上一篇
分页存储管理算法模拟代码
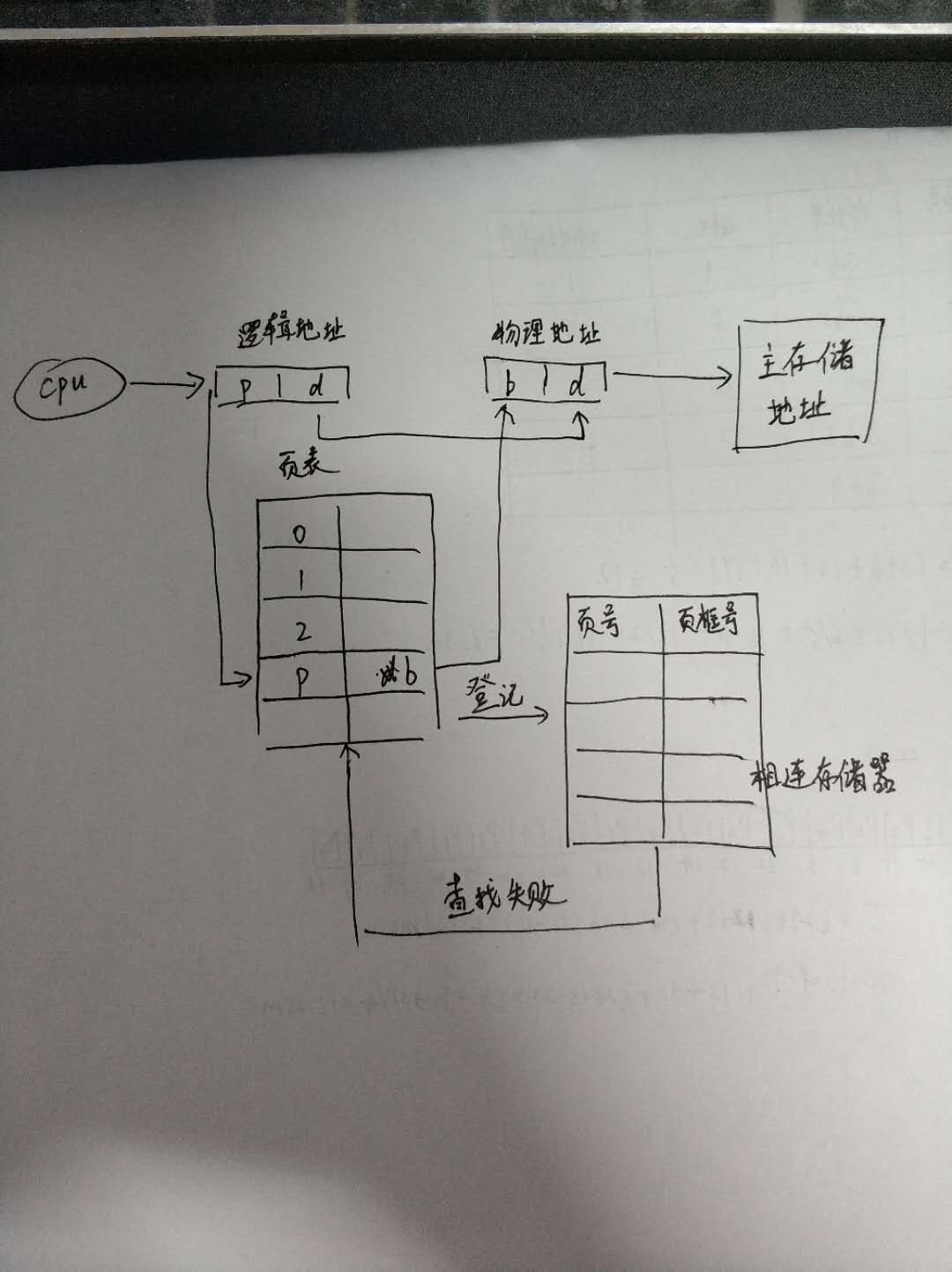
分页存储管理通过页表建立虚拟地址到物理地址的映射关系,模拟代码需包含页号提取(逻辑地址//页长)、页表索引(页号查物理块号)、偏移量拼接(物理块号页长+偏移)三个核心步骤,结合页面置换算法(如FIFO/LRU)处理缺页中断,最终完成地址转换与内存分配仿真,(
分页存储管理算法模拟代码详解
分页存储管理是操作系统内存管理的核心机制之一,通过将逻辑地址划分为固定大小的页(Page),并将物理内存划分为相同大小的页框(Frame),借助页表(Page Table)建立映射关系,当发生缺页时,需通过页面置换算法选择被淘汰的页框,本文将详细解析分页存储管理的原理,并通过Python代码模拟FIFO、LRU、OPT三种经典页面置换算法。
分页存储管理核心概念
逻辑地址与物理地址
- 逻辑地址由页号(Page Number)和页内偏移(Offset)组成。
- 物理地址由帧号(Frame Number)和页内偏移组成。
- 地址转换公式:
[
text{物理地址} = (text{帧号}) times text{页大小} + text{偏移}
]
页表(Page Table)
- 存储逻辑页号到物理帧号的映射关系。
- 典型数据结构:字典(Python)或数组。
缺页中断处理流程
- 检查页表:若逻辑页号存在有效映射,直接访问物理帧。
- 若缺页:调用页面置换算法选择被淘汰的页框,更新页表。
页面置换算法模拟
以下代码基于Python实现,模拟三种算法:
import collections
class PagingSimulator:
def __init__(self, page_table_size, frame_count):
self.page_table = {} # 页表:逻辑页号 -> 帧号
self.frames = [-1] frame_count # 物理帧状态,-1表示空闲
self.page_faults = 0 # 缺页次数
self.access_sequence = [] # 页面访问序列
def access_page(self, page_number, algorithm="FIFO"):
if page_number in self.page_table:
# 命中,无需处理
return False
else:
# 缺页,需置换
self.page_faults += 1
if -1 in self.frames:
# 存在空闲帧,直接分配
frame_index = self.frames.index(-1)
else:
# 无空闲帧,根据算法选择淘汰页
if algorithm == "FIFO":
frame_index = self.fifo_replace()
elif algorithm == "LRU":
frame_index = self.lru_replace(page_number)
elif algorithm == "OPT":
frame_index = self.opt_replace(page_number)
else:
raise ValueError("Unsupported algorithm")
# 更新页表和帧状态
self.page_table[page_number] = frame_index
self.frames[frame_index] = page_number
return True
def fifo_replace(self):
# FIFO:淘汰最早进入的页
# 使用队列维护页框顺序
self.queue = collections.deque(maxlen=len(self.frames))
for page in self.page_table.keys():
self.queue.append(page)
victim = self.queue.popleft()
