上一篇
分布式架构数据库双11促销活动
分布式架构数据库双11特惠来袭,高并发、弹性扩展、稳定可靠,享折扣、套餐及技术支持,助力企业轻松应对流量高峰
分布式架构数据库在双11促销活动中的核心作用与实践
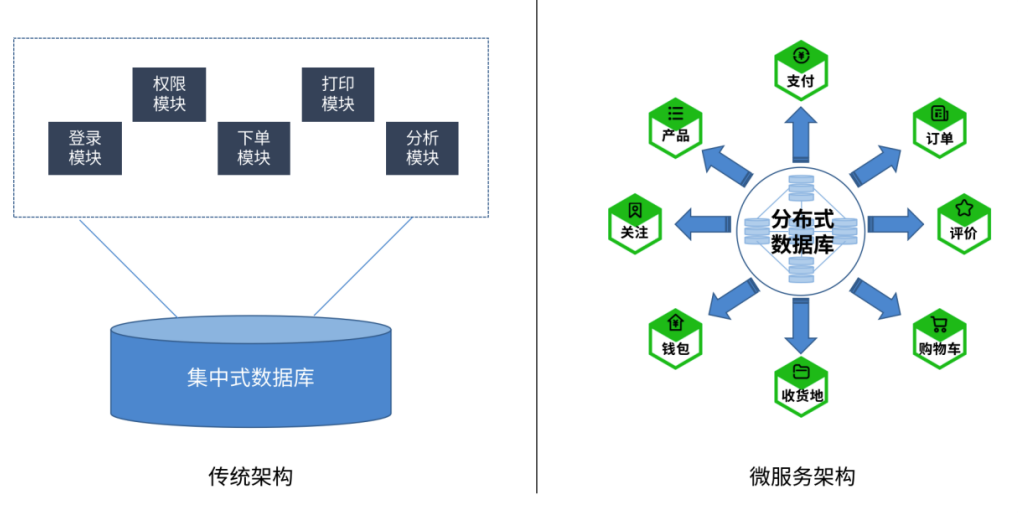
分布式架构数据库的必要性
在双11大促场景下,电商平台需应对每秒数十万次的交易峰值、亿级用户并发访问以及复杂的业务逻辑(如库存扣减、订单拆分、支付对账等),传统单体数据库的垂直扩展能力(如单机性能优化)已无法满足以下需求:
| 挑战 | 传统数据库瓶颈 | 分布式数据库优势 |
|---|---|---|
| 高并发读写 | 单机连接数受限,锁竞争激烈 | 水平扩展,支持多节点并行处理 |
| 海量数据存储 | 单机磁盘容量有限,扩展成本高 | 分片存储,线性扩展容量 |
| 复杂业务逻辑 | 事务处理延迟高,难以支持多级拆分 | 分布式事务、最终一致性保障 |
| 容灾与高可用 | 单点故障导致全站不可用 | 多副本冗余,自动故障转移 |
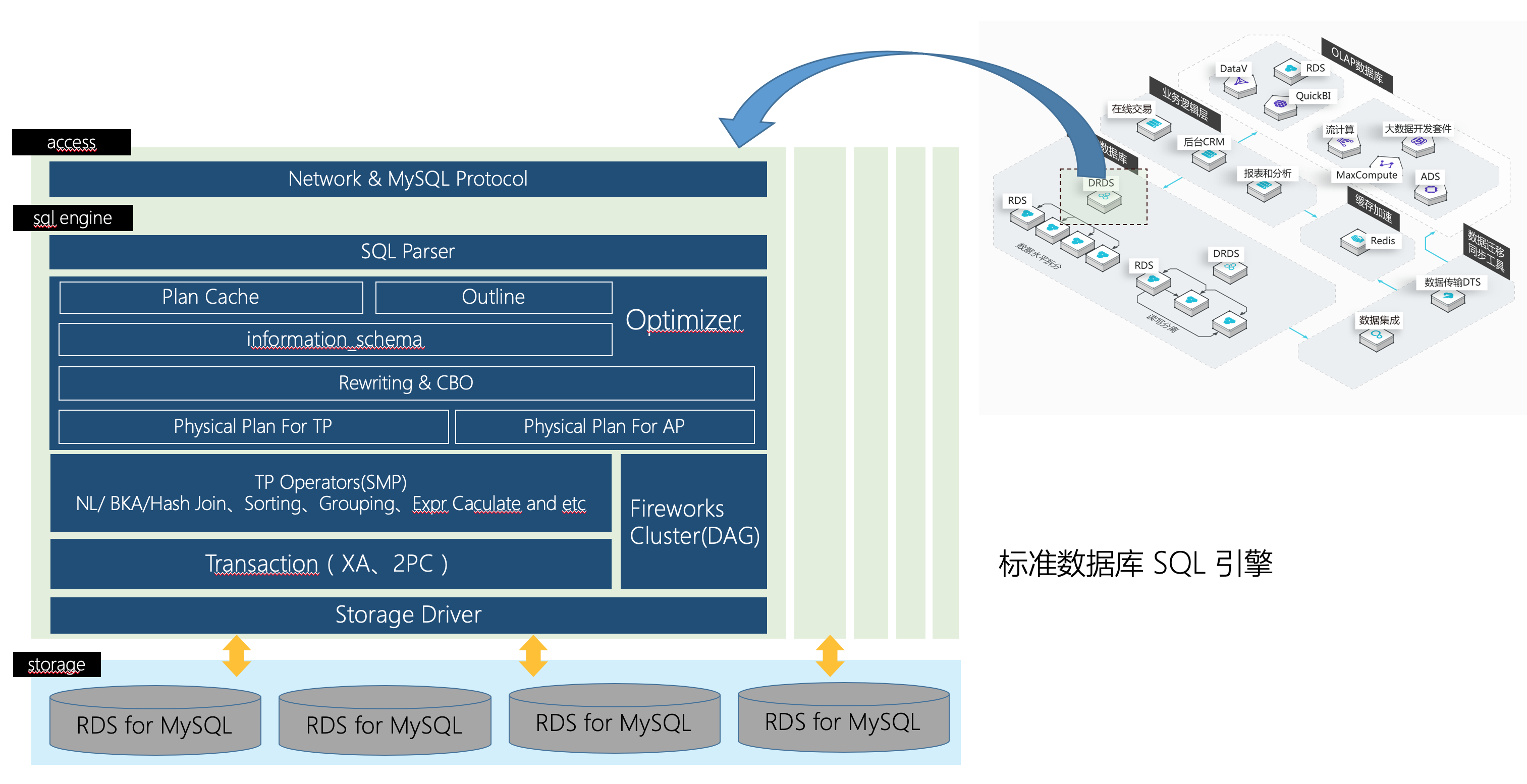
分布式架构数据库的核心组件与技术
分库分表
- 水平分片:按用户ID、订单ID等维度将数据分散到不同节点,避免单库压力过载。
- 用户表按
user_id % 4分片到4个库 - 订单表按
order_id % 8分片到8个库
- 用户表按
- Sharding策略:范围分片(如按时间)、哈希分片(如取模)、目录分片(如按业务类型)
- 水平分片:按用户ID、订单ID等维度将数据分散到不同节点,避免单库压力过载。
