上一篇
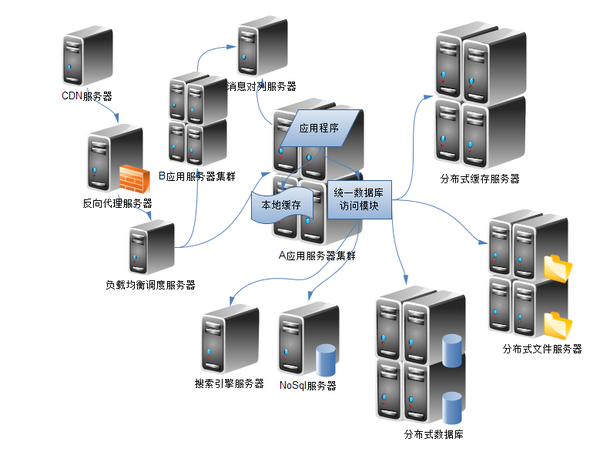
分布式服务器数据共享
分布式服务器通过主从复制、 分布式系统等技术实现数据共享,保障一致性与高可用,适用于
分布式服务器数据共享的核心原理与实践
基本概念与技术背景
分布式服务器数据共享是指通过网络将多台物理或虚拟服务器连接成集群,实现跨节点的数据访问与协同处理,其核心目标是在保证数据一致性、可用性和安全性的前提下,提升系统吞吐量和容灾能力,与传统单机存储相比,分布式架构需解决网络延迟、节点故障、数据冲突等复杂问题。
关键技术特征对比表
| 特性 | 传统集中式存储 | 分布式存储 |
|—————|———————–|————————–|
| 扩展性 | 垂直扩展(硬件升级) | 水平扩展(增加节点) |
| 单点故障 | 存在(全盘瘫痪风险) | 通过冗余机制规避 |
| 数据访问速度 | 依赖本地磁盘IO | 受网络带宽与协议影响 |
| 维护成本 | 低(单一系统管理) | 高(多节点协调) |

主流架构模式
- 主从复制架构
- 核心原理:选定主节点处理写操作,从节点同步数据并处理读请求
- 适用场景:读多写少的业务(如CDN缓存)
- 典型工具:MySQL主从复制、Redis主从架构
- 性能瓶颈:写操作受限于主节点性能,同步延迟可能导致数据短暂不一致
- 对等式(P2P)架构
- 核心原理:所有节点地位平等,数据分片存储
- 关键技术:一致性哈希算法分配数据片,Gossip协议传播状态
- 优势:无单点故障,自动负载均衡
- 挑战:复杂的数据定位机制,需处理跨节点事务
- 混合型架构
- 典型方案:基于Raft/Paxos协议的选举机制+数据分片
- 代表系统:Apache Cassandra、MongoDB Sharding
- 特点:兼顾扩展性与强一致性,通过投票机制保证元数据一致
核心技术组件
- 分布式一致性协议
- Paxos:理论最优但实现复杂,Google Chubby为其变种
- Raft:易理解性突出,Etcd/Consul采用此协议
- ZAB(ZooKeeper Atomic Broadcast):专为分布式协调设计
数据分片策略
| 分片方式 | 实现原理 | 适用场景 |
|————-|———————————|————————-|
| 哈希分片 | 按Key计算哈希值取模 | 键值存储系统 |
| 范围分片 | 按数值范围划分 | 时间序列数据库 |
| 目录分片 | 按文件目录结构划分 | 分布式文件系统 |
| 地理分片 | 按数据中心位置划分 | 全球化服务架构 |分布式文件系统
- HDFS:块存储+主从架构,适合批处理大数据
- Ceph:对象存储+CRUSH算法,支持动态扩展
- GlusterFS:POSIX兼容,通过挂载点实现透明扩展
关键挑战与解决方案
- CAP定理的权衡
- 一致性(Consistency):强一致性需牺牲可用性(如ZooKeeper)
- 可用性(Availability):允许临时不一致可提升服务能力(如DynamoDB)
- 分区容忍(Partition Tolerance):网络故障时维持服务
- 数据冲突解决机制
- 乐观锁:版本号控制(如Cassandra)
