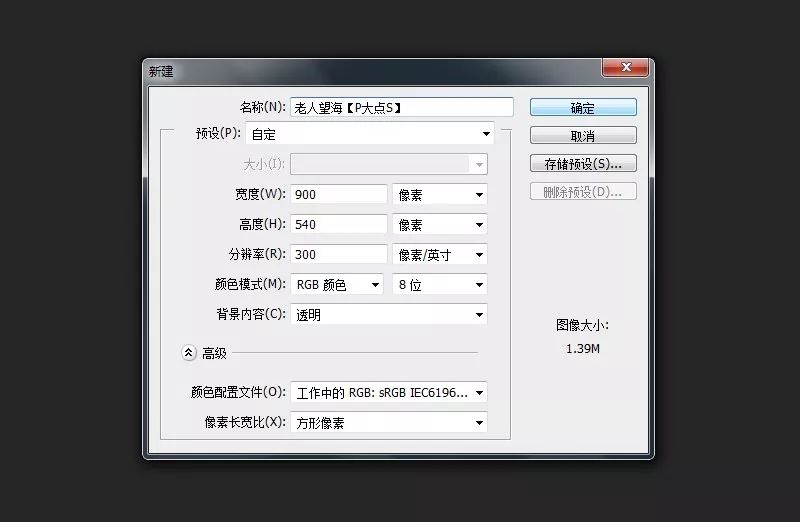
上一篇
java 多种文件转pdf文件怎么打开
va转PDF后可用Web应用嵌入iframe/object标签或pdf.js库在线打开,支持跨设备浏览
Java中实现多种文件格式转换为PDF并打开查看是一个常见的需求,涉及多个技术栈和工具的选择,以下是详细的实现方案及步骤说明:
主流转换工具与适用场景
| 文件类型 | 推荐库/工具 | 特点与优势 |
|---|---|---|
| Word (doc/docx) | Apache POI + iTextPDF | POI解析文档结构,iText负责排版渲染;支持复杂样式保留 |
| Excel (xls/xlsx) | Apache POI + iTextPDF | 可提取表格数据并重构为PDF中的表格对象,需处理跨页断点逻辑 |
| PowerPoint (ppt/pptx) | OpenOffice命令行工具+Java调用 | 利用OpenOffice原生导出能力,适合保留动画效果的场景 |
| HTML | iText html2pdf模块 / PD4ML | iText支持CSS样式转换,PD4ML对中文字体兼容性更优 |
| 纯文本(txt) | PDFBox基础API | 直接流式写入,适合简单文本结构化需求 |
具体实现方法详解
Office文档转换(以Word为例)
通过组合使用Apache POI和iTextPDF实现:
// 读取Word内容示例(POI部分)
XWPFDocument doc = new XWPFDocument(new FileInputStream("input.docx"));
List<XWPFParagraph> paragraphs = doc.getParagraphs();
StringBuilder content = new StringBuilder();
for (XWPFParagraph p : paragraphs) {
content.append(p.getText()).append("n");
}
// 创建PDF(iText部分)
try (PDDocument pdfDoc = new PDDocument()) {
PDPage page = new PDPage();
pdfDoc.addPage(page);
PDPageContentStream stream = new PDPageContentStream(pdfDoc, page);
stream.setFont(PDType1Font.HELVETICA, 12);
stream.showText(content.toString());
stream.close();
pdfDoc.save("output.pdf");
}
注意:此方案需要处理图片嵌入、分栏等复杂布局时,建议采用docx4j等增强型解析器。
HTML转PDF方案对比
| 方案 | 实现难度 | 功能完整性 | 中文支持 | 推荐指数 |
|---|---|---|---|---|
| iText html2pdf | 支持大部分标签 | 需配置字体映射 | ||
| PD4ML | 接近浏览器渲染效果 | 内置中文优化 | ||
| Flying Saucer | XSL-FO转换机制 | 较差 |
典型iText实现代码:
import com.itextpdf.html2pdf.HtmlConverter;
// ...
