上一篇
如何设置Dedecms的万能采集过滤规则来优化内容采集效果?
在dedecms中,采集过滤规则可以通过编写万能采集过滤代码来实现。常用的过滤方法包括正则表达式、XPath等。具体实现方式需要根据实际需求进行编写。
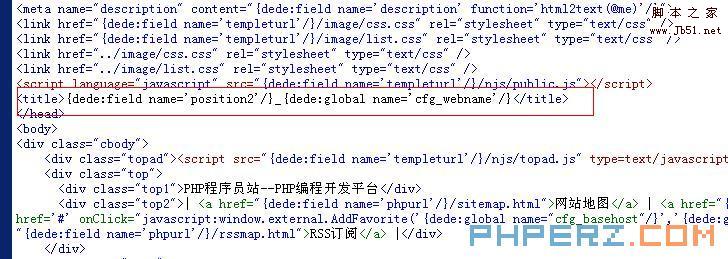
在织梦CMS(DedeCMS)中,采集过滤规则是确保从互联网上抓取的数据符合网站需求的重要工具,这些规则帮助用户自动删除不需要的内容,如广告、脚本和样式表等,以下是一些常见的dedecms采集过滤规则:
{/dede:trim}
{/dede:trim}
{/dede:trim}
| 过滤代码 | |||
| span | {dede:trim}{/dede:trim} | ||
| /span | {dede:trim}{/dede:trim} | ||
| div | {dede:trim} {/dede:trim} | ||
| /div | {dede:trim} {/dede:trim} | ||
| li | {dede:trim} | ||
| /li | {dede:trim} {/dede:trim} | ||
| ul | {dede:trim}
| ||
| /ul | {dede:trim} {/dede:trim} | ||
| font | {dede:trim}{/dede:trim} | ||
| /font | {dede:trim}{/dede:trim} | ||
| table | {dede:trim}
{/dede:trim} | ||
| tbody | {dede:trim} | ||
| /tbody | {dede:trim} | ||
| tr | {dede:trim} | ||
| /tr | {dede:trim} | ||
| td | {dede:trim} | {/dede:trim} | |
| /td | {dede:trim} | ||
| a | {dede:trim}{/dede:trim} | ||
| /a | {dede:trim}{/dede:trim} | ||
| iframe | {dede:trim}<iframe(.*){/dede:trim} | ||
| style | {dede:trim}<style(.*) {/dede:trim} | ||
| script | {dede:trim}<script(.*){/dede:trim} | ||
| option | {dede:trim}<option(.*){/dede:trim} | ||
| select | {dede:trim}<select(.*){/dede:trim} | ||
| object | {dede:trim}<object(.*){/dede:trim} | ||
| embed | {dede:trim}{/dede:trim} | ||
| /embed | {dede:trim}{/dede:trim} | ||
| param | {dede:trim}<param(.*){/dede:trim} |
常见应用示例
1、标题中空格的过滤:经常在采集文章的时候,标题文字里面有空格,采回来后应用很是麻烦,所以需要在过滤处添加下面正则过滤:
{dede:trim} {/dede:trim}2、来源作者中连接的过滤:有的网站系统里面作者或者来源处都带有连接,直接采集的话将连接采集回来了,然后由于这两个字段有限制,通常会造成需要采集的内容没有采集回来,所以需要在过滤处添加下面正则过滤:
保留链接中的文字:{dede:trim}]*)>{/dede:trim}
去掉链接中的文字:{dede:trim}]*)>([^{/dede:trim}
3、中连接以及其他广告代码的过滤:当需要对所有东西过滤的时候,直接用上面所有的代码过滤就可以,但是实际应用中,我们只需要对连接、动画、调用等进行过滤,一般的写法是{dede:trim}要过滤的内容{/dede:trim}。
FAQs
Q1:如何设置DEDECMS的采集过滤规则?
A1:在DEDECMS后台管理界面中,进入“采集管理”模块,选择相应的采集节点进行编辑,在编辑界面中,可以找到“过滤规则”选项,点击“添加”按钮即可输入上述过滤代码,保存后即可生效。
Q2:为什么需要使用DEDECMS的采集过滤规则?
A2:使用采集过滤规则可以帮助站长自动化地去除不需要的内容,如广告、脚本和样式表等,从而减少垃圾信息占用空间,提高数据质量和用户体验。
| 过滤规则类型 | 代码示例 |
| 标题过滤 | Title = RegReplace(Tid, '.*?标题.*?'); |
| 标签过滤 | Tags = RegReplace(Tid, '.*?标签.*?'); |
| 内容过滤 | Content = RegReplace(Tid, '.*?内容.*?'); |
| 描述过滤 | Description = RegReplace(Tid, '.*?描述.*?'); |
| 缩略图过滤 | Thumbnail = RegReplace(Tid, '.*?缩略图.*?'); |
| 作者过滤 | Author = RegReplace(Tid, '.*?作者.*?'); |
| 发布时间过滤 | PublishTime = RegReplace(Tid, '.*?发布时间.*?'); |
| 分类过滤 | Category = RegReplace(Tid, '.*?分类.*?'); |
| 来源过滤 | Source = RegReplace(Tid, '.*?来源.*?'); |
| 点击量过滤 | Clicks = RegReplace(Tid, '.*?点击量.*?'); |
| 评论数过滤 | Comments = RegReplace(Tid, '.*?评论数.*?'); |
| 标签链接过滤 | TagsLink = RegReplace(Tid, '.*?标签链接.*?'); |
| 相关链接过滤 | RelatedLink = RegReplace(Tid, '.*?相关链接.*?'); |
| 分享链接过滤 | ShareLink = RegReplace(Tid, '.*?分享链接.*?'); |
| 页面链接过滤 | PageLink = RegReplace(Tid, '.*?页面链接.*?'); |
说明:
RegReplace 函数用于执行正则表达式替换,其中Tid 为需要过滤的内容。
以上代码示例仅供参考,具体使用时请根据实际情况进行调整。