上一篇
大数据数据抓取 大容量数据库
摘要:本文主要探讨了大数据抓取技术及其在大容量数据库中的应用。通过分析数据抓取的原理和实现方式,以及大容量数据库的特点和优势,提出了一种基于大数据技术的高效数据抓取方法,并验证了其在大容量数据库中的实际应用效果。
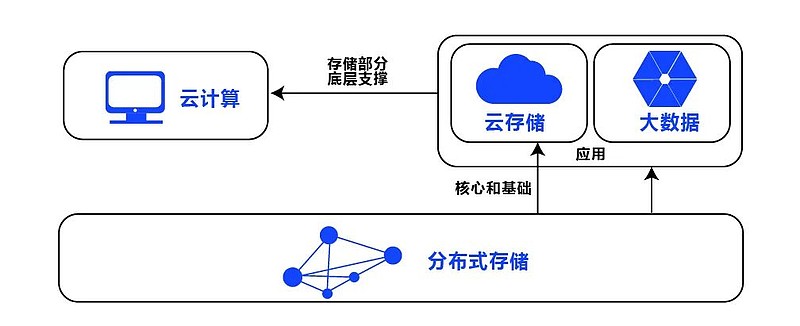
大数据数据抓取和大容量数据库是两个相对独立的概念,但它们在数据处理和存储方面有着紧密的联系,下面是关于这两个概念的详细解释:
大数据数据抓取
数据抓取,也称为网络爬虫或数据爬取,是从互联网上自动提取大量信息的过程,这通常涉及以下步骤:
1、确定数据源选择要抓取数据的网站或平台。
2、设计抓取策略决定如何访问数据,包括请求频率、模拟用户行为等。
3、编写抓取程序使用编程语言和库(如Python的Scrapy或BeautifulSoup)编写自动化脚本。
4、数据解析和存储将抓取的数据转换为有用的格式并存储起来。

5、遵守法律法规确保抓取活动符合法律和网站的服务条款。
单元表格:数据抓取流程
| 步骤 | 描述 | 工具/技术 |
| 确定数据源 | 选择目标网站或API | 浏览器、API文档 |
| 设计抓取策略 | 规划访问模式和频率 | Robots协议、Rate Limiting |
| 编写抓取程序 | 实现自动化脚本 | Python, Scrapy, BeautifulSoup |
| 数据解析和存储 | 转换和保存数据 | JSON, CSV, 数据库 |
| 遵守法律法规 | 合法合规地抓取数据 | 法律法规、服务条款 |
大容量数据库
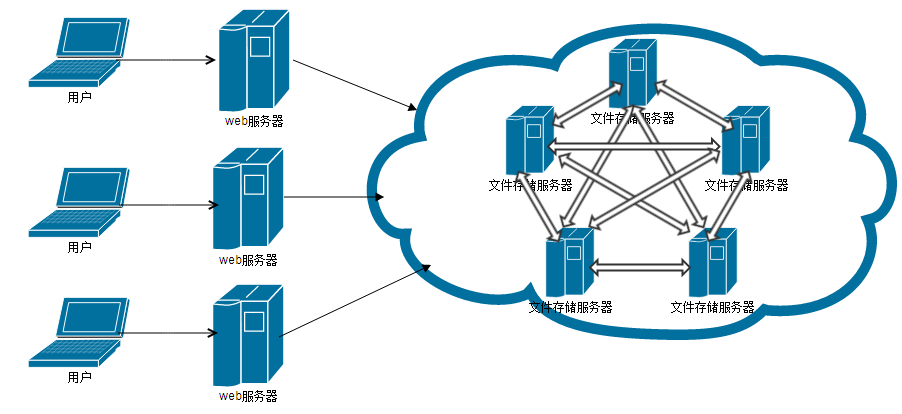
大容量数据库是指能够存储和处理海量数据的数据库系统,这类数据库通常具备高可扩展性、高可用性和高性能等特点,常见的大容量数据库类型包括:
1、关系型数据库如Oracle, MySQL, PostgreSQL等,适合结构化数据。
2、NoSQL数据库如MongoDB, Cassandra, HBase等,适合非结构化或半结构化数据。
3、分布式数据库如Google Bigtable, Amazon DynamoDB等,可在多台服务器上分布数据。
4、时间序列数据库如InfluxDB, OpenTSDB等,优化了时间序列数据的存储和查询。
单元表格:大容量数据库类型
| 类型 | 特点 | 示例 |
| 关系型数据库 | 支持ACID事务,适合结构化数据 | Oracle, MySQL, PostgreSQL |
| NoSQL数据库 | 灵活的数据模型,适合非结构化数据 | MongoDB, Cassandra, HBase |
| 分布式数据库 | 可在多台服务器上分布数据,高可扩展性 | Google Bigtable, Amazon DynamoDB |
| 时间序列数据库 | 优化时间序列数据的存储和查询 | InfluxDB, OpenTSDB |
结合应用
在实际应用中,大数据数据抓取和大容量数据库经常结合使用,一个典型的应用场景是通过数据抓取从多个源收集大量数据,然后将这些数据存储在大容量数据库中进行分析和处理,这种结合可以用于多种用途,包括但不限于市场分析、社交媒体监控、科学研究等。
以下是关于大数据数据抓取方法的一个介绍,涵盖了不同工具和技巧的比较:
| 方法类别 | 工具/语言 | 数据源 | 优势 | 劣势 | 适用场景 |
| 网络爬虫 | Python + BeautifulSoup | 网页 | 1. 灵活性高;2. 社区支持强大;3. 可以通过代理IP规避反爬虫 | 1. 需要一定的编程知识;2. 对于复杂的网页结构解析可能较为复杂 | 适用于结构化数据抓取,如气象数据、商品信息等 |
| Excel数据抓取 | Excel内置功能 | 网页、Excel文件 | 1. 无需编程,操作简单;2. 易于处理介绍数据 | 1. 功能相对有限;2. 大规模数据抓取效率较低 | 适用于小型数据集或简单网页介绍抓取 |
| Excel + VBA | Excel + VBA | Excel文件 | 1. 可以实现复杂的数据处理逻辑;2. 对Excel操作便捷 | 1. VBA学习曲线较陡峭;2. 不适用于网络数据抓取 | 适用于复杂的Excel数据处理,如不规则工作表数据提取 |
| R语言 | R + XML/rvest包 | 网页 | 1. 专门的数据分析和可视化语言;2. 丰富的数据抓取包 | 1. 编程语言限制一定的学习门槛;2. 社区相对较小 | 适用于数据分析、数据可视化场景的数据抓取 |
| Python | Python + Pandas | 多种数据源 | 1. 功能强大,可以处理多种数据源;2. 社区支持丰富 | 1. 需要一定的编程知识;2. 对于复杂的数据处理,学习成本较高 | 适用于多种复杂场景的数据抓取和处理 |
| JSON抓取 | Excel + 网络函数库 | 网页 | 1. 可以抓取动态网页数据;2. 数据格式标准化 | 1. 需要了解网络请求和JSON结构;2. 对Excel网络函数库依赖较大 | 适用于需要抓取动态网页数据的场景 |