上一篇
hadoop集群服务器
Hadoop集群服务器由主从架构组成,通过HDFS分布式存储数据,利用YARN资源调度实现高效计算,具备高可用性和横向扩展能力,支撑海量数据处理任务
Hadoop集群服务器详解
Hadoop集群基础架构
Hadoop集群由多个核心组件构成,通过分布式架构实现海量数据的存储与计算,以下是主要组件及其功能:
| 组件 | 功能描述 |
|---|---|
| NameNode | 管理HDFS文件系统的元数据(如文件路径、权限、块位置),协调客户端读写操作。 |
| DataNode | 存储实际数据块,定期向NameNode汇报存储状态,处理读写请求。 |
| ResourceManager | 负责YARN资源管理,分配容器(Container)给应用程序。 |
| NodeManager | 管理单个节点的资源(CPU、内存),监控容器运行状态。 |
| SecondaryNameNode | 辅助NameNode进行元数据checkpoint,减轻主节点负载(Hadoop 3.x已弃用)。 |
| HistoryServer | 记录并展示YARN作业的执行历史。 |
硬件配置要求
Hadoop集群的性能与硬件密切相关,以下是典型生产环境的硬件推荐:
| 角色 | CPU | 内存 | 存储 | 网络 |
|---|---|---|---|---|
| NameNode | 8核+ | 32GB+ | SSD(RAID-1),容量根据元数据规模 | 千兆网卡+ |
| DataNode | 16核+ | 64GB+ | HDD/SSD混合(HDD容量大,SSD作缓存) | 千兆网卡+ |
| ResourceManager | 8核+ | 16GB+ | 本地磁盘(用于日志) | 千兆网卡+ |
| NodeManager | 同DataNode | 同DataNode | 同DataNode | 同DataNode |
说明:

- NameNode需快速读写元数据,建议使用SSD;
- DataNode存储容量需根据数据量规划,HDD成本低但速度慢,可搭配SSD缓存加速;
- 网络建议千兆或更高(如万兆),避免数据传输瓶颈。
软件环境准备
- 操作系统:CentOS/RHEL/Ubuntu(企业环境常用CentOS 7+);
- Java版本:OpenJDK 8或11(需与Hadoop版本兼容);
- SSH免密登录:所有节点需配置SSH互信(
ssh-keygen+ssh-copy-id); - 时间同步:通过NTP服务确保集群时间一致(如
ntpdate或chrony); - Hosts配置:编辑
/etc/hosts,为所有节点设置域名解析。
集群部署步骤
- 下载Hadoop:从Apache官网获取二进制包(如
hadoop-3.4.0.tar.gz); - 解压与配置:
- 修改
hadoop-env.sh,设置JAVA_HOME; - 编辑
core-site.xml,配置fs.defaultFS(如hdfs://master:9000); - 编辑
hdfs-site.xml,设置dfs.replication(默认3)、dfs.namenode.name.dir; - 编辑
yarn-site.xml,设置yarn.resourcemanager.hostname;
- 修改
- 格式化NameNode:首次启动时执行
hdfs namenode -format; - 启动集群:
start-dfs.sh # 启动HDFS start-yarn.sh # 启动YARN
- 验证状态:通过
jps命令检查进程(如NameNode、DataNode、ResourceManager)。
关键参数调优
| 参数 | 默认值 | 调优建议 | 影响 |
|---|---|---|---|
dfs.blocksize | 128MB | 调整为128MB或64MB(小文件场景) | 数据块大小,影响Map任务数量 |
dfs.replication | 3 | 根据容错需求调整(如EC2环境可设为2) | 副本数,存储成本与可靠性权衡 |
yarn.nodemanager.resource.memory-mb | 8192MB | 根据节点内存扩容(如32GB节点设为24GB) | 单个容器最大可用内存 |
mapreduce.task.io.sort.mb | 100MB | 增大至200MB+(处理大文件时) | 减少Shuffle阶段I/O次数 |
监控与运维工具
- Ambari:图形化管理工具,支持集群部署、监控、报警;
- Ganglia/Nagios:监控系统资源(CPU、内存、网络);
- HDFS Web UI:访问
http://master:9870查看存储概况; - YARN Web UI:访问
http://master:8088查看作业进度。
日志管理:
- NameNode/DataNode日志路径:
$HADOOP_HOME/logs/; - 通过
log4j.properties调整日志级别(如将INFO改为WARN减少日志量)。
常见问题与解决方案
DataNode频繁离线:
- 检查网络连通性(
ping master); - 清理DataNode存储目录(删除
/var/hadoop/dfs/data下残留数据); - 调整
dfs.heartbeat.interval(默认3秒)和dfs.client.block.write.timeout。
- 检查网络连通性(
YARN作业执行缓慢:
- 增加
yarn.scheduler.maximum-allocation-mb(如从8GB提至16GB); - 优化MapReduce代码(如减少排序次数、使用Combiner);
- 检查NodeManager内存是否不足(
top命令监控containers进程)。
- 增加
FAQs
Q1:Hadoop集群中NameNode宕机如何处理?
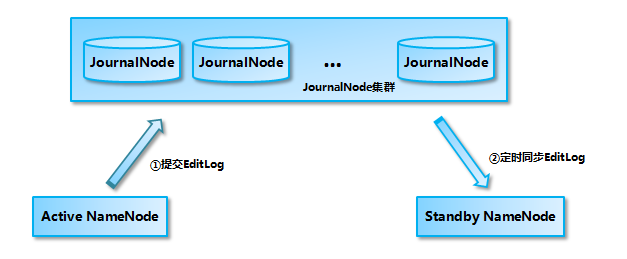
A1:若未部署高可用(HA)模式,需手动重启NameNode并恢复元数据,建议生产环境启用HA模式(通过QJM或ZooKeeper实现主备切换),避免单点故障。
Q2:如何平衡Hadoop集群的存储与计算资源?
A2:根据数据本地性原则,优先将计算任务调度到数据所在节点,可通过调整YARN的yarn.nodemanager.vmem-pmem-ratio(虚拟内存比例)和yarn.scheduler.minimum-allocation-vcores