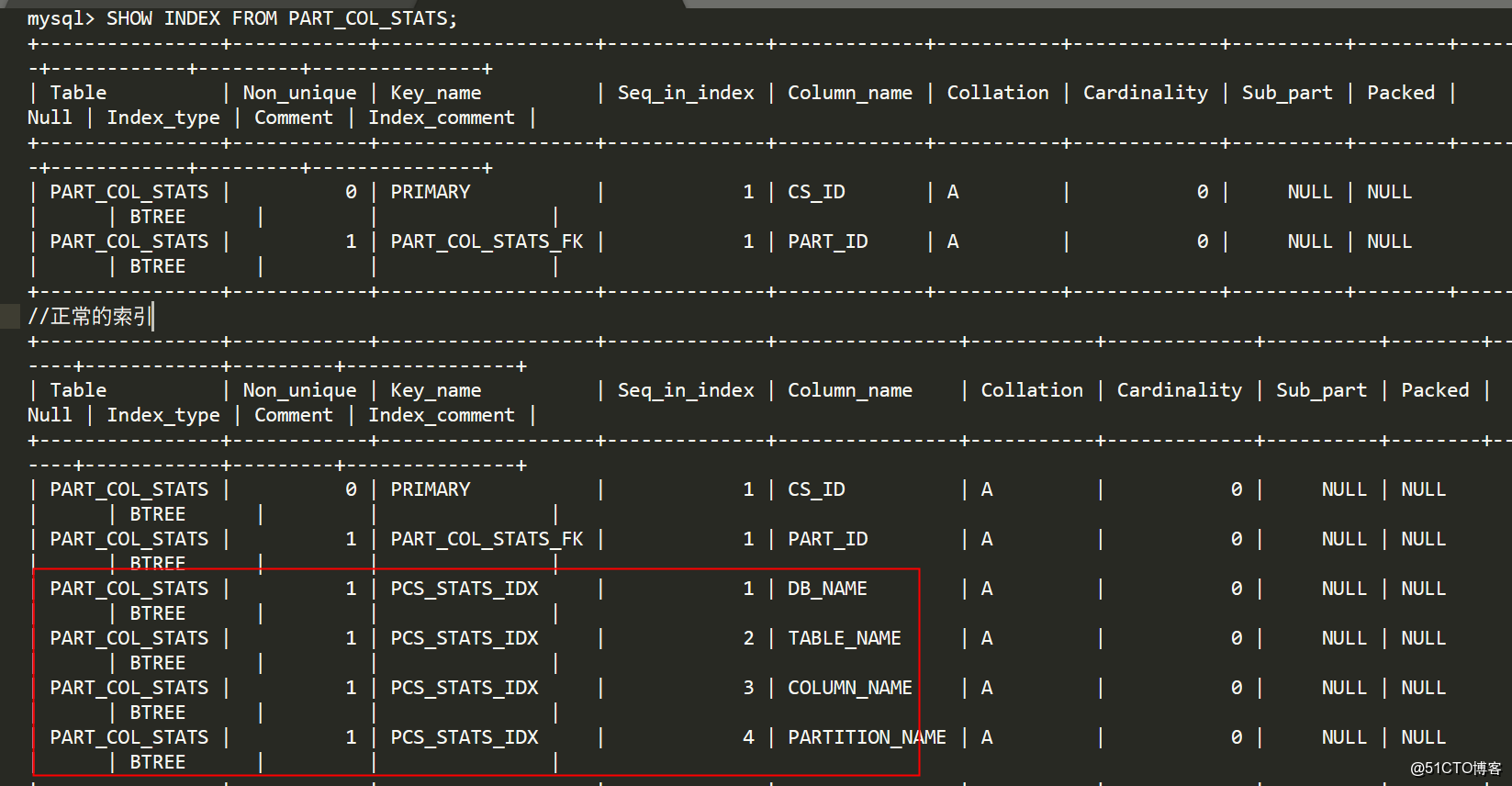
上一篇
hive的元数据存储
Hive元数据存储于RDBMS(如MySQL),含数据库、表结构等,数据存HD
Hive元数据存储机制详解
Hive元数据核心概念
Hive作为大数据领域的数据仓库工具,其核心功能是通过SQL-like语法实现对HDFS上数据的结构化处理,元数据(Metadata)作为Hive系统的核心组成部分,承担着以下关键职责:
| 元数据类型 | 描述 |
|---|---|
| 数据库信息 | 存储所有逻辑数据库的命名空间及配置 |
| 表结构定义 | 包含表名、列信息、分区策略、存储格式等核心元数据 |
| 分区信息 | 记录Hive表的分区字段及对应的HDFS目录结构 |
| 桶分布策略 | 管理基于哈希算法的数据分桶策略及对应文件路径 |
| 数据索引 | 维护索引结构定义及物理存储位置映射 |
| 权限控制 | 存储用户/组对数据库对象的访问权限配置 |
| 事务管理 | 记录ACID事务相关的操作日志及状态信息(仅启用事务表时存在) |
元数据存储演进历程
Hive在不同发展阶段采用了不同的元数据存储方案:
初始阶段(0.x版本)
- 使用内嵌式Derby数据库存储元数据
- 特点:开箱即用、单文件存储、适合测试环境
- 限制:不支持多客户端并发、单点故障风险、性能瓶颈明显
企业级应用阶段(1.x+版本)
- 支持外部关系型数据库(MySQL/PostgreSQL/Oracle等)
- 关键改进:
- 水平扩展能力
- ACID事务支持基础
- 元数据服务高可用架构
- 细粒度权限管理
云原生阶段(2.x+版本)
- 增加对AWS Glue、Azure Synapse等云托管元数据服务的支持
- 支持混合存储模式(本地+云端)
元数据存储实现机制
默认存储方案(Embedded Derby)
<!-hive-site.xml 配置示例 --> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:derby:;databaseName=metastore_db;create=true</value> </property>
技术特性:

- 嵌入式数据库,无需独立部署
- 单文件存储(.metastore_db/目录下)
- 基于Apache Derby实现
- 适用场景:单机测试/开发环境
局限性:
- 单进程访问限制
- 最大连接数限制(默认16)
- 无原生高可用机制
- 元数据规模受限(建议<100万表对象)
生产级存储方案(外部RDBMS)
推荐配置参数:
<property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://metastore_host:3306/hive_metastore?useSSL=false</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>metastore_user</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>secure_password</value> </property>
数据库架构规范:
- 必须包含专用管理员用户(推荐三权分立:DBA/MetastoreAdmin/HiveUser)
