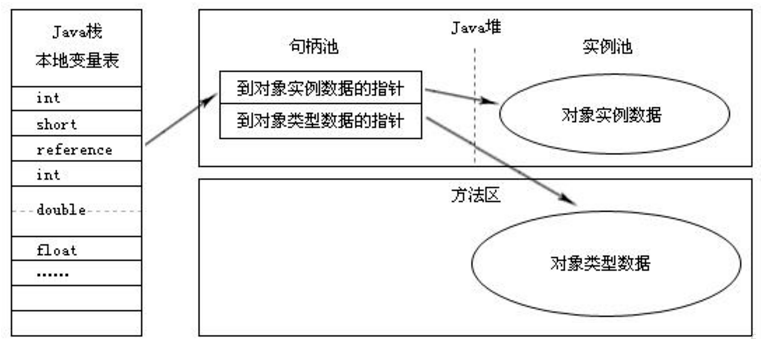
上一篇
java导出xls乱码怎么办
va导出XLS乱码可通过设置UTF-8编码、正确配置HTTP响应头及使用支持多语言的字体文件解决,推荐采用Apache POI库处理
Java开发中,使用Apache POI等库导出Excel(.xls格式)时出现中文乱码是一个常见问题,以下是详细的解决方案和最佳实践,涵盖编码设置、字体配置、流处理及特殊场景优化等多个维度:
核心原因分析
- 字符集不匹配:默认情况下,Excel采用ANSI编码存储数据,而Java应用通常使用UTF-8作为主编码格式,当两者未显式统一时,会导致非ASCII字符(如中文)解析异常。
- 字体缺失或不支持:若系统默认字体未包含所需字符集(例如宋体不支持某些生僻字),则可能显示为方框或问号。
- 响应头未正确声明:Web环境下下载文件时,若未设置
Content-Type和Content-Disposition的编码参数,浏览器可能按本地默认方式解码字节流。 - 写入模式错误:直接将字符串写入单元格而未指定样式或格式,可能导致底层二进制数据与预期不符。
分步解决方案
确保全局使用UTF-8编码
// 创建Workbook时强制指定UTF-8编码
Workbook workbook = new HSSFWorkbook();
Sheet sheet = workbook.createSheet("数据表");
Row row = sheet.createRow(0);
Cell cell = row.createCell(0);
// 关键步骤:通过CellStyle设置编码
CellStyle style = workbook.createCellStyle();
style.setDataFormat(HSSFDataFormat.getBuiltinFormat("@")); // 文本格式避免数字转换
cell.setCellStyle(style);
cell.setCellValue("测试中文内容"); // 直接赋值字符串
注意:
HSSFDataFormat.getBuiltinFormat("@")表示将该单元格视为纯文本类型,防止自动转义导致的截断问题。
Web环境下载时的MIME类型与文件名编码
当通过Servlet/Spring MVC返回文件流时,必须同时控制两个关键响应头:
| 响应头字段 | 示例值 | 作用说明 |
|———————|———————————|——————————|
| Content-Type | application/vnd.ms-excel;charset=UTF-8 | 声明内容类型及字符集 |
| Content-Disposition | attachment;filename=UTF-8''报告.xls | 兼容多语言的文件名编码方案 |
// Spring MVC示例
response.setContentType("application/vnd.ms-excel;charset=UTF-8");
String fileName = URLEncoder.encode("带中文的文件名", StandardCharsets.UTF_8.toString());
response.setHeader("Content-Disposition", "attachment;filename="" + fileName + "";filename=UTF-8''" + fileName);
技巧:使用双星号语法(
filename=UTF-8''...)可确保现代浏览器正确解析带空格的特殊字符文件名。
嵌入支持中文的字体文件
如果生成的Excel在其他设备上打开仍存在问题,建议打包TrueType字体到项目中并主动加载:

InputStream fontStream = getClass().getResourceAsStream("/simsun.ttf");
FontManager.registerFont(fontStream, "宋体"); // 注册自定义字体
// 后续创建单元格样式时引用该字体
Font font = workbook.createFont();
font.setFontName("宋体");
style.setFont(font);
原理:通过预置字体保证所有客户端都能渲染相同的字形效果。
处理特殊符号与转义序列
对于包含斜杠、反斜杠等路径相关字符的内容,需进行替换处理:
String safeText = originalText.replaceAll("[\/?:]", "_"); // 替换非规字符
cell.setCellValue(safeText);
避免在单元格值中使用控制字符(ASCII码<32),这类字符会破坏Excel结构。
验证输出流的正确关闭顺序
错误的流关闭顺序可能导致缓冲区残留脏数据,推荐写法:
try (OutputStream os = response.getOutputStream()) {
workbook.write(os); // POI自动管理底层字节转换
} catch (IOException e) {
logger.error("写入Excel失败", e);
} finally {
workbook.close(); // 确保释放临时资源
}
警告:切勿混用
FileOutputStream和网络流,二者的缓冲机制差异可能导致部分内容丢失。
典型错误排查指南
| 现象 | 可能原因 | 解决方法 |
|---|---|---|
| 数字型单元格中文变#VALUE! | 未设置文本格式 | 添加style.setDataFormat() |
| 下载后的文件名乱码 | 缺少filename扩展声明 |
按上述方式设置响应头 |
| 字体显示为方块 | 目标系统无对应字库 | 嵌入TTF字体到文档中 |
| 长文本被截断 | 自动换行未启用 | 调用cell.setCellStyle(style)后设置wrap=true |
FAQs
Q1:为什么设置了UTF-8还是出现乱码?
A:可能存在两个隐蔽问题:①未给单元格设置文本格式(导致被识别为数值型);②使用的POI版本过旧(建议升级至最新稳定版),可通过cell.setCellType(CellType.STRING)显式指定类型。
Q2:如何在Linux服务器上保证导出的正常显示?
A:Linux默认不包含中文字体,需通过代码动态注入字体文件,参考前文提到的FontManager.registerFont()方法,并将常用字体放在项目