上一篇
html如何加载pdf文件内容不显示图片
HTML中用“标签加载PDF,若需隐藏图片,可通过JavaScript在加载后替换或移除图片元素实现
HTML中加载PDF文件内容时若不希望显示图片,可通过多种技术手段实现,以下是详细的解决方案及原理说明:
使用<embed>或<object>标签基础嵌入
最直接的方式是利用HTML原生标签加载PDF,并通过CSS控制其内部元素的可见性。
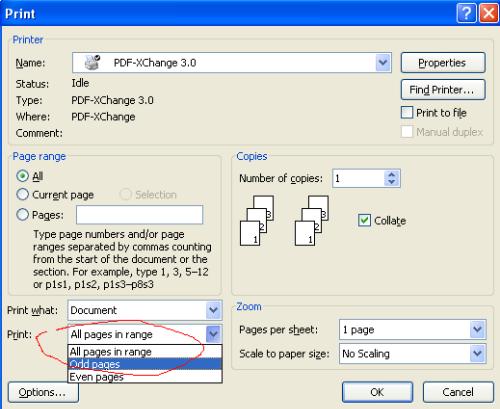
<embed src="example.pdf" type="application/pdf" style="width:100%;height:600px;"> <!-或者 --> <object data="example.pdf" type="application/pdf"></object>
默认情况下,浏览器会完整渲染PDF的所有内容(包括图片),要隐藏图片,需借助额外的样式干预,由于直接操作PDF内部结构较为复杂,通常需要结合JavaScript动态处理。
通过iframe+代理服务过滤内容
另一种思路是将PDF转换为中间格式(如HTML),再选择性地移除图片元素后展示文本,具体步骤如下:
- 后端预处理:使用工具(如Python的PyMuPDF库)解析原始PDF,提取纯文本并生成新的无图版本文档;
- 前端展示:将处理后的文本嵌入iframe中显示,此方法能彻底避免图片加载,但依赖服务器端的支持。
| 方法类型 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
<embed>+JS控制 |
纯前端实现,响应速度快 | 跨域限制可能导致失效 | 同源域名下的简单需求 |
| 代理服务转换 | 完全去除图片,兼容性好 | 增加开发和维护成本 | 复杂页面或跨域资源 |
JavaScript动态修改DOM节点
当PDF被嵌入为可交互对象时(例如通过PDF.js渲染),可以通过脚本遍历并隐藏所有图像元素,核心代码示例如下:
// 监听PDF加载完成事件
const pdfContainer = document.getElementById('pdfViewer');
pdfContainer.addEventListener('load', () => {
// 查找所有img标签并设置display:none
const images = pdfContainer.querySelectorAll('img');
images.forEach(img => {
img.style.display = 'none';
});
});
需要注意的是,不同PDF查看器对内部结构的封装差异较大,上述代码可能需要根据实际使用的库(如pdf.js)进行调整,某些安全策略可能会阻止脚本访问跨域加载的PDF内容。
配置PDF渲染参数抑制图片加载
部分第三方库允许在初始化时指定是否启用图像渲染功能,以jsPDF为例,创建文档时可设置autoTable等选项来跳过图片插入,但对于已存在的PDF文件,则需要先进行解析重组才能生效。
CSS覆盖层屏蔽法
如果仅需视觉上隐藏而非真正删除图片,可以使用绝对定位的半透明遮罩层覆盖整个PDF区域,同时保留文字可读性,这种方法实现简单但存在局限性:用户仍可通过开发者工具查看底层元素,且无法阻止网络请求中的图片数据传输。

注意事项与最佳实践
- 性能权衡:频繁操作DOM可能影响页面流畅度,建议优先测试低配设备的表现;
- 可访问性:确保屏幕阅读器能正常朗读文本内容,避免因移除图片导致信息缺失;
- 回退机制:为不支持JavaScript的环境准备备用方案,例如提示用户手动关闭图片显示;
- 法律合规:确认有权修改受版权保护的PDF文档内容。
FAQs
Q1: 为什么设置了display:none后图片仍然显示?
A: 可能是由于CSS优先级不足或PDF渲染引擎的特殊性导致样式未生效,尝试添加!important标记强制应用规则,或检查是否存在内联样式覆盖了外部样式表的定义,某些框架(如React)可能需要使用危险门帘(Dangerously Set Inline Styles)才能成功修改子节点属性。
Q2: 如何在不修改原PDF的情况下实现无图浏览?
A: 推荐采用前端动态过滤方案,使用PDF.js提供的API钩子函数拦截图像绘制过程,或者在PDF解析阶段替换占位符而非直接删除标签,这种方式既能保持源文件完整性,又能灵活适配不同的展示需求,对于商业项目,还可以考虑订阅专业的文档处理服务来实现高级定制化