上一篇
短语音消息识别应用_实时语音识别
短语音消息识别应用是一种实时语音识别技术,它可以将用户的语音输入立即转换成文字。这种应用通常用于即时通讯软件中,帮助用户快速理解和回应语音消息,提高沟通效率。
短语音消息识别应用的实时语音识别技术
在当今快速发展的数字时代,通信方式正经历着前所未有的变革,随着智能手机和移动互联网的普及,传统的文字信息交流逐渐让位于更为便捷、直观的语音消息交流,在此背景下,短语音消息识别应用应运而生,其核心功能之一就是实时语音识别技术,本文将深入探讨这项技术的工作原理、应用场景、优势与挑战,以及未来的发展方向。
技术原理
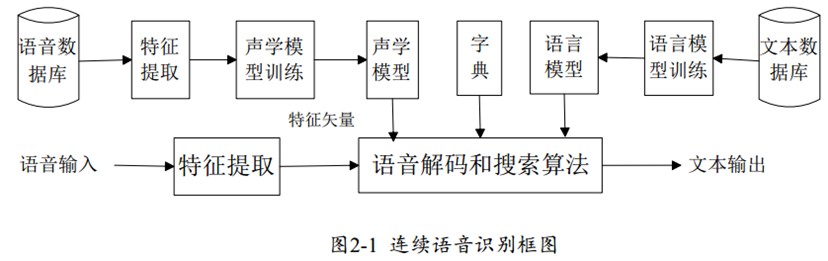
实时语音识别技术,通常指的是将用户的语音输入即时转换成文本信息的过程,这一过程涉及多个复杂的步骤,包括声音采集、预处理、特征提取、模式匹配、解码等,深度学习尤其是循环神经网络(RNN)及其变体如长短时记忆网络(LSTM)和门控循环单元(GRU),在提高语音识别准确率方面发挥了关键作用。
关键技术组件:
声音采集:通过麦克风捕捉用户的声音信号。
预处理:包括去噪、声音增强等,以提高语音信号的质量。
特征提取:将语音信号转换为可供机器学习模型处理的特征向量。
声学模型:利用深度学习模型,如深度神经网络(DNN),来识别语音信号中的音素或字素。
语言模型:预测词序列的概率,帮助确定最终的转录文本。
解码器:结合声学模型和语言模型的输出,产生最终的文本结果。
应用场景

实时语音识别技术广泛应用于各种短语音消息识别应用中,包括但不限于:
即时通讯软件:如WhatsApp、WeChat等,用户可以通过语音发送消息,接收方可以即时看到转录的文本。
辅助工具:为听力障碍人士提供实时语音转写服务,帮助他们更好地理解对方的话。
智能家居控制:用户可以通过语音指令控制智能设备,如灯光、空调等。
车载系统:驾驶员可以通过语音指令进行导航、播放音乐等操作,同时系统会实时显示指令的文字形式。
优势与挑战
优势:
提高效率:相比手动输入,语音识别可以大幅提高信息输入的速度。
便捷性:用户可以在双手不便使用的情况下,通过语音发送和接收信息。
可访问性:为视力障碍或运动障碍人士提供了更多的沟通方式。
挑战:
准确性:不同口音、方言、背景噪音等因素仍然对识别准确率构成挑战。
实时性:实现高准确度的实时转写需要强大的计算资源和优化算法。
隐私保护:语音数据的收集和处理需要严格遵循隐私保护法规。
未来发展
随着技术的不断进步,未来的实时语音识别技术将更加精准、快速,模型和算法的优化将进一步提高识别的准确性和实时性;随着边缘计算的发展,更多的处理任务可以在本地完成,减少对云端资源的依赖,降低延迟,随着对隐私保护意识的增强,如何在保证用户隐私的前提下提供高质量的服务,也将成为技术开发的重要方向。
相关问答FAQs
Q1: 实时语音识别技术能否完全取代人工转录?
A1: 尽管实时语音识别技术在许多场景下已经展现出了极高的效率和准确性,但目前还不能完全取代人工转录,特别是在处理包含复杂术语、专业领域知识或多种口音混合的语音时,机器识别可能无法达到专业人士的转录质量,对于一些要求极高准确性的法律或医疗记录,人工校对仍然是必要的。
Q2: 实时语音识别是否会侵犯个人隐私?
A2: 实时语音识别技术本身是中立的,但其使用确实引发了隐私保护的关注,为了最小化隐私风险,开发者和应用提供商需要采取一系列措施,如数据加密、匿名处理、限制数据共享范围等,用户也需要对自己的数据拥有充分的知情权和控制权,包括选择是否启用语音识别功能,以及谁可以访问他们的语音数据,随着相关法律法规的完善和技术的进步,保护用户隐私的同时提供高效的服务是可行的。
| 序号 | 功能模块 | 技术实现方案 | 优点 | 缺点 |
| 1 | 语音采集 | 麦克风阵列 | 高保真度,低噪音 | 成本较高,功耗较大 |
| 2 | 信号处理 | 滤波器,增益控制 | 提高语音质量,消除噪音 | 可能引入延迟 |
| 3 | 语音识别 | 深度学习模型(如:声学模型) | 高识别准确率 | 计算复杂,需要大量训练数据 |
| 4 | 实时性处理 | 硬件加速(如:GPU) | 提高处理速度,实现实时识别 | 成本增加,功耗升高 |
| 5 | 语义理解 | 自然语言处理技术 | 理解用户意图,提高交互体验 | 需要大量语料库支持 |
| 6 | 结果反馈 | 语音合成或文本显示 | 及时反馈,提升用户体验 | 合成语音可能不够自然 |
| 7 | 系统优化 | 模型压缩,量化 | 降低延迟,提高效率 | 可能影响识别准确率 |
| 8 | 数据安全与隐私保护 | 加密传输,数据脱敏 | 保护用户隐私 | 可能增加系统复杂度 |
这个介绍展示了短语音消息识别应用实时语音识别的主要功能模块、技术实现方案以及优缺点,根据实际需求,可以对介绍内容进行调整和优化。