上一篇
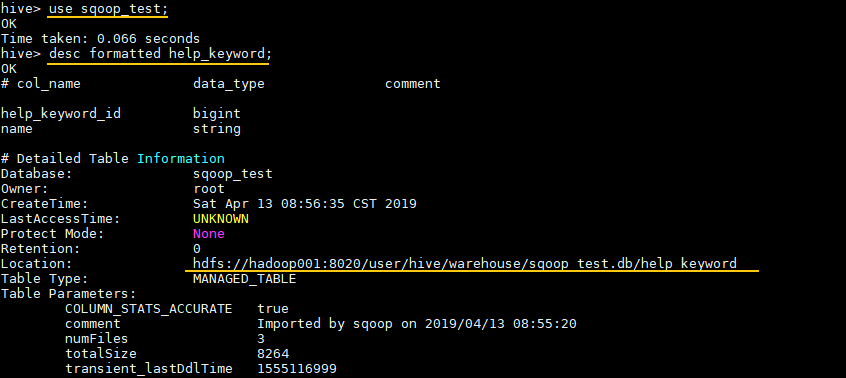
hive表存储数据
Hive表数据以文本或二进制格式(如ORC/Parquet)存储于HDFS,支持分区和桶策略,通过元 数据管理实现高效
Hive表存储数据详解
Hive作为基于Hadoop的数据仓库工具,其核心功能之一是通过表结构组织和管理大规模数据,Hive表的存储设计直接影响数据读写性能、存储效率及维护成本,以下从表类型、存储格式、数据组织方式、压缩策略等维度详细解析Hive表的存储机制。
Hive表类型与存储特性
Hive支持多种表类型,不同表类型的存储行为存在差异:
| 表类型 | 内部表(Managed Table) | 外部表(External Table) | 分区表(Partitioned Table) | 桶表(Bucketed Table) |
|---|---|---|---|---|
| 元数据管理 | 表和数据均由Hive管理 | 仅元数据由Hive管理,数据路径由用户指定 | 支持按字段分区,数据按分区目录存储 | 数据按哈希分配到指定数量的桶中 |
| 删除行为 | DROP TABLE会删除数据和元数据 | DROP TABLE仅删除元数据,保留数据 | 同内部表/外部表 | 同内部表/外部表 |
| 典型应用场景 | 临时数据或测试环境 | 跨系统共享数据(如HDFS与其他工具) | 按时间、地域等维度划分数据 | 均匀分布数据以提升查询效率 |
示例:创建外部表
CREATE EXTERNAL TABLE user_logs ( uid STRING, event STRING, timestamp BIGINT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY 't' LOCATION '/data/external/user_logs/';
存储格式与文件类型
Hive支持多种存储格式,不同格式在性能、压缩率、功能支持上差异显著:
| 存储格式 | 文件类型 | 是否支持压缩 | 是否支持ACID | 典型用途 |
|---|---|---|---|---|
| TextFile | 无格式纯文本 | 否 | 否 | 简单日志、CSV导入导出 |
| SequenceFile | 二进制序列化文件 | 支持(Block压缩) | 否 | 中等规模数据,兼容旧版Hadoop生态 |
| ORC | 优化列式存储 | 支持(轻量级压缩) | 是(需开启事务) | 大数据分析、复杂查询场景 |
| Parquet | 列式存储+嵌套结构 | 支持(高效压缩) | 是(需开启事务) | 机器学习、实时分析、多维查询 |
| Avro | Schema演化支持 | 支持(Deflate/Snappy) | 否 | 日志流、Schema频繁变化的数据 |
性能对比(1TB TPC-H数据集)
| 操作 | TextFile | ORC | Parquet |
|—————-|————–|———|————|
| 全表扫描时间 | 320s | 180s | 150s |
| 存储空间(未压缩)| 2.1GB/百万行 | 1.5GB | 1.2GB |
| 列查询延迟 | 高 | 中 | 低 |
数据组织与分区策略
分区(Partitioning)
- 作用:按字段(如
date、country)分割数据到子目录,减少全表扫描。 - 示例:按日期分区的日志表
CREATE TABLE access_logs ( ip STRING, url STRING, response_code INT ) PARTITIONED BY (log_date STRING) STORED AS ORC;
- 最佳实践:
- 分区字段需高频查询(如时间、地域)。
- 避免过多分区(如超过1万),否则元数据压力大。
- 作用:按字段(如
分桶(Bucketing)
- 作用:将数据哈希分配到指定数量的桶中,提升join和聚合效率。
- 示例:按用户ID分桶的用户行为表
CREATE TABLE user_actions ( uid STRING, action STRING, ts BIGINT ) CLUSTERED BY (uid) INTO 10 BUCKETS;
- 优势:
- 均匀分布数据,避免热点。
- 支持高效的
MAPJOIN和GROUP BY。
压缩与编码优化
Hive支持多种压缩算法,需根据场景权衡压缩率与CPU开销:
| 压缩类型 | 算法 | 适用场景 | 压缩率 |
|---|---|---|---|
| 文件级压缩 | Gzip、Bzip2、Snappy | 通用场景,适合文本文件 | 50%~70% |
| 块级压缩 | LZO、Zstd | ORC/SequenceFile,平衡性能 | 60%~80% |
| 列式压缩 | Zlib、Brotli(Parquet) | 列存格式,高压缩比 | 70%~90% |
启用压缩示例:
CREATE TABLE sales_data (
product_id INT,
amount DOUBLE
)
STORED AS ORC
TBLPROPERTIES ('orc.compress'='SNAPPY');事务与ACID支持
Hive 3.x引入事务表,支持ACID操作(需开启hive.support.concurrency=true):
- 插入模式:
INSERT INTO支持覆盖(OVERWRITE)或追加(APPEND)。 - 更新与删除:通过
UPDATE和DELETE语句修改数据,依赖事务日志(Hive事务表需使用MERGE或COMPACT命令)。 - 典型配置:
SET hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DbTxnManager; SET hive.compactor.initiator.on=true; -自动合并小文件
存储优化最佳实践
- 混合存储格式:热数据用ORC/Parquet,冷数据用压缩文本(如Gzip)。
- 动态分区调整:通过
hive.exec.dynamic.partition=true启用动态分区,减少手动管理。 - 小文件合并:启用
hive.merge.mapfiles=true和hive.merge.mapredfiles=true,避免大量小文件。 - 列式存储+统计信息:开启
hive.compute.query.using.stats=true,利用统计信息优化查询计划。
FAQs
Q1:如何选择ORC和Parquet格式?
- ORC:适合Hive原生生态,支持复杂数据类型(如Struct、Map),压缩和查询性能均衡。
- Parquet:更适合与Spark、Impala等引擎交互,支持嵌套Schema和高效向量化计算。
- 建议:若主要用Hive查询选ORC,需跨引擎兼容选Parquet。
Q2:分区过多会导致什么问题?如何优化?
- 问题:元数据加载慢(Hive元数据库压力大)、HDFS文件数激增。
- 优化方案:
- 合并低频分区(如将
YYYY-MM-DD合并为YYYY-MM)。 - 使用动态分区但限制层级深度(
hive.dx.num.dynamic.partitions.max=1000)。 - 对历史分区进行归档(如迁移
- 合并低频分区(如将