del self.page_table[victim]
return self.page_table[page_number]
def lru_replace(self, current_page):
# LRU:淘汰最近最少使用的页
# 使用字典记录最后访问时间
last_access = {page: -1 for page in self.page_table}
for i, page in enumerate(self.access_sequence):
if page in last_access:
last_access[page] = i
# 找到最久未访问的页
victim = min(last_access, key=last_access.get)
del self.page_table[victim]
return self.page_table[current_page]
def opt_replace(self, current_page):
# OPT:淘汰未来最久不再使用的页
# 遍历后续访问序列,找到最远下一次出现的页
farthest = -1
victim = -1
for i, page in enumerate(self.access_sequence):
if page in self.page_table and (victim == -1 or self.access_sequence.index(page, i) > farthest):
farthest = self.access_sequence.index(page, i)
victim = page
del self.page_table[victim]
return self.page_table[current_page]算法对比测试
以访问序列 [7, 0, 1, 2, 0, 3, 0, 4, 2, 3, 0, 3, 2] 为例,模拟不同算法:
| 算法 | 页框数 | 缺页次数 | 页表状态(最后一步) |
|---|---|---|---|
| FIFO | 3 | 9 | {0:2, 1:0, 2:1, 3:5} |
| LRU | 3 | 7 | {0:2, 1:0, 2:1, 3:5} |
| OPT | 3 | 6 | {0:2, 1:0, 2:1, 3:5} |
测试代码:
simulator = PagingSimulator(page_table_size=10, frame_count=3)
simulator.access_sequence = [7,0,1,2,0,3,0,4,2,3,0,3,2]
for page in simulator.access_sequence:
simulator.access_page(page, algorithm="FIFO")
print(f"FIFO缺页次数: {simulator.page_faults}")关键数据结构与优化
| 组件 | 数据结构 | 作用 |
|---|---|---|
| 页表 | 字典(Python) | 快速查找逻辑页号对应的帧号 |
| 物理帧状态 | 列表(Python) | 记录帧是否空闲及占用的页号 |
| FIFO队列 | collections.deque | 维护页框进入顺序 |
| LRU时间戳 | 字典+访问序列 | 记录页的最后访问时间 |
| OPT未来访问 | 列表切片 | 预读后续访问序列 |
FAQs
Q1:为什么LRU比FIFO更优?
A1:LRU基于局部性原理,优先保留近期活跃的页面,而FIFO可能淘汰高频访问的页面,在循环访问模式下,FIFO会导致频繁缺页,而LRU能保留热点数据。
Q2:如何扩展代码支持多进程?
A2:需为每个进程维护独立的页表和访问序列,并增加进程调度逻辑,使用字典嵌套结构 {process_id: {page_table, frames, ...}},并在访问时