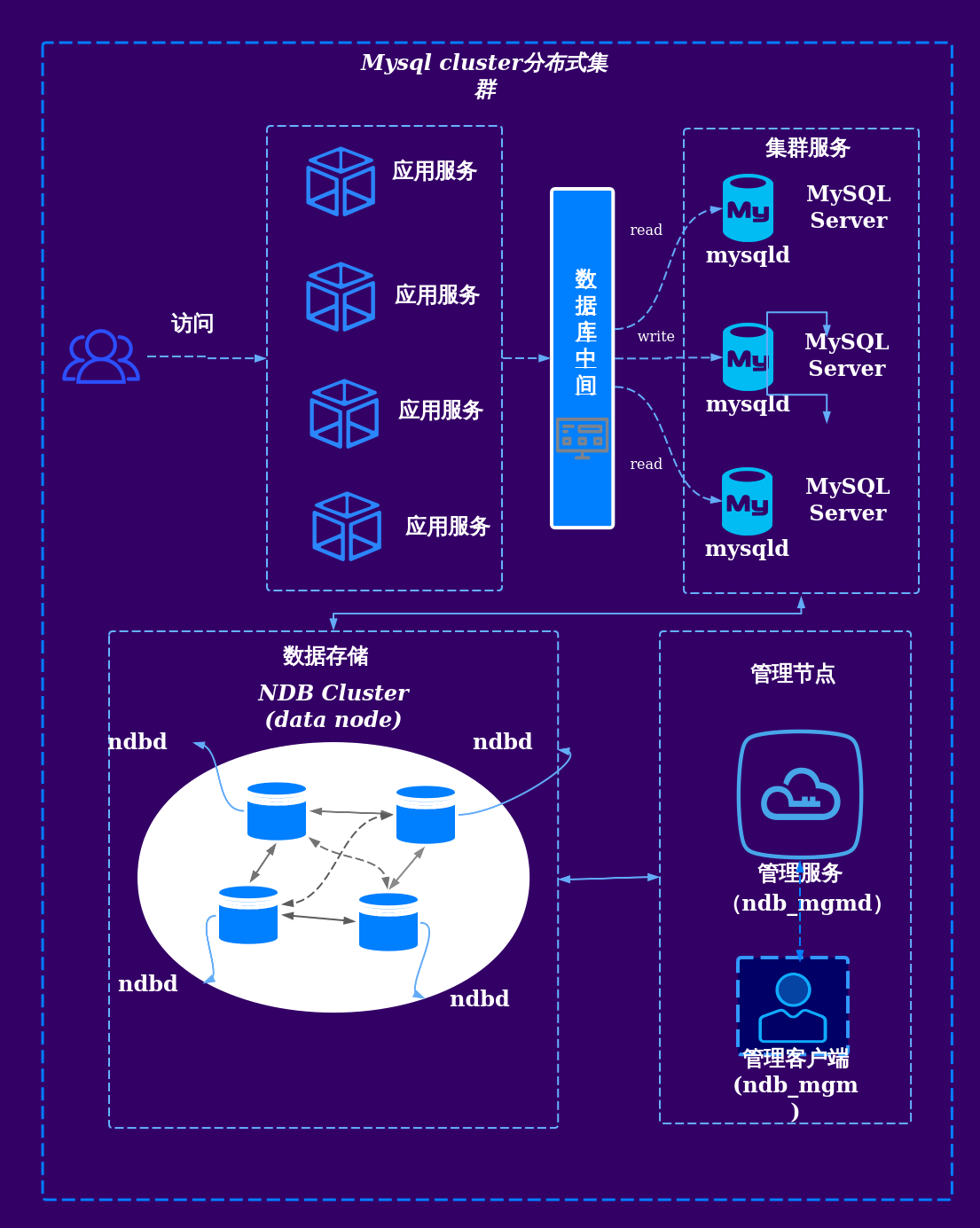
读写分离与负载均衡
- 主从复制:主库处理写操作(如订单创建),从库处理读操作(如商品查询)
- 动态路由:通过中间件(如MyCAT、ShardingSphere)实现SQL自动路由,隐藏分片逻辑
分布式事务管理

- 场景:跨库的库存扣减、优惠券抵扣、支付回调等
- 解决方案:
- TCC(Try-Confirm-Cancel):补偿式事务,适用于高并发场景
- XA协议:强一致性但性能损耗大,需谨慎使用
- 最终一致性:允许短暂数据不一致,通过异步对账修正
缓存与加速层
- 热点数据缓存:Redis集群缓存商品详情、库存状态,减少数据库压力
- 异步写入:订单日志、用户行为数据采用Kafka队列异步落库
双11典型业务场景与数据库设计
| 业务场景 | 数据库设计要点 |
|---|---|
| 商品瞬秒 | 独立库存表+Redis预扣减,避免超卖;限流策略(如令牌桶算法) |
| 订单拆分 | 订单表分片存储,拆单逻辑通过事务消息(如RocketMQ)异步处理 |
| 支付对账 | 支付记录与订单状态分离,通过定时任务(Flink/Spark)比对差异 |
| 实时大屏 | 聚合计算下沉到数据库层(如ES Cube),减少应用层压力 |
性能优化与容灾策略
索引优化
- 热点查询字段(如
promo_id)建立复合索引 - 避免全表扫描,使用覆盖索引(如
SELECT id, name FROM product WHERE category=?)
- 热点查询字段(如
参数调优
- 调整MySQL的
