上一篇
如何高效地在MySQL中存储和管理百万级别的数据记录?
MySQL可以高效地存储和处理百万条数据,通过优化索引、查询和表结构来提升性能。
MySQL存储百万条数据库_附录
创建数据库和表
1、创建数据库:在MySQL中,可以使用CREATE DATABASE命令来创建一个新的数据库,创建一个名为test_bai的数据库:
“`sql
CREATE DATABASEtest_bai;
“`
2、切换到新创建的数据库:使用USE命令切换到刚刚创建的数据库:
“`sql
USEtest_bai;
“`
3、创建表:使用CREATE TABLE命令来创建一个新的表,例如创建一个用户表app_user:
“`sql
CREATE TABLEapp_user (
id INT NOT NULL AUTO_INCREMENT COMMENT ‘主键’,
name VARCHAR(50) DEFAULT ” COMMENT ‘用户名称’,
email VARCHAR(50) NOT NULL COMMENT ‘邮箱’,
phone VARCHAR(20) DEFAULT ” COMMENT ‘手机号’,
gender TINYINT DEFAULT ‘0’ COMMENT ‘性别(0男, 1女)’,
password VARCHAR(100) NOT NULL COMMENT ‘密码’,
age TINYINT DEFAULT ‘0’ COMMENT ‘年龄’,
create_time DATETIME DEFAULT NOW(),
update_time DATETIME DEFAULT NOW(),
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT=’app用户表’;
“`
4、插入数据:为了生成百万条数据,可以创建一个自定义函数并调用它,设置全局变量以允许创建函数:
“`sql
SET GLOBAL log_bin_trust_function_creators = TRUE;
“`
创建自定义函数mock_data:
“`sql
DELIMITER $$
CREATE FUNCTION mock_data() RETURNS INT
BEGIN
DECLARE num INT DEFAULT 1000000;
DECLARE i INT DEFAULT 0;
WHILE i < num DO
INSERT INTO app_user(name, email, phone, gender, password, age)
VALUES (CONCAT(‘用户’, i), CONCAT(‘user’, i, ‘@example.com’), CONCAT(’18’, FLOOR(RAND() * (999999999 100000000 + 1))), FLOOR(RAND() * 2), UUID(), FLOOR(RAND() * 100));
SET i = i + 1;
END WHILE;
RETURN i;
END$$
DELIMITER ;
“`
调用该函数以生成数据:
“`sql
SELECT mock_data();
“`
常见问题及解答
问题1:如何快速生成大量测试数据?
答:可以通过编写存储过程或函数来批量插入数据,如上文所示,通过创建一个自定义函数并循环插入数据,可以快速生成大量数据,还可以利用MySQL内存表的特性,先在内存表中生成数据,再将其插入实际表中,以提高插入速度。
