上一篇
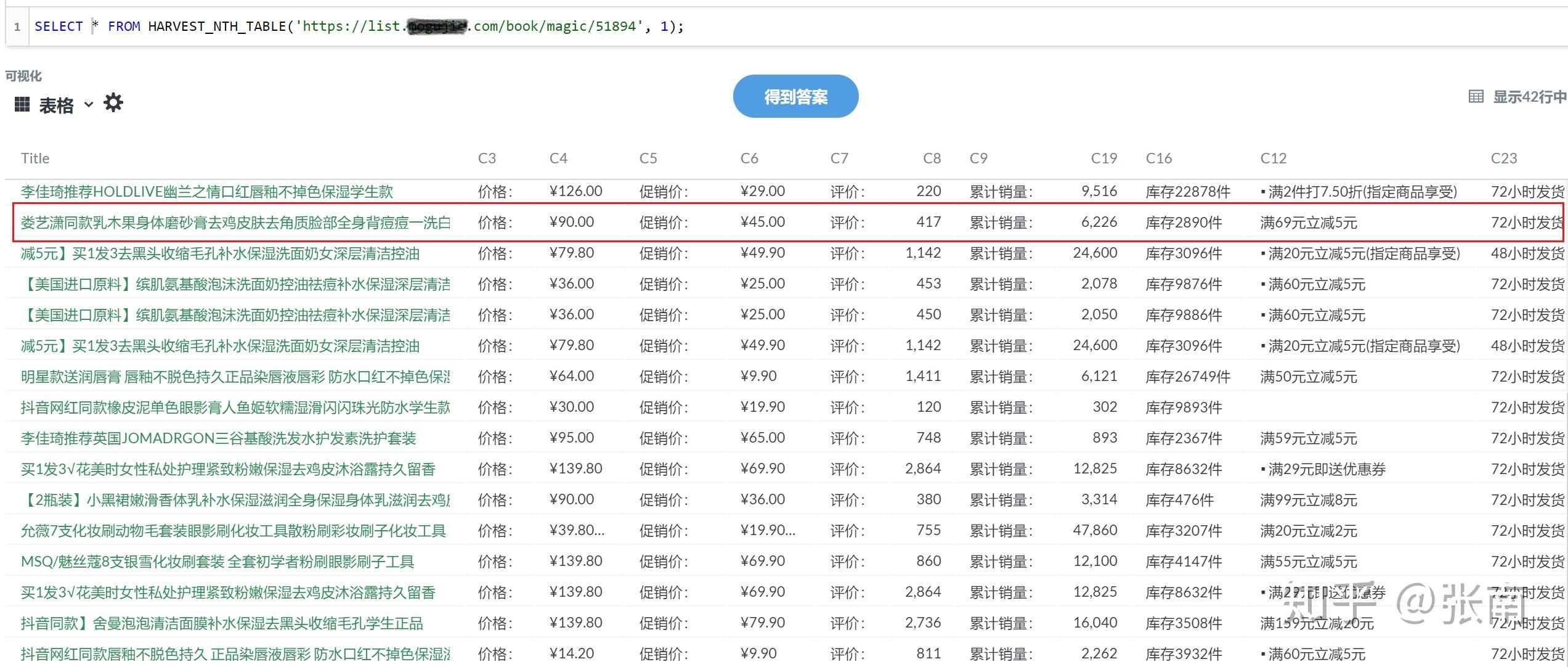
html文件取数据
使用解析库(如Python的BeautifulSoup)加载HTML文件,通过选择器定位目标元素,提取文本
工具选择与环境准备
| 工具/库 | 适用场景 | 特点 |
|---|---|---|
| Python + BeautifulSoup | 静态HTML文件解析 | 简单易用,支持CSS选择器 |
| JavaScript + Cheerio | Node.js环境解析HTML | 高效处理大型文件,支持链式操作 |
| 正则表达式 | 快速提取特定模式的文本 | 灵活但需手动处理复杂结构 |
| Selenium | 动态加载的HTML(如JS渲染) | 模拟浏览器行为,支持动态内容抓取 |
HTML数据提取核心步骤
加载HTML文件
- Python示例:
from bs4 import BeautifulSoup with open("example.html", "r", encoding="utf-8") as file: html_content = file.read() soup = BeautifulSoup(html_content, "html.parser")
- Python示例:
定位目标数据

- 通过标签、类名、ID或属性筛选元素。
- 示例:提取所有
<table>中的<td>文本tables = soup.find_all("table") for table in tables: rows = table.find_all("tr") for row in rows: cells = row.find_all("td") data = [cell.get_text(strip=True) for cell in cells] print(data) # 输出每行数据为列表
处理动态内容
- 若HTML依赖JS渲染,需使用Selenium模拟浏览器:
from selenium import webdriver driver = webdriver.Chrome() driver.get("file:///path/to/example.html") # 本地文件路径 driver.execute_script("window.scrollTo(0, document.body.scrollHeight)") # 触发渲染 html = driver.page_source driver.quit()
- 若HTML依赖JS渲染,需使用Selenium模拟浏览器:
常见数据类型提取方法
| 数据类型 | 提取方式 |
|——————–|—————————————————————————–| | element.get_text(strip=True) 去除标签和空白字符 |
| 属性值 | element["attribute"] 或 element.get("attribute") |
| 表格数据 | 遍历<table>→<tr>→<td>,按行或列结构化存储 |
| 链接地址 | a.get("href"),需处理相对路径(如href="#"或/path) |
数据存储与格式化
| 存储格式 | 适用场景 | 示例代码 |
|---|---|---|
| CSV文件 | 表格型数据 | pandas.to_csv() 直接保存为逗号分隔文件 |
| JSON文件 | 嵌套结构或API兼容 | json.dump(data, indent=4) 格式化输出 |
| 数据库 | 大规模数据或持久化需求 | sqlite3库插入数据,支持SQL查询 |
问题与解答
问题1:如何处理HTML中动态加载的数据(如JavaScript生成的表格)?
- 解答:
- 使用Selenium模拟浏览器加载完整页面。
- 等待JS执行完成(如
time.sleep(2)或显式等待元素出现)。 - 提取渲染后的HTML源码进行解析。
问题2:HTML结构经常变化,如何提高代码稳定性?
- 解答:
- 优先使用稳定的唯一标识(如
id或class组合)定位元素。 - 增加异常处理(如
try-except)应对缺失标签。 - 定期维护解析逻辑,或使用更智能的定位方式(如XPath相对
- 优先使用稳定的唯一标识(如