innodb_buffer_pool_size(占内存60%以上) - 设置合理的
max_connections(通常为CPU核心数×10)
- 调整MySQL的
容灾与多活
- 单元化部署:按地域划分数据中心,流量就近接入
- 数据复制:采用Paxos/Raft协议实现多活机房数据同步(如阿里DRDS)
- 故障演练:定期模拟主库宕机、网络分区等极端场景
实战案例参考
- 阿里巴巴:通过OceanBase分布式数据库支撑双11,采用AP与CP分离架构,交易库(TPCC模型)与分析库(OLAP模型)独立部署。
- 京东:使用TiDB处理弹性扩容需求,秒级完成千台节点扩缩容,支撑突发流量。
- 拼多多:基于Dubbo+ShardingSphere实现业务中台化,数据库层透明处理分片逻辑。
常见问题与避坑指南
Q1:分库分表后如何避免跨库JOIN?
- 解法:
- 业务层拆分查询,分两次查询后合并数据
- 冗余字段(如商品详情缓存到Redis)
- 使用中间表存储关联结果(如预聚合宽表)
Q2:如何应对分片键热点问题?
- 解法:
- 动态调整分片策略(如按哈希取模改为范围分片)
- 热点数据单独扩容(如对TOP100商品单独建库)
- 结合负载均衡算法(如一致性Hash)分散压力
FAQs
Q:分布式事务在双11场景下的优先级如何?
A:优先保证核心链路(如支付、库存)的强一致性,非核心业务可采用最终一致性,订单创建必须原子性,但用户积分发放可异步修正。
Q:如何评估数据库的扩容阈值?
A:监控关键指标:
- CPU使用率 >85%(持续1分钟)
- 磁盘IO延迟 >10ms
- 主库QPS >5万/秒
触发条件后自动扩容,扩容后需重新平衡数据