- 悲观锁:分布式事务(两阶段提交协议)
- 最终一致性:允许延时同步(如Amazon Dynamo)
- 网络延迟优化
- 数据就近存储:根据访问频率部署热点数据
- 异步复制:优先响应后批量同步(如Kafka日志系统)
- 压缩传输:使用Protobuf/MessagePack减少数据包大小
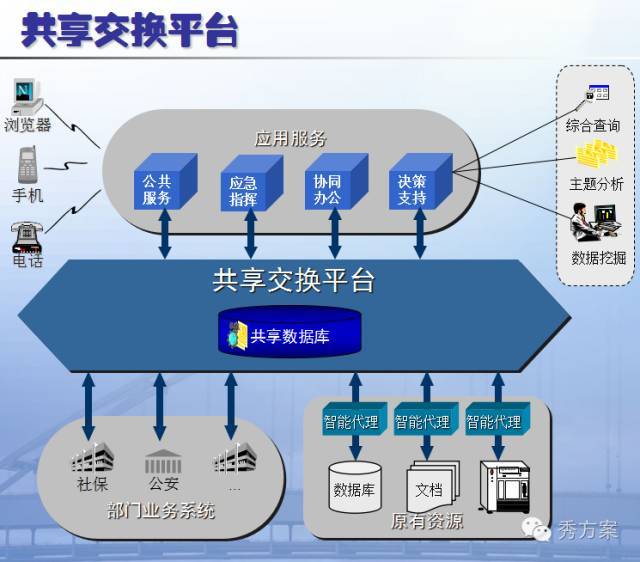
典型应用场景
- 电子商务平台
- 商品库存服务:多机房部署保证高可用
- 订单系统:分布式事务保证支付一致性
- 推荐系统:跨节点协同计算用户画像
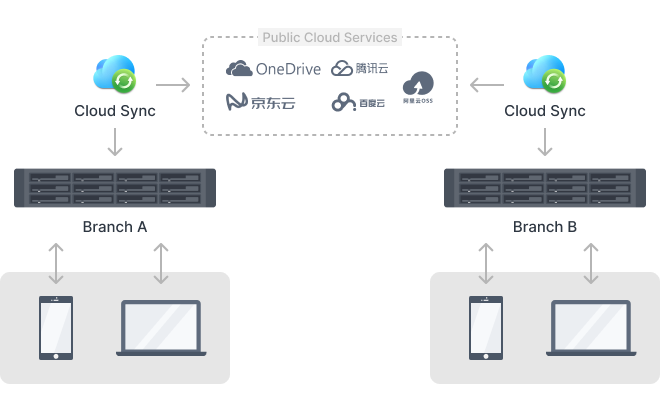
- 云计算服务
- 对象存储:AWS S3的全球分布式架构
- 弹性计算:Kubernetes调度容器跨节点运行
- 数据库服务:PolarDB的分布式SQL引擎
- 物联网领域
- 设备数据汇聚:边缘节点预处理+中心节点分析
- 实时监控:时空数据联合索引查询
- 规则引擎:跨设备状态联动控制
性能优化策略
- 读写分离设计
- 写操作:集中处理保证顺序性(如日志结构合并树LSM)
- 读操作:多副本并行查询(如ES分片查询)
- 缓存机制
- 本地缓存:Redis/Memcached加速热点访问
- 异地缓存:CDN节点缓存静态资源
- 计算缓存:Spark RDD持久化中间结果
- 负载均衡算法
- 轮询法:简单但不考虑节点负载差异
- 加权轮询:根据硬件配置分配权重
- 最少连接数:动态选择当前负载最小节点
- 哈希映射:保证会话粘性(如IP哈希)
安全与运维考量
- 数据加密方案
- 传输层:TLS 1.3+双向证书认证
- 存储层:AES-256全盘加密+密钥分片管理
- 应用层:字段级加密(如敏感信息掩码)
- 监控告警体系
- 基础指标:CPU/内存/磁盘IO/网络流量
- 业务指标:QPS/P99延迟/错误率/数据一致性校验
- 异常检测:时序数据分析(如Prometheus+Alertmanager)
- 灾难恢复方案
- 冷备份:定期快照+离线存储
- 热备份:PaaS平台实时增量备份(如阿里云HybridBackup)
- 多活架构:双/多中心同时提供服务
FAQs
Q1:分布式系统中如何降低数据同步延迟?
A1:可采用以下组合策略:
- 地理优化部署:将高频访问节点部署在相同地域
- 异步复制机制:允许短暂数据滞后(如Kafka的acks=1配置)
- 智能路由策略:基于访问模式预测数据流向(如Netflix的EdgeCache)
- 内存级缓存:使用Redis Cluster缓存最新变更数据
- 批量处理:将多个写操作合并为批处理(如Bulk API)
Q2:遇到节点故障时如何保证数据不丢失?
A2:需构建多层级防护体系:
- 数据冗余:至少3副本存储(如HDFS的默认配置)
- WAL日志:记录未持久化的操作(如MySQL的redo log)
- 心跳检测:每秒级健康检查(如ZooKeeper的session机制)
- 自动故障转移:通过Raft选举新主节点(如etcd的leader转移)
- 纠删编码:使用Reed-Solomon算法在存储效率与容错间平衡(如Ceph的