上一篇
Hive统一元数据管理
Hive通过Metastore集中管理表结构、分区及存储等元数据,实现跨集群数据一致性与高效访问,支撑多业务协同
Hive统一元数据管理详解
Hive元数据管理的核心概念
Hive作为大数据领域的分布式数据仓库,其核心功能之一是通过元数据(Metadata)管理数据资产,元数据包括数据库、表结构、分区信息、存储位置、权限配置等关键信息,统一元数据管理旨在通过集中化、标准化的方式维护这些信息,确保多用户、多集群环境下的数据一致性与可操作性。
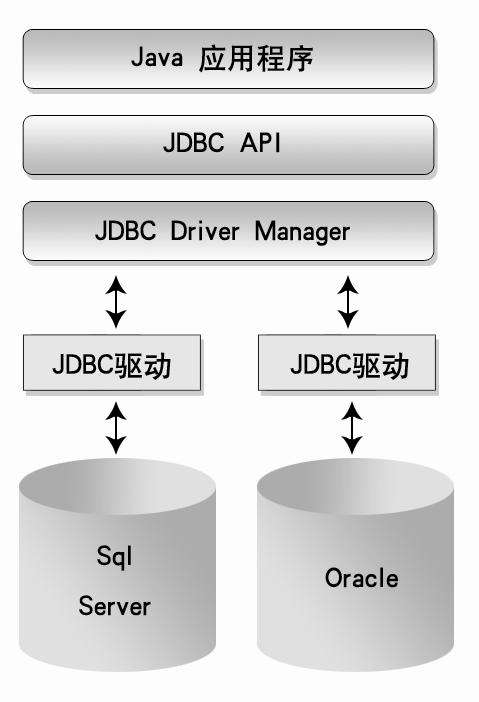
Hive Metastore架构解析
Hive的元数据存储在Metastore中,其架构设计直接影响元数据管理的效率与可靠性,以下是Metastore的核心组件与工作流程:
| 组件 | 功能描述 |
|---|---|
| Metastore服务 | 提供元数据的读写接口,支持SQL语法(如SHOW TABLES)和API调用。 |
| 后端存储 | 默认使用关系型数据库(如MySQL、PostgreSQL)存储元数据,也支持其他兼容JDBC的数据库。 |
| 客户端缓存 | Hive客户端本地缓存元数据(如.hiverc文件),减少对Metastore的频繁访问。 |
| 权限管理器 | 基于角色的访问控制(RBAC),管理用户对数据库、表、分区的权限。 |
工作流程示例:
- 用户提交
CREATE TABLE语句。 - Hive客户端将DDL转换为Metastore的SQL操作(如INSERT到
TABLES表)。 - Metastore更新元数据并持久化到后端数据库。
- 客户端同步缓存,后续查询直接从缓存读取元数据。
统一元数据管理的挑战与解决方案
在大规模企业环境中,Hive元数据管理面临以下典型问题:
| 挑战 | 解决方案 |
|---|---|
| 单点故障风险 | 部署高可用(HA)Metastore,例如通过ZooKeeper实现主备切换或采用数据库集群(如MySQL Group Replication)。 |
| 跨集群元数据不一致 | 使用中央化Metastore服务,所有Hive集群共享同一Metastore实例。 |
| 版本兼容性问题 | 升级Hive版本时,需同步升级Metastore数据库Schema,并通过SCHEMA_VERSION表管理版本。 |
| 元数据性能瓶颈 | 优化Metastore后端数据库(如添加索引、分库分表),或启用Hive的元数据缓存(hive.metastore.cache.pinned)。 |
案例:跨集群元数据共享
某企业拥有多个Hive集群(如开发、测试、生产环境),通过配置所有集群指向同一个Metastore,实现:

- 元数据全局一致,避免重复建表。
- 数据团队可跨集群查询同一表(需配置HDFS路径映射)。
- 统一权限管理,降低运维复杂度。
元数据高可用性方案对比
以下是两种常见高可用方案的对比:
| 方案 | 架构特点 | 优点 | 缺点 |
|---|---|---|---|
| Metastore主备模式 | 一个活跃Metastore + 一个热备节点,通过ZooKeeper选举。 | 部署简单,依赖成熟工具链。 | 主备切换期间可能存在短暂不可用。 |
| 数据库集群模式 | Metastore后端使用MySQL/PostgreSQL集群(如InnoDB Cluster)。 | 数据库层高可用,无单点故障。 | 配置复杂,需调优数据库参数。 |
推荐实践:
- 生产环境优先选择数据库集群模式(如MySQL Galera Cluster)。
- 启用Metastore日志持久化(
hive.metastore.event.db.listener),便于故障回滚。
元数据备份与恢复策略
元数据丢失可能导致业务中断,需定期备份Metastore数据库,以下是关键步骤:
备份方式:
- 直接备份Metastore后端数据库(如使用
mysqldump导出MySQL数据)。 - 通过Hive的
REPLACE TABLE语法导出元数据(需停止写入操作)。
- 直接备份Metastore后端数据库(如使用
恢复流程:
- 恢复数据库到Metastore实例。
- 重启Hive服务,验证元数据完整性(如
SHOW TABLES)。 - 若启用缓存,需清理客户端缓存文件(如
.hiverc)。
自动化工具:
- 使用Apache Atlas或自定义脚本集成备份任务。
- 结合HDFS快照功能,保护表数据与元数据的一致性。
元数据版本控制与审计
Hive的VERSION表记录了Metastore的Schema变更历史,支持版本回滚,可通过以下方式增强元数据治理:
- 变更审计:
开启Metastore审计日志(hive.metastore.audit.log.enabled=true),记录所有DDL操作。 - 字段级血缘追踪:
集成Apache Atlas,捕获表字段的上下游依赖关系。 - Schema演进:
使用ALTER TABLE添加兼容列(如新增可选字段),避免破坏现有查询。
典型应用场景与优化建议
| 场景 | 优化建议 |
|---|---|
| 多租户环境 | 为不同租户创建独立数据库,通过ROW LEVEL SECURITY控制数据可见性。 |
| 频繁DDL操作 | 启用Metastore缓存(hive.metastore.client.socket.timeout调优),减少数据库压力。 |
| 混合存储引擎 | 通过TRANSACTIONAL表支持ACID,结合EXTERNAL表管理外部数据源元数据。 |
FAQs
Q1: 如何配置Hive Metastore高可用?
A1:
- 选择高可用方案(如MySQL Group Replication或ZooKeeper主备)。
- 修改
hive-site.xml,配置Metastore连接字符串为集群地址(如jdbc:mysql://cluster-host:port/metastore)。 - 部署ZooKeeper(如需),并配置
hive.zookeeper.quorum参数。 - 重启Hive服务,验证Metastore状态(
SHOW DB EXTENDED)。
Q2: Metastore元数据出现不一致如何解决?
A2:
- 检查版本冲突:对比
VERSION表中的SCHEMA_VERSION与当前Hive版本的兼容性。 - 强制刷新元数据:执行
MSCK REPAIR TABLE <table>修复分区元数据。 - 重建缓存:删除客户端缓存文件(如
~/.hiverc),重新连接Metastore。 - 日志排查:查看Metastore日志(通常位于
/var/log/hive/),定位错误