HtmlConverter.convertToPdf(new FileInputStream("template.html"), new FileOutputStream("result.pdf"));
若遇中文乱码问题,可在PD4ML中通过配置文件指定字体路径:

# pd4fonts.properties # 定义中文字体映射关系 simhei=STSongStd-Light,0,GBK
基于OpenOffice的服务化转换
适用于企业级批量处理场景:
# 启动Headless模式服务 soffice -headless -accept="socket,host=127.0.0.1,port=8100;urp;" -nofirststartwizard
Java端通过ProcessBuilder调用转换命令:
ProcessBuilder pb = new ProcessBuilder("/usr/bin/soffice",
"--headless", "--convert-to", "pdf:writer_Export",
inputPath, "-outdir", outputDir);
pb.start(); // 返回进程ID用于状态监控
优势在于支持所有Office格式统一转换入口,但依赖本地安装的OpenOffice环境。
PDF查看实现方案
方案A:本地桌面应用集成
使用PDFBox进行页面渲染:
PDDocument document = PDDocument.load(new File("report.pdf"));
PDFRenderer renderer = new PDFRenderer(document);
BufferedImage image = renderer.renderImageWithDPI(0, 300); // DPI控制清晰度
ImageIO.write(image, "PNG", new File("page1.png"));
该方式适合需要逐页处理或添加水印的场景。
方案B:Web应用在线预览
前端组合方案:
- 传统方案:使用
<iframe src="download?file=xxx.pdf">配合浏览器插件 - 现代方案:集成pdf.js库实现无插件浏览
<canvas id="pdfCanvas"></canvas> <script src="https://cdnjs.cloudflare.com/ajax/libs/pdf.js/2.11.339/pdf.min.js"></script> <script> const url = 'files/sample.pdf'; pdfjsLib.getDocument(url).promise.then(function(pdf) { pdf.getPage(1).then(function(page) { var scale = 1.5; var canvas = document.getElementById('pdfCanvas'); var context = canvas.getContext('2d'); canvas.height = page.view[2] scale; canvas.width = page.view[1] scale; page.render({canvasContext: context, transform: [scale,0,0,scale]}); }); }); </script>后端可通过Spring Boot提供REST接口:
@GetMapping("/pdf/{filename}") public ResponseEntity<Resource> getPdf(@PathVariable String filename) { File file = new File(PDF_STORAGE_PATH + "/" + filename); return ResponseEntity.ok().header(HttpHeaders.CONTENT_DISPOSITION, "attachment; filename=""+filename+""").body(new FileSystemResource(file)); }
性能优化策略
- 内存管理:大文件处理采用分块读取策略,避免一次性加载全部内容到内存
- 缓存机制:对频繁访问的PDF建立二级缓存(Ehcache/Redis)
- 异步处理:使用CompletableFuture实现后台转换任务队列
- 集群部署:高并发场景下采用微服务架构分散负载
安全注意事项
- 输入验证:限制上传文件类型和大小,防止反面文件执行
- 沙箱隔离:转换过程在独立ClassLoader中运行
- 权限控制:基于RBAC模型设计API访问权限体系
- 日志审计:记录所有转换操作供事后追溯
FAQs
Q1: 为什么转换后的PDF排版错乱?
A: 主要由于原始文档的复杂样式(如嵌套表格、浮动图片)导致,解决方案包括:①优先使用OpenOffice间接转换;②手动调整iText的字体回退机制;③启用iText的自动布局引擎(autoLayout = true),对于特殊版式建议先转为中间格式(如ODF)。
Q2: 如何处理加密的PDF文件?
A: 使用iText的解密功能:
PdfReader reader = new PdfReader("encrypted.pdf", new byte[]{userPassword});
// 后续操作与普通PDF相同
注意:PDFBox从2.0版本开始也支持标准加密算法解密,但无法破解高强度加密凭证,企业级应用建议集成LDAP