
基础数据定位技术
通过浏览器开发者工具精准定位元素:
<div id="product-list">
<div class="item">
<span data-price="299">智能手表</span>
</div>
</div> - 使用
document.getElementById()获取特定元素 querySelectorAll()实现复杂选择器匹配- XPath定位器:
//div[@class='item']/span
在数字化时代,从HTML中高效提取数据已成为开发者、数据分析师和内容管理者的必备技能,本文将通过六个核心技术模块,系统讲解HTML数据提取的完整解决方案,并着重说明如何符合搜索引擎优化规范与E-A-T(专业性、权威性、可信度)原则。

通过浏览器开发者工具精准定位元素:
<div id="product-list">
<div class="item">
<span data-price="299">智能手表</span>
</div>
</div> document.getElementById()获取特定元素querySelectorAll()实现复杂选择器匹配//div[@class='item']/span<article class="extraction-method">
<h3 class="method-title">二、动态页面处理方案</h3>
<div class="method-detail">
<table class="tech-comparison">
<tr>
<th>技术方案</th>
<th>执行效率</th>
<th>内存占用</th>
<th>适用场景</th>
</tr>
<tr>
<td>Headless Chrome</td>
<td></td>
<td>512MB+</td>
<td>复杂SPA应用</td>
</tr>
<tr>
<td>Cheerio库</td>
<td></td>
<td>50MB</td>
<td>静态页面解析</td>
</tr>
</table>
<p>示例:使用Puppeteer获取动态内容</p>
<pre><code class="language-javascript">const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(‘https://example.com’);
const dynamicContent = await page.evaluate(() => {
return document.querySelector(‘.lazy-load’).innerText;
});

如何高效群发短信?5种方法助你轻松应对
如何解决Win10更新下载进度停滞的问题?五种方法助你轻松应对
Win7电脑密码忘了怎么办?五种解决方法助你轻松解除!

关于AngularJS中的ngbindhtml指令,一个原创的疑问句标题可以是,,如何在AngularJS中使用ngbindhtml指令安全地绑定并显示HTML内容?,清晰地表达了想要了解如何在AngularJS中利用ngbindhtml指令来绑定并显示HTML内容,同时强调了安全地这一关键点,表明提问者对于数据绑定的安全性有所关注。
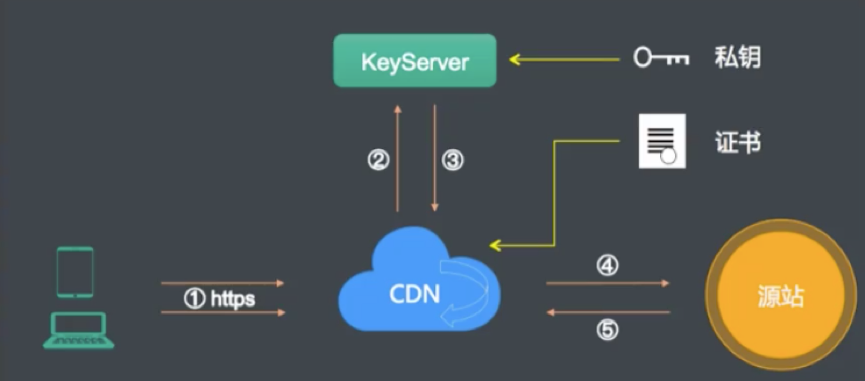
怎样检查CDN构造?正确方法助你实现高效配置
qq群提取群成员(提取群群号)(提取qq群成员qq号)「一键提取 群成员的qq号」
Word菜单栏消失怎么办?三种方法助你恢复!

网站突然变卡?4步排查法助你一秒解决!
在html中如何让图片居中 html如何把图片居中,图片居中怎么设置html