- 建议使用InnoDB引擎(支持事务)
- 关键表结构:
VERSION:集群版本控制DATABASE_PARAMS:数据库级参数配置TABLE_PARAMS:表级参数配置DDL_STORE:存储DDL语句历史PARTITIONS:分区元数据SKEIDS:桶分布信息FIELDS:列定义信息
性能优化建议:
- 建立索引:
CREATE INDEX idx_db_name ON DATABASE_PARAMS(DB_NAME); CREATE INDEX idx_table_name ON TABLES(NAME);
- 配置连接池参数:
<property> <name>hive.metastore.client.socket.timeout</name> <value>600s</value> </property>
- 定期VACUUM清理(针对PostgreSQL)
元数据服务架构演进
单点架构(基础模式)
+---------------------+
| Hive Metastore |
| (Single JVM Process)|
+----------+----------+
|
| JDBC
|
+----------v----------+
| External RDBMS |
| (MySQL/PostgreSQL) |
+---------------------+高可用架构(HA模式)
+----------------+ +----------------+
| Metastore A | | Metastore B |
| (Active) | | (Standby) |
| JVM实例 | | JVM实例 |
+----------------+ +----------------+
/
/
/
/
+---+---+
|
Shared RDBMS (集群模式)实现要点:
- 使用ZooKeeper进行主备选举
- 配置参数:
<property> <name>hive.metastore.ha.uris</name> <value>thrift://metastore1:10001,thrift://metastore2:10001</value> </property>
- 需要启用事务性RDBMS(如MySQL InnoDB)
- 建议部署至少3个Metastore节点(防止脑裂)
元数据管理关键操作
初始化数据库
# 使用MySQL示例 mysql -u root -p -e "CREATE DATABASE hive_metastore;" mysql -u root -p hive_metastore < hive-schema-3.2.0.mysql.sql
版本升级处理
- 执行SQL脚本:
schematool -dbType mysql -initSchema - 注意:跨版本升级需验证DDL兼容性
元数据备份恢复
备份方法:
# 使用mysqldump(以MySQL为例) mysqldump -u metastore_user -p --routines hive_metastore > metastore_backup_$(date +%F).sql
恢复流程:
mysql -u root -p hive_metastore < metastore_backup.sql # 修复Hive版本标记 mysql -u metastore_user -p hive_metastore -e "UPDATE VERSION SET VER='3.2.0' WHERE VER=3.1.2;"
权限同步机制
- Hive权限模型与RDBMS用户体系映射:
- Hive用户 -> RDBMS用户
- Hive角色 -> RDBMS角色
- 权限缓存刷新:
REFRESH_AUTHORIZATION命令
典型问题诊断
元数据锁表问题
症状:
- Beeline执行DDL超时
- Metastore日志出现”lock wait timeout”
- SHOW TABLES卡住
解决方案:
-检测阻塞会话(MySQL示例) SELECT FROM information_schema.INNODB_LOCKS; -终止阻塞进程 KILL <process_id>;
元数据库膨胀处理
诊断命令:
-查看表大小分布(MySQL示例) SELECT table_name, round(((data_length + index_length) / 1024 / 1024), 2) as size_mb FROM information_schema.TABLES WHERE table_schema = 'hive_metastore' ORDER BY size_mb DESC;
优化措施:
- 清理历史DDL记录(保留最近3个月)
- 压缩VARCHAR字段存储(如PARTITION_COMMENT)
- 归档冷数据(如超过1年的作业历史)
元数据安全最佳实践
| 安全维度 | 实施措施 |
|---|---|
| 传输加密 | 配置SSL连接(hive.metastore.sasl.enabled=true) |
| 审计日志 | 启用查询审计(hive.server2.audit.log.enabled=true) |
| 网络隔离 | Metastore服务部署在独立VPC,通过安全组限制访问 |
| 敏感数据加密 | 对存储密码字段的表启用透明数据加密(TDE) |
| 版本兼容 | 保持Hive客户端与Metastore数据库版本一致 |
| 灾备方案 | 异地RDBMS集群+定期增量备份(建议备份频率<=15分钟) |
FAQs
Q1:如何将元数据从Derby迁移到MySQL?
A1:迁移步骤如下:
- 准备目标MySQL实例并初始化Hive schema:
schematool -dbType mysql -initSchema - 导出Derby元数据(需停止Hive服务):
tar -cvf derby_metastore.tar metastore_db/ - 配置Hive连接新MySQL实例:修改
hive-site.xml中的JDBC连接参数 - 启动Hive Metastore服务,自动完成数据迁移验证
- 验证迁移结果:
SHOW DATABASES;检查原有数据库是否存在
Q2:生产环境中如何选择元数据库?
A2:决策要素包括:
- 性能需求:高并发场景推荐MySQL(InnoDB引擎),复杂事务选PostgreSQL
- 扩展性:支持主从复制的数据库(如MySQL GTID模式)便于水平扩展
- 生态兼容:已有Oracle环境可复用,云环境优先考虑云原生数据库(如AWS Aurora)
- 运维成本:开源方案优先MySQL/PostgreSQL,商业环境可选Oracle RAC