。
负载均衡的核心意义
Hadoop集群的负载不均衡可能导致以下问题:
- 性能瓶颈:部分节点(如DataNode或TaskTracker)因负载过高成为系统瓶颈。
- 资源浪费:空闲节点未被充分利用,导致硬件资源浪费。
- 任务延迟:MapReduce任务因等待资源而延长执行时间。
- 存储失衡:HDFS中部分DataNode存储容量接近饱和,而其他节点空闲。
负载均衡需要从计算任务分配、数据存储分布、网络流量控制三个维度综合优化。
Hadoop集群负载不均衡的典型场景
| 场景 | 表现 |
|---|---|
| 数据存储失衡 | 某些DataNode磁盘使用率超过90%,而其他节点低于30%。 |
| 计算任务倾斜 | 部分NodeManager的CPU利用率长期高于80%,其他节点空闲。 |
| 网络带宽不均 | 部分节点因处理大量Map或Reduce任务,网络吞吐量饱和,导致任务延迟。 |
| 动态资源分配不足 | YARN容器未根据节点实时负载调整资源,导致固定分配策略下的资源浪费。 |
负载均衡的实现机制
Hadoop通过以下组件协同实现负载均衡:

HDFS层面的存储均衡
Balancer工具
HDFS提供hdfs balancer命令,用于平衡DataNode间的存储量,其原理是通过迁移Block(数据块)使各节点存储利用率接近平均值。- 触发条件:当集群中存储利用率最高与最低的节点差值超过设定阈值(默认10%)时,Balancer自动或手动启动。
- 示例:
hdfs balancer -threshold 5% # 将存储差异阈值调整为5%
数据写入策略
HDFS的BlockPlacementPolicy策略默认采用机架感知(Rack Awareness),优先将数据块分配到不同机架的节点,避免单机架故障或负载集中。
YARN层面的计算任务调度
资源调度器(Scheduler)
YARN的Scheduler负责将任务分配给NodeManager,不同调度器策略对负载均衡的影响如下:- FIFO Scheduler:按任务提交顺序分配资源,易导致先提交的任务独占资源。
- Fair Scheduler:按队列公平分配资源,适合多租户场景。
- Capacity Scheduler:基于队列容量分配资源,支持动态优先级调整。
- DRF(Dominant Resource Fairness):根据节点CPU、内存等主导资源使用率动态分配任务。
动态资源调整
通过配置yarn.nodemanager.resource.cpu-vcores和yarn.nodemanager.resource.memory-mb,允许NodeManager根据实时负载动态调整容器资源。
第三方工具支持
| 工具 | 功能 |
|---|---|
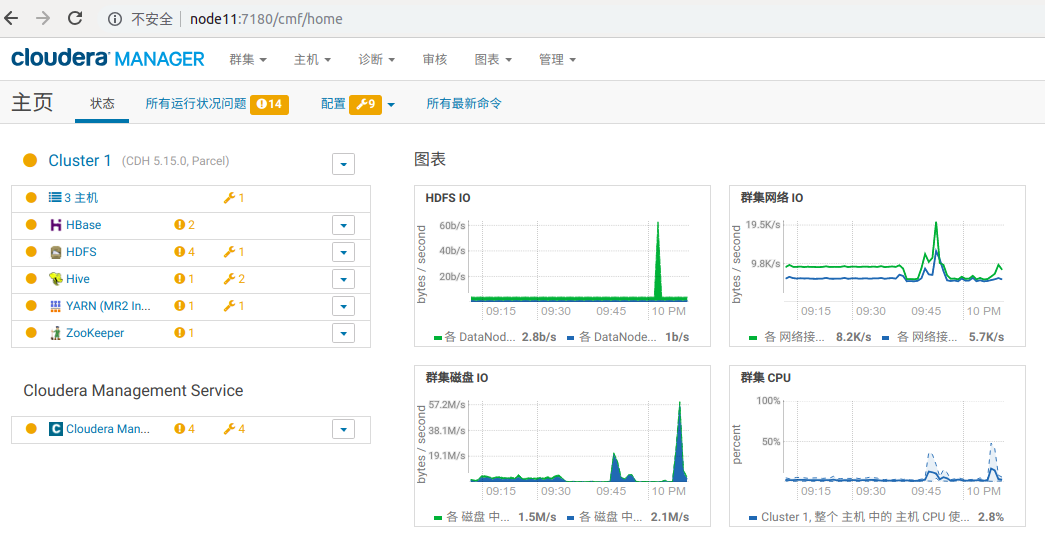
| Apache Ambari | 提供集群监控界面,支持手动触发HDFS Balancer和YARN资源重分配。 |
| Cloudera Manager | 集成负载均衡策略,支持自动化数据迁移和任务调度优化。 |
| Ganglia/Nagios | 监控系统性能指标(CPU、内存、磁盘IO),辅助负载均衡决策。 |
负载均衡的优化实践
数据再平衡(Rebalance)
- 场景:当HDFS中部分DataNode存储量长期偏离均值时,需手动或自动执行Balancer。
- 操作步骤:
- 检查集群存储分布:
hdfs dfsadmin -report | grep "Name: HDFS"
- 启动Balancer:
hdfs balancer -threshold 10%
- 监控迁移进度,完成后验证存储分布。
- 检查集群存储分布:
任务调度策略调整
- Fair Scheduler配置示例:
<property> <name>yarn.scheduler.fair.user-as-default-queue</name> <value>true</value> </property> <property> <name>yarn.scheduler.fair.preemption</name> <value>true</value> </property>
- DRF调度器配置:
通过yarn.scheduler.capacity.resource-calculator设置为drf,并配置权重参数。
动态资源分配
- NodeManager配置:
<property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>4</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>8192</value> </property>
- 效果:允许单个节点根据任务需求动态分配CPU和内存资源,减少资源碎片。
案例分析:解决DataNode存储失衡
问题描述:
某Hadoop集群中,DataNode A的存储使用率为95%,而DataNode B仅为20%,导致A节点频繁触发垃圾回收(GC)并影响读写性能。
解决方案:
- 执行HDFS Balancer:
启动Balancer工具,将A节点的Block迁移至B节点。 - 调整写入策略:
修改dfs.client.block.write.locations.timeout参数,优先向低负载节点写入数据。 - 监控与优化:
使用Ambari监控存储分布,定期执行Balancer以防止再次失衡。
常见问题与解答(FAQs)
Q1:如何判断Hadoop集群是否存在负载不均衡?
A1:可通过以下方式检测:
- 存储层面:使用
hdfs dfsadmin -report查看各DataNode存储利用率。 - 计算层面:通过YARN ResourceManager UI检查各NodeManager的CPU、内存使用率。
- 网络层面:监控节点的网络带宽占用(如使用
iftop或Ambari流量图)。
若某类资源在不同节点的差异超过20%,则需警惕负载失衡。
Q2:如何选择YARN的资源调度器?
A2:根据业务需求选择:
- FIFO:适用于单一作业流,无需复杂调度。
- Fair Scheduler:适合多用户共享集群,保证资源公平分配。
- Capacity Scheduler:适合大型企业,按部门或团队划分资源队列。
- DRF:适合异构集群,根据节点实际资源使用率