上一篇
c 数据库设计怎么做
语言数据库设计需先明确需求,规划表结构、字段类型与约束;合理建索引提升查询效率;注重数据一致性与完整性,做好异常处理。
是使用C语言进行数据库设计的详细步骤和关键要点:
数据结构设计
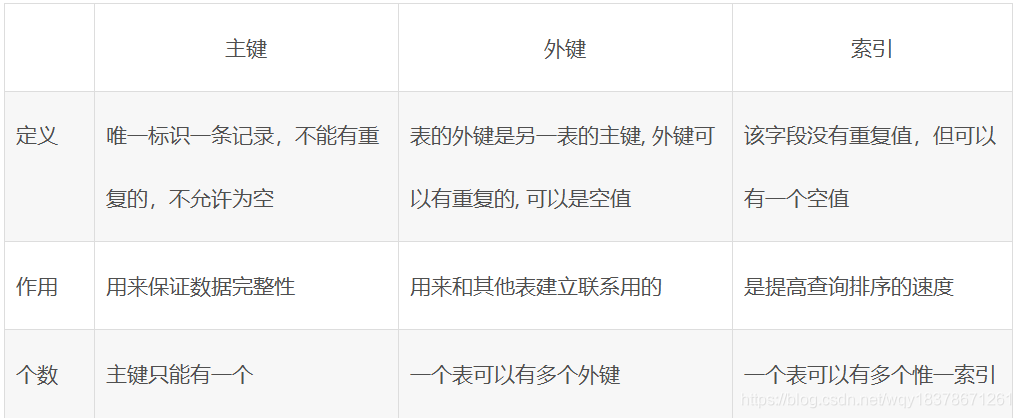
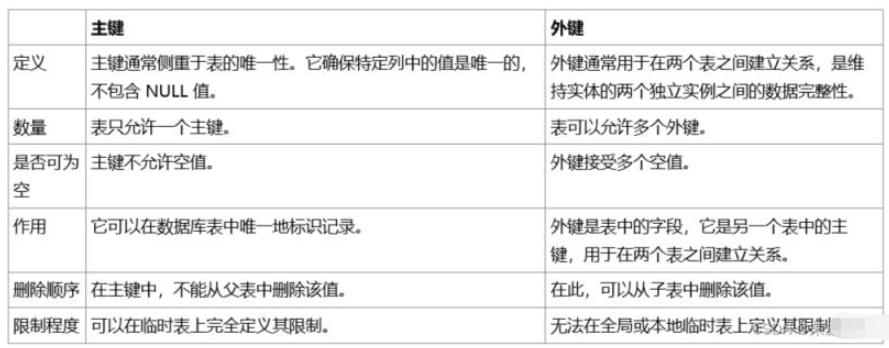
- 明确需求与实体关系建模:先梳理业务场景中涉及的所有数据对象(如用户、订单等),确定它们之间的关联关系,在图书馆管理系统里,书籍、读者、借阅记录就是主要的数据实体,且存在读者与借阅记录的主外键约束,基于此构建ER图,将其转化为具体的结构体定义,像表示图书的结构体可包含编号、书名、作者数组、出版年份及库存数量等字段,合理规划各字段的数据类型至关重要,整型用于存储ID或数量,字符数组存放字符串类信息,浮点型处理价格等带小数的数据。
- 选择合适的数据组织结构:常见的有数组、链表、树(二叉树、B树等)、哈希表,若频繁随机访问元素,数组较合适;经常插入删除操作则优先考虑链表;而追求高效查找时,B树作为索引结构能大幅提升性能,对于一个海量数据的日志系统,采用哈希表按时间戳快速定位特定时段的日志条目会非常有效。
- 内存管理策略制定:预估不同数据集的大小规模,提前申请足够的连续内存空间以减少动态分配带来的开销,要谨慎处理指针操作,防止野指针引发程序崩溃或数据错误,可以封装一套自己的内存池管理机制,统一调配和使用内存资源。
| 数据结构类型 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 数组 | 随机访问频繁的情况 | 访问速度快 | 插入/删除效率低 |
| 链表 | 频繁插入/删除的场景 | 灵活度高 | 随机访问慢 |
| B树 | 大量数据的有序存储与检索 | 查询效率高,平衡性好 | 实现复杂 |
| 哈希表 | 基于关键字的快速查找 | 平均查找时间短 | 冲突解决麻烦,需良好散列函数支持 |
文件存储实现
- 确定文件格式:二进制文件是常用选择,它能精准保留数据的原始字节形式,读写效率高且占用空间相对较小,每条记录按固定长度顺序存放,通过记录偏移量迅速定位到目标记录,也可考虑文本文件,其可读性强便于调试,但解析成本较高、存储冗余大,存储员工考勤打卡信息时,用二进制文件能紧凑地保存每次打卡的时间戳和员工编号等信息。
- 设计读写接口函数:利用C标准库中的
fopen()、fread()、fwrite()等函数完成文件操作,写入数据时,先将内存中的数据结构化打包成符合文件格式要求的字节流再写入;读取时反向解包还原为内存中的结构体变量,注意文件打开模式的选择,如追加模式用于日志记录类的持续写入操作。 - 处理并发访问问题:多进程或多线程同时读写同一文件可能导致数据混乱,可采用互斥锁(mutex)机制,在访问共享资源前加锁,确保同一时刻只有一个线程能执行读写操作,或者采用读写分离策略,为读操作和写操作分别设置不同的缓冲区,定期同步数据到磁盘。
