上一篇
分布式文件存储系统技术
分布式文件存储系统通过数据分片、冗余备份、元 数据管理、一致性协议及负载均衡等技术,实现海量数据的可靠存储与高效访问,具备高可用、可扩展
分布式文件存储系统技术解析
核心概念与技术特点
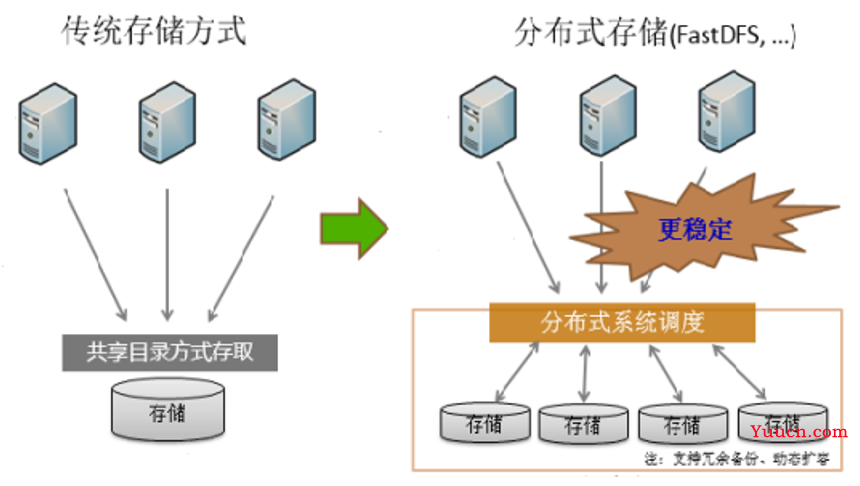
分布式文件存储系统(Distributed File System, DFS)是一种通过多台服务器协同工作,将数据分散存储在物理节点上的技术架构,其核心目标是解决传统集中式存储的单点故障、容量瓶颈和性能限制问题,同时提供高可用性、可扩展性和数据持久性,以下是其关键技术特点:
| 特性 | 描述 |
|---|---|
| 数据分片 | 将大文件拆分为多个块(Block/Chunk),分散存储在不同节点,提升并行读写能力。 |
| 冗余备份 | 通过副本(Replication)或纠删码(Erasure Coding)实现数据容错,避免单点故障。 |
| 元数据管理 | 独立维护文件元信息(如路径、权限、块位置),通常由专用节点(如Master)处理。 |
| 无中心化 | 部分系统采用去中心化设计(如Ceph),通过算法共识实现节点平等协作。 |
| 动态扩展 | 支持在线扩容,新增节点时自动平衡数据分布,无需停机。 |
关键技术实现
数据分片与分布策略
- 固定分片:按固定大小(如64MB)分割文件,适用于大文件存储(如HDFS)。
- 动态分片:根据文件类型和访问模式动态调整分片大小(如Ceph的CRUSH算法)。
- 哈希分布:通过一致性哈希(Consistent Hashing)将数据均匀分布到节点,减少扩容时的数据迁移量。
冗余与容错机制
- 副本机制:每个数据块存储多份副本(如3副本),典型代表为HDFS,优点是简单可靠,但存储成本较高。
- 纠删码:将数据编码为多个校验块(如Reed-Solomon算法),相同冗余下存储效率更高(如Ceph),10份数据+4份校验块可容忍4个节点故障。
- 混合模式:结合副本与纠删码(如Google CFS),对热数据用副本,冷数据用纠删码。
元数据管理
- 集中式元数据:由单一Master节点管理(如HDFS),优点是结构简单,但存在单点故障风险。
- 分布式元数据:通过多节点协同(如Ceph的MON集群),采用Paxos或RAFT协议保证一致性。
- 元数据缓存:客户端缓存元数据(如文件路径到块ID的映射),减少对元数据服务器的依赖。
一致性与性能优化
- 强一致性:写操作需等待所有副本确认(如HDFS),适用于对数据一致性要求高的场景。
- 最终一致性:允许短暂不一致,通过后台同步保证最终一致(如Dynamo风格系统)。
- 缓存加速:利用客户端本地缓存或内存缓存(如Alluxio)提升读取性能。
主流架构对比
| 系统 | 架构类型 | 冗余方式 | 元数据管理 | 适用场景 |
|---|---|---|---|---|
| HDFS(Hadoop) | 主从架构 | 3副本 | 单一Master | 大数据分析、离线批处理 |
| Ceph | 去中心化 | 纠删码(可选副本) | 分布式MON集群 | 云存储、高性能计算 |
| GlusterFS | 纯分布式 | 副本+AFR自修复 | 无专用元数据节点 | 中小规模企业存储 |
| MooseFS | 主从+对等混合 | 副本+纠删码 | 多Master冗余 | 高可用企业级存储 |
典型应用场景
- 云计算存储底座:为虚拟机、容器提供持久化存储(如AWS S3基于DynamoDB+分布式存储)。
- 大数据处理:HDFS支撑MapReduce框架,Ceph为Spark提供并行访问能力。
- 分发:视频/图片文件分片存储,结合CDN边缘节点加速访问。
- 备份与归档:长期保存冷数据,通过纠删码降低存储成本。
挑战与未来趋势
当前挑战
- 一致性开销:强一致性模型下写性能受限(CAP定理权衡)。
- 运维复杂度:节点故障检测、数据再平衡(Rebalance)需自动化工具支持。
- 安全隔离:多租户场景下的数据加密与访问控制(如RBAC模型)。
演进方向
- 存算一体化:存储节点同时具备计算能力(如阿里云盘古存储)。
- AI驱动优化:利用机器学习预测数据访问模式,动态调整分片策略。
- Serverless化:按需分配存储资源,按使用量计费。
- 边缘协同:整合中心云与边缘节点,实现低延迟数据访问。
FAQs
Q1:如何选择集中式元数据还是分布式元数据?
- 集中式:适合小规模集群(<100节点),部署简单,但存在单点故障风险。
- 分布式:适合大规模集群,通过多节点冗余保证高可用,但实现复杂度高。
- 建议:若业务对99.99%高可用性有要求,优先选分布式元数据(如Ceph)。
Q2:纠删码和副本机制如何取舍?
- 副本机制:适合热数据或对延迟敏感的场景(如数据库日志),写入速度快但存储成本高。
- 纠删码:适合冷数据或长期归档,存储效率高但编码/解码会增加CPU开销。
- 混合策略:部分系统(如Azure Blob Storage)对高频访问数据用副本,低频数据