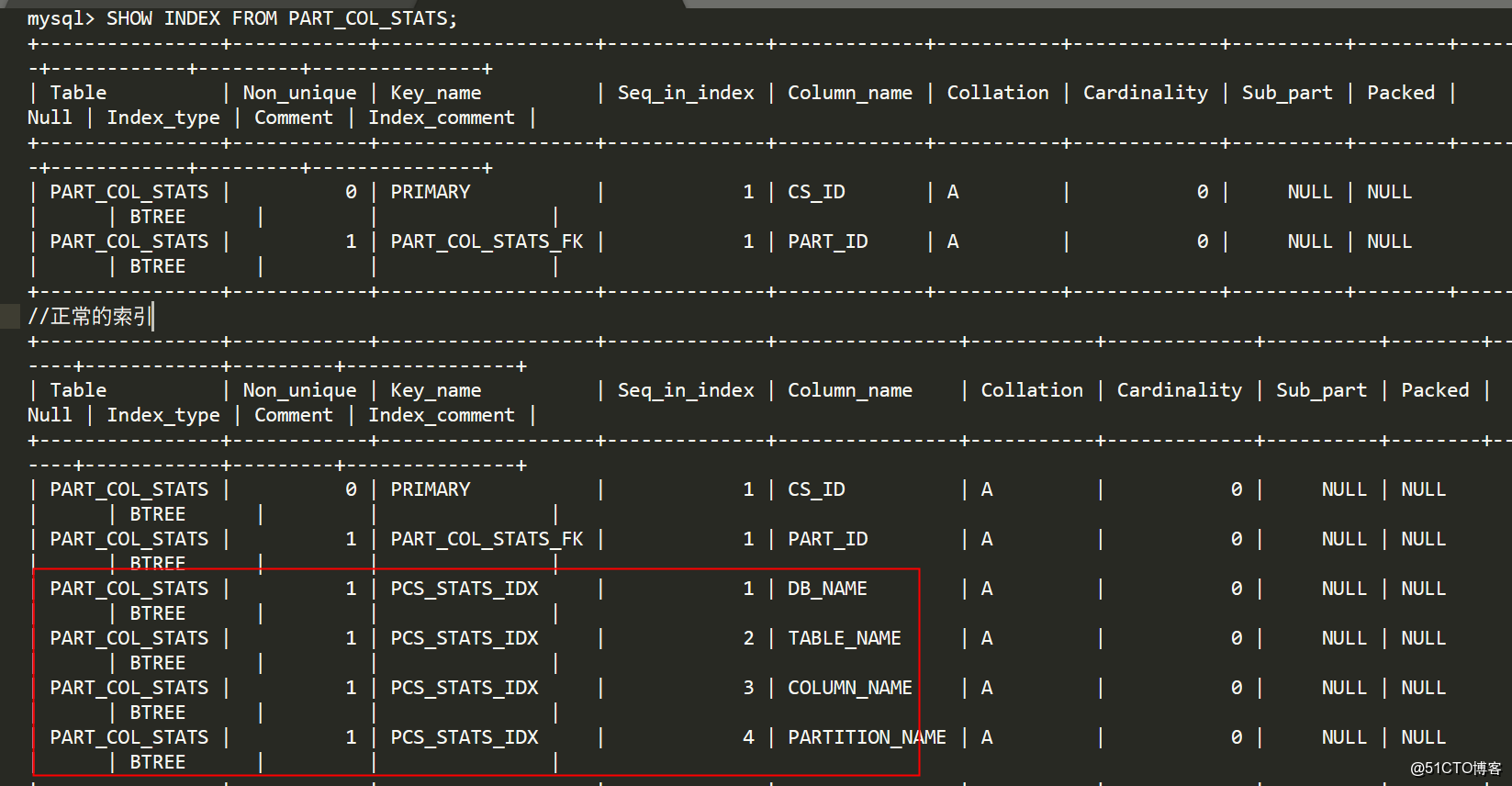
上一篇
hive的元数据存储在拿
Hive元数据默认存储在关系型数据库(如MySQL、PostgreSQL)中,由Metastore服务管理,具体配置通过hive-site.xml的javax.jdo.参数指定连接信息
Hive元数据存储机制详解
Hive架构与元数据核心作用
Apache Hive作为大数据领域的核心组件,其架构包含元数据存储层(Metastore)、查询编译层、执行引擎层和存储抽象层,其中元数据存储层承担着关键职责:
- 表结构定义:存储所有数据库、表、分区、列的Schema信息
- 数据位置映射:记录HDFS文件路径与分区的对应关系
- 权限管理:保存用户权限配置和访问控制列表
- 统计信息:维护表的行数、文件大小等优化查询的元数据
- 事务日志:记录ACID事务操作历史(Hive 2.x+)
元数据存储模式深度解析
Hive支持多种元数据存储方案,不同模式在性能、可靠性和管理复杂度上存在显著差异:
| 模式类型 | 存储后端 | 典型用途 | 并发支持 | 持久化能力 |
|---|---|---|---|---|
| 内嵌模式(Embedded) | Apache Derby嵌入式数据库 | 开发测试、单节点环境 | 低 | |
| 独立模式(Standalone) | 文件系统数据库(SQLite/PostgreSQL) | 小集群过渡方案 | 中 | |
| 外部数据库模式 | MySQL/PostgreSQL/Oracle | 生产环境主流方案 | 高 | |
| 云原生模式 | AWS Glue/Azure Metastore | 云平台集成场景 | 极高 |
内嵌模式(Embedded Mode)
- 实现原理:使用Apache Derby内存数据库,元数据存储在
$HIVE_HOME/metastore_db目录 - 配置文件:
hive-site.xml中设置hive.metastore.uris为thrift://localhost:9083 - 典型特征:
- 单节点独占访问,不支持多客户端并发
- 元数据存储与Hive进程共存亡
- 适合快速原型验证(PoC)
- 局限性:
- 无法支持多实例协调
- 重启后元数据易失(未持久化)
- 最大连接数限制为1
独立模式(Standalone Mode)
- 实现原理:通过Thrift API将Metastore服务化,支持远程访问
- 存储选项:
- 默认使用SQLite(
metastore_db/database.sqlite) - 可切换PostgreSQL(需配置JDBC驱动)
- 默认使用SQLite(
- 部署优势:
- 解耦元数据服务与Hive客户端
- 支持基础的横向扩展(读扩展)
- 适合中小集群过渡方案
- 配置要点:
<property> <name>hive.metastore.uris</name> <value>thrift://metastore-server:9083</value> </property>
外部数据库模式(External DB Mode)
- 生产级方案:推荐使用企业级关系数据库(MySQL/PostgreSQL/Oracle)
- 部署架构:
graph TD A[Hive Client] --> B{Metastore Service} B --> C[MySQL/PostgreSQL] C --> D[(HDFS/S3)] - 关键配置:
<property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://metastore-db:3306/hive_metastore?createDatabaseIfNotExist=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property>
- 优势对比:
- 支持多并发客户端(>100)
- 提供ACID事务保证
- 方便实施高可用方案(主从/集群)
云原生模式(Cloud-native Mode)
- AWS Glue集成:
- 自动同步元数据到AWS Glue Data Catalog
- 支持跨账户共享元数据
- 配置示例:
# Glue SDK配置片段 glue_context = GlueContext(SparkContext.getOrCreate()) glue_context.create_database(Database={'Name': 'default'})
- Azure Synapse集成:
- 使用专用Metastore服务端点
- 自动管理ADLS Gen2存储关联
元数据存储演进路线图
随着Hive版本迭代,元数据存储方案持续进化:

- Hive 1.x:仅支持内嵌模式和基础独立模式
- Hive 2.x:引入ACID事务,强化外部数据库支持
- Hive 3.x:优化云存储接口,增强Kubernetes部署支持
- Hive 4.x:预计深化Serverless架构支持
生产环境最佳实践
高可用配置:
- 使用MySQL Group Replication搭建Metastore集群
- 配置读写分离(readonly replica)
- 启用事务隔离级别
REPEATABLE READ
性能调优:
- 创建索引:
CREATE INDEX idx_tab ON TBLS(TBL_NAME) - 分区表优化:按业务维度建立分区索引
- 缓存配置:
hive.metastore.warehouse.cache.size=512MB
- 创建索引:
安全加固:
- 启用SSL加密通信:
hive.metastore.sasl.enabled=true - 细粒度权限控制:
GRANT SELECT ON TABLE db.table TO user - 审计日志:
hive.metastore.event.db.listener.impl=org.apache.hadoop.hive.metastore.events.EventListenerDB
- 启用SSL加密通信:
元数据迁移方案对比
| 迁移类型 | 工具支持 | 适用场景 | 风险等级 |
|---|---|---|---|
| 同构数据库迁移 | mysqldump/pg_dump | 版本升级、主从切换 | 低 |
| 异构数据库迁移 | SQuirreL SQL Client | MySQL→PostgreSQL等跨平台迁移 | 中 |
| 云服务迁移 | AWS DMS/Azure DSC | On-premises→Cloud | 高 |
常见问题诊断指南
症状1:FAILED: HiveException org.apache.hadoop.hive.metastore.api.MetaException: Unable to connect to the metastore
- 可能原因:
- Metastore服务未启动
- 网络防火墙阻断9083端口
- JDBC连接字符串配置错误
- 排查步骤:
- 检查Metastore进程状态:
jps | grep HiveMetaStore - 验证网络连通性:
telnet metastore-server 9083 - 测试数据库连接:
mysql -h metastore-db -P 3306 -u hive_user -p
- 检查Metastore进程状态:
症状2:Table already exists异常频发
- 根因分析:
- 元数据缓存未及时更新
- 分布式环境下存在时序问题
- 解决方案:
- 强制刷新元数据缓存:
MSCK REPAIR TABLE table_name - 调整缓存失效时间:
hive.metastore.cache.pinned.object.timeout=3600(单位秒)
- 强制刷新元数据缓存:
FAQs
Q1:如何将内嵌模式元数据迁移到MySQL?
A1:需执行以下步骤:
- 停止Hive服务:
stop-all.sh - 导出Derby数据库:
java -jar lib/derbytools.jar -o export -s metastore_db dump.sql - 转换DDL语句:将DERBY语法转换为MySQL兼容格式(注意数据类型映射)
- 初始化MySQL数据库:
mysql -u root -p -e "CREATE DATABASE hive_metastore;" - 导入转换后的SQL:
mysql -u hive_user -p hive_metastore < converted.sql - 修改Hive配置指向新Metastore:更新
hive-site.xml中的JDBC连接参数 - 重启Hive并验证:
hive -e "SHOW DATABASES;"
Q2:生产环境中如何选择Metastore后端?
A2:决策需考虑以下维度:
- 并发需求:超过50+客户端建议使用MySQL/PostgreSQL
- 数据量:百万级表对象需企业级数据库支撑
- 高可用要求:采用MySQL主从或PostgreSQL流复制架构
- 云原生场景:优先使用AWS Glue/Azure Metastore服务
- 成本因素:开源