索引与查询功能开发
- 构建索引机制:常用的索引结构包括B树、B+树和哈希表,以B树为例,它是一种自平衡的多路搜索树,每个节点包含多个关键字及其对应的指针,插入删除操作会自动调整树的结构保持平衡,从而保证较高的查找效率,对于小型数据库,简单的线性索引也可能够用,根据实际数据的分布特点选择合适的索引算法,如数据分布均匀时哈希索引效果佳,范围查询多则适合B树索引。
- 编写查询解析器:如果支持类似SQL的语法,就需要一个词法分析器将输入的查询语句分解成一个个token,再由语法分析器依据预设的规则构建语法树,最后生成相应的执行计划并调用底层API执行,解析“SELECT FROM students WHERE age > 18”这样的语句,提取出表名、条件表达式等信息后转换为对内存中数据结构的遍历筛选操作。
- 优化查询性能:除了依靠索引外,还可以对频繁使用的查询进行预编译,缓存结果集,当下次收到相同查询请求时直接返回缓存结果,避免重复计算,合理安排数据的物理布局也有助于提高查询速度,将经常一起访问的数据放在相邻位置。
事务管理
- 理解ACID特性:原子性(Atomicity)要求事务内的所有操作要么全部完成,要么全部回滚;一致性(Consistency)保证数据库始终处于合法状态;隔离性(Isolation)防止多个事务相互干扰;持久性(Durability)确保一旦提交,更改就永久保存,在C语言实现中,可通过日志记录来实现回滚操作,用锁机制保障隔离级别。
- 实现简单事务控制逻辑:开始事务时开启日志记录,记录所有即将修改的前像(before image);执行过程中若出现错误则根据日志回滚到初始状态;成功完成后写入检查点标记,清理无用日志条目,例如银行转账业务,从一方账户扣款并向另一方增资必须作为一个原子性的事务处理。
性能优化
- 减少不必要的拷贝:尽量原地操作数据,避免频繁的数据复制带来的性能损耗,例如在排序算法中,可以使用指针交换代替实际数据的移动。
- 批量处理操作:将多个小的操作合并成一个大的批次处理,减少I/O次数,比如一次性插入多条记录比逐条插入效率高很多。
- 缓存热点数据:识别出访问频率高的数据块,将其缓存在内存中,下次访问时直接从缓存获取,大大提高响应速度。
FAQs:
-
Q: C语言实现的数据库能否支持复杂的SQL语法?
A: 理论上可以实现大部分基础SQL功能,但随着语法复杂度增加,解析器的实现难度呈指数级上升,建议先实现核心子集,逐步扩展,现代开源项目如SQLite也是从简单功能起步不断迭代完善的。
-
Q: 如何测试自己写的数据库的正确性和稳定性?
A: 编写单元测试覆盖各个模块的功能边界;进行压力测试模拟高并发场景下的负载情况;使用模糊测试输入非规数据验证系统的健壮性;对比主流数据库的行为模式