上一篇
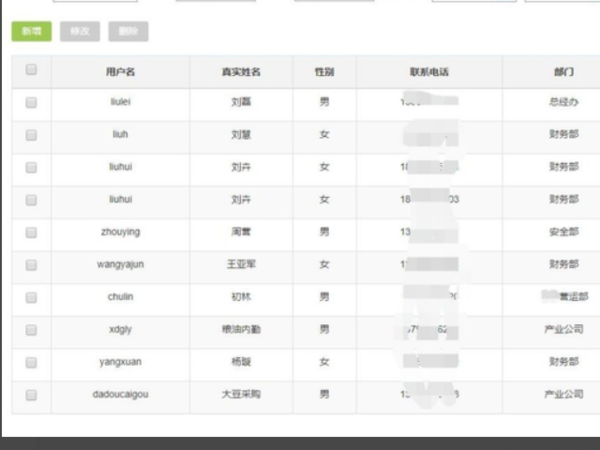
java怎么读取游标

Java中,可通过JDBC获取数据库结果集(ResultSet),利用其next()方法模拟游标逐行读取数据。
文件读取中的“游标”模拟
虽然Java标准库未直接提供名为“游标”的类,但可以通过流式API模拟类似行为,以逐行读取文本文件为例:
-
核心工具类:使用
BufferedReader配合其readLine()方法实现按行迭代,每次调用该方法会移动内部指针到下一行,直到返回null表示结束。- 示例代码结构如下:
import java.io.; public class FileIterator { public static void main(String[] args) throws IOException { File targetFile = new File("data.txt"); // 替换为实际路径 try (BufferedReader br = new BufferedReader(new FileReader(targetFile))) { String currentLine; while ((currentLine = br.readLine()) != null) { // 在此处理每一行数据 System.out.println("当前行内容: " + currentLine); } } // try-with-resources自动关闭资源 } } - 关键点:
try-with-resources语法确保资源释放,避免内存泄漏;readLine()的内部逻辑相当于维护了一个隐式的读取位置标记。
- 示例代码结构如下:
-
性能优化技巧:若需高频访问特定区间的数据,可结合随机访问文件类(如
RandomAccessFile),通过设置文件指针位置实现跳跃式读取。RandomAccessFile raf = new RandomAccessFile("largeData.bin", "r"); raf.seek(1024); // 直接定位到第1024字节处开始读取 byte[] buffer = new byte[512]; int bytesRead = raf.read(buffer);
数据库操作中的显式游标管理(JDBC)
当涉及数据库查询时,JDBC提供了更明确的游标控制能力,典型流程包括:
| 步骤序号 | 操作描述 | 对应代码片段 |
|———-|————————–|——————————————————————————|
| 1 | 加载驱动并建立连接 | Class.forName("com.mysql.jdbc.Driver");<br>Connection conn = DriverManager.getConnection(url, user, pass); |
| 2 | 创建可滚动敏感的结果集 | Statement stmt = conn.createStatement(ResultSet.TYPE_SCROLL_SENSITIVE, ResultSet.CONCUR_READ_ONLY); |
| 3 | 执行SQL并获取结果对象 | ResultSet rs = stmt.executeQuery("SELECT FROM employees"); |
| 4 | 通过next()方法移动游标 | while(rs.next()) { ... /提取当前行的列值/ ... } |
| 5 | 支持绝对定位与相对偏移 | rs.absolute(5);跳转至第5条记录;rs.relative(+3);向后移动3条记录 |
| 6 | 关闭资源顺序 | rs.close(); stmt.close(); conn.close(); |
注意事项:并非所有数据库都完全支持类型为TYPE_SCROLL_SENSITIVE的结果集,需查阅对应厂商文档确认兼容性,对于Oracle数据库,可能需要添加额外参数如oracle.jdbc.ReadOnly=false来启用完整功能。
分页加载大数据集的最佳实践
面对海量数据时,建议采用分批次检索策略:
// 假设每批处理1000条记录
int pageSize = 1000;
int offset = 0;
do {
String query = String.format("SELECT FROM logs ORDER BY timestamp LIMIT %d OFFSET %d", pageSize, offset);
ResultSet batchRS = stmt.executeQuery(query);
processBatch(batchRS); // 自定义处理方法
offset += pageSize;
} while (lastBatchHadFullRows); // 根据最后一批的实际数量判断是否继续
此模式能有效降低内存占用峰值,特别适用于数据分析场景下的增量处理。
异常处理与事务回滚机制
无论是文件还是数据库操作,都必须考虑失败恢复方案:
- 文件场景:记录已成功写入的目标位置,重启时从断点续传,可通过在文件中追加校验码实现完整性验证。
- 数据库场景:启用事务后,若发生运行时异常,调用
conn.rollback()撤销未提交的操作,推荐使用Spring框架的声明式事务管理简化编码。
FAQs
Q1: 如果遇到“ResultSet不可向前滚动”的错误怎么办?
A1: 这是由于创建Statement时未指定结果集类型导致的,应修改为:conn.createStatement(ResultSet.TYPE_SCROLL_INSENSITIVE, ...),其中TYPE_SCROLL_INSENSITIVE表示对其他事务提交的变化不敏感,但允许任意方向遍历。
Q2: 如何判断数据库游标是否已经到达末尾?
A2: 调用ResultSet.isAfterLast()方法检测是否越过最后一行,更通用的做法是在循环条件中使用while(rs.next()),因为当没有更多有效行时,该方法会返回false终止循环,对于需要精确控制的情况,还可以先用rs.last()定位到最后一行再