问题2:如何处理大数据量下的查询优化?
答:针对大数据量的查询优化,可以从以下几个方面入手:
1、合理设计索引:根据查询需求设计合适的索引,可以显著提高查询性能,但要注意,索引虽能加速查询,却会降低写入性能,因此需要权衡利弊。
2、避免全表扫描:尽量只查询必要的字段,而不是使用SELECT,这样可以减少I/O操作,提高查询速度。
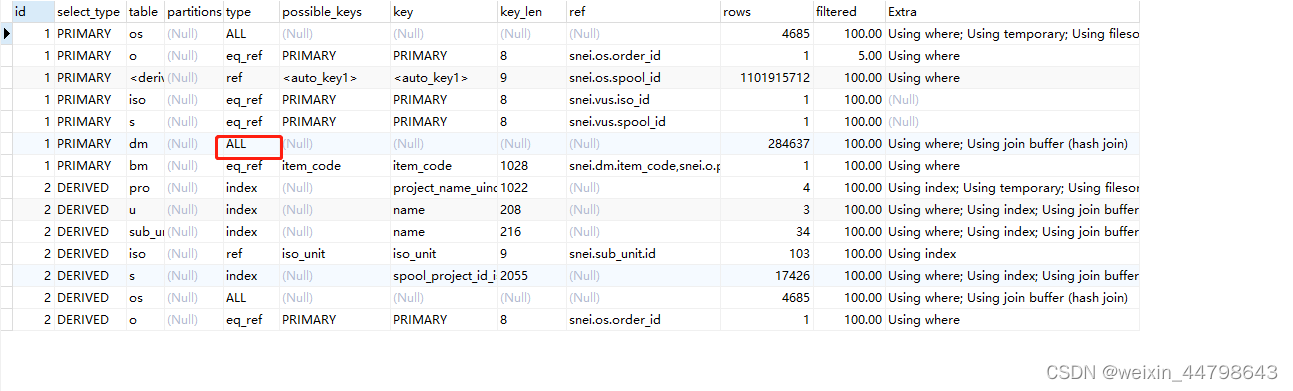
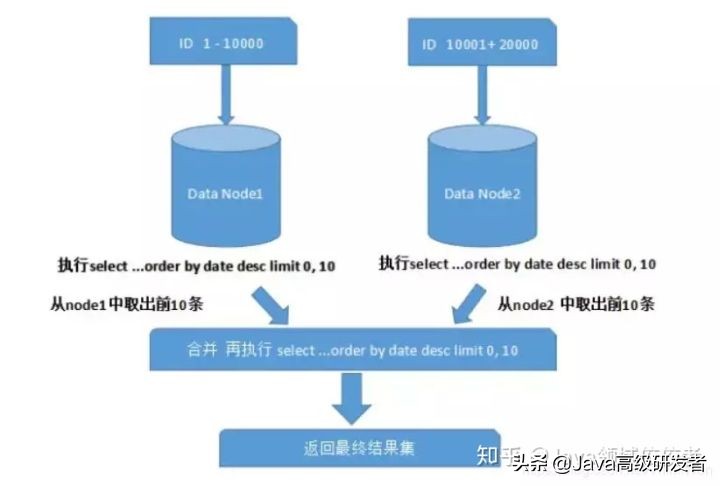
3、分页查询优化:对于大数据集的分页查询,应避免直接使用OFFSET进行大量数据的跳过,而是通过子查询定位起始记录ID,再进行分页查询,这样可以避免全表扫描,提高查询效率。
4、使用适当的SQL语句:尽量避免复杂的内联查询和不必要的函数计算,这些操作可能会增加数据库的负担,可以通过程序预处理数据来减轻数据库的压力。
5、考虑分区或分表:对于非常大的数据集,可以考虑使用分区或水平分表的策略,将数据分散到多个物理文件中,以提高查询和维护的效率。
处理百万级乃至千万级的数据时,合理的数据库设计和查询优化策略是关键。
| 序号 | 参数/设置 | 说明 |
| 1 | 表结构设计 | 设计合理的表结构,包括合适的字段类型、索引等,以优化存储和查询性能。 |
| 2 | 分区表 | 对于非常大的表,可以考虑使用分区表来提高管理和查询效率。 |
| 3 | 索引优化 | 合理创建索引,避免过度索引,确保索引能够提高查询速度。 |
| 4 | 存储引擎 | 选择合适的存储引擎,如InnoDB,它支持行级锁定和事务处理,适合处理大量数据。 |
| 5 | 数据归档 | 定期对旧数据进行归档,减少在线数据库的存储压力。 |
| 6 | 分片存储 | 对于跨数据库的大型应用,可以考虑使用分片存储来分散数据。 |
| 7 | 缓存策略 | 使用查询缓存或应用层缓存来减少对数据库的直接访问,提高性能。 |
| 8 | 数据压缩 | 对存储的数据进行压缩,减少存储空间的需求。 |
| 9 | 数据备份 | 定期备份数据,以防数据丢失或损坏。 |
| 10 | 批量插入 | 使用批量插入而不是单条插入,以提高数据插入效率。 |
| 11 | 读写分离 | 实现读写分离,将查询操作分散到多个从库,减轻主库的压力。 |
| 12 | 高可用架构 | 使用主从复制、双机热备等技术确保数据库的高可用性。 |
| 13 | 监控和性能分析 | 实施监控和性能分析,及时发现并解决性能瓶颈。 |
| 14 | 扩容策略 | 根据数据增长情况,制定相应的数据库扩容策略。 |
| 15 | 安全性设置 | 确保数据库的安全性,如设置强密码、限制访问权限等。 |
| 16 | 优化查询语句 | 优化SQL查询语句,避免复杂的子查询和不必要的JOIN操作。 |
| 17 | 物理设计 | 根据实际业务需求,进行物理设计,如确定合适的存储文件路径等。 |
| 18 | 自动化运维 | 实施自动化运维,如自动化备份、监控、故障恢复等。 |
| 19 | 灾难恢复计划 | 制定灾难恢复计划,确保在发生灾难时能够迅速恢复数据和服务。 |
| 20 | 数据治理 | 建立数据治理体系,确保数据的准确性、完整性和一致性。 |