上一篇
ha均衡负载服务器
HA均衡负载服务器通过分配请求与故障转移保障服务高可用,提升系统稳定性和可靠性,避免
HA均衡负载服务器的核心概念
高可用性(High Availability,简称HA)与负载均衡(Load Balancing)是现代服务器架构中保障服务连续性和性能优化的两大关键技术,两者结合形成的HA均衡负载服务器体系,既能通过负载均衡算法分配请求压力,又能通过高可用机制消除单点故障风险。
1 高可用性(HA)的核心目标
- 消除单点故障:通过冗余设计(如主备节点、多活集群)确保任意单节点故障不影响整体服务。
- 快速故障转移:利用心跳检测、仲裁机制(如ZAB协议)实现秒级故障感知与切换。
- 数据一致性保障:结合数据库复制(如MySQL主从)、分布式存储(如Ceph)实现数据冗余。
2 负载均衡的核心功能
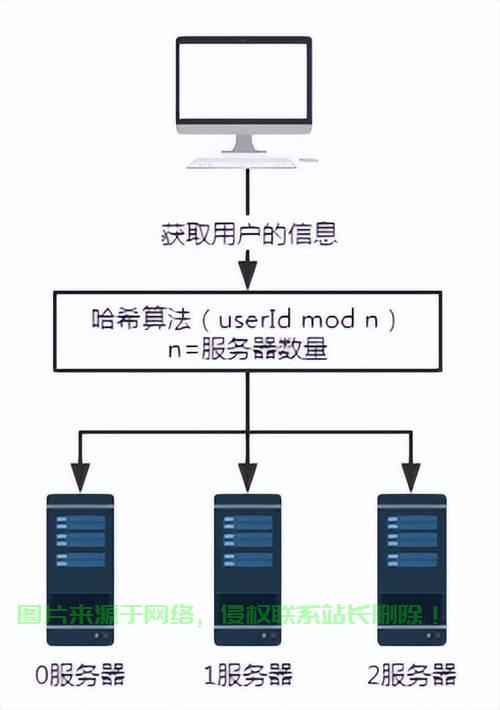
- 请求分发:基于轮询(Round Robin)、加权轮询、IP哈希等算法将流量分配到后端服务器。
- 压力分摊:动态调整后端服务器权重,避免单一节点过载。
- 健康检查:定期探测后端服务器状态(如TCP端口、HTTP响应码),自动剔除故障节点。
HA均衡负载服务器的架构设计
典型的HA负载均衡架构包含以下组件:
| 组件层级 | 功能描述 | 常见技术选型 |
|---|---|---|
| 负载均衡层 | 接收客户端请求并分发至后端服务器 | Nginx、HAProxy、LVS(Linux Virtual Server) |
| 高可用管理层 | 监控节点状态并执行故障转移 | Keepalived(VRRP协议)、Corosync/Pacemaker |
| 后端应用层 | 实际处理业务逻辑的服务节点 | Docker容器集群、KubernetesPod、物理服务器 |
| 数据存储层 | 提供共享存储或数据库服务 | NAS/SAN存储、MySQL主从复制、Redis哨兵模式 |
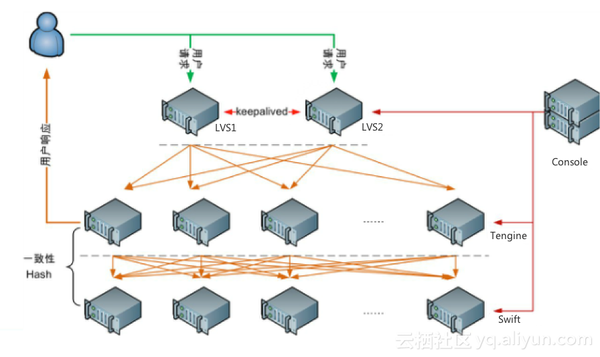
1 典型架构拓扑图
客户端
|
v
负载均衡器(LVS/Nginx)-----> 后端服务器集群(多节点)
| ^
v |
高可用管理(Keepalived) 数据存储(MySQL主从)2 关键设计原则
- 无状态设计:负载均衡器本身不保存会话状态,通过IP哈希或Cookie实现会话保持。
- 冗余部署:至少部署两台负载均衡器(如LVS+Keepalived),避免单点故障。
- 健康检查隔离:独立健康检查进程(如HAProxy的check机制)实时监控后端状态。
主流HA负载均衡方案对比
| 方案组合 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| Nginx+Keepalived | 中小规模Web服务 | 配置简单,社区支持丰富 | 依赖VIP漂移,切换速度较慢 |
| HAProxy+Corosync | 高并发TCP/HTTP服务 | 高性能,支持复杂路由规则 | 配置复杂度高,学习成本大 |
| LVS+Heartbeat | 大规模企业级集群 | 内核级性能,天然支持IP负载均衡 | 依赖Linux内核模块,维护成本高 |
| Cloud Load Balancer | 云原生环境(如AWS ELB) | 一键部署,自动扩展 | 成本较高,厂商锁定风险 |
实战:基于Nginx+Keepalived的HA负载均衡配置
1 环境准备
- 服务器节点:两台CentOS7服务器(192.168.1.10、192.168.1.11)
- 虚拟IP(VIP):192.168.1.20(用于客户端访问)
- 后端服务器:两台Tomcat应用服务器(192.168.1.21、192.168.1.22)
2 配置步骤
安装Nginx与Keepalived

# 安装Nginx yum install nginx -y # 安装Keepalived yum install keepalived -y
配置Nginx负载均衡
编辑/etc/nginx/conf.d/load_balance.conf:
upstream backend {
server 192.168.1.21:8080 weight=1 max_fails=3 fail_timeout=30s;
server 192.168.1.22:8080 weight=1 max_fails=3 fail_timeout=30s;
}
server {
listen 80;
location / {
proxy_pass http://backend;
proxy_set_header Host $host;
}
}配置Keepalived
编辑/etc/keepalived/keepalived.conf:
vrrp_instance VI_1 {
state MASTER # 另一台设为BACKUP
interface eth0
virtual_router_id 51
priority 100 # 主节点优先级高于备份节点
advert_int 1
authentication {
auth_type PASS
auth_pass 123456
}
virtual_ipaddress {
192.168.1.20
}
}启动服务并验证
systemctl start nginx keepalived # 在客户端访问VIP:http://192.168.1.20
常见问题与优化策略
1 脑裂问题(Split Brain)
- 原因:两台HA节点同时持有VIP,导致数据冲突。
- 解决方案:
- 启用仲裁机制(如引入Redis Sentinel或Etcd作为状态存储)。
- 配置Keepalived的
preempt参数,优先抢占VIP。
2 雪崩效应
- 现象:故障节点恢复后,短时间内收到大量请求导致过载。
- 优化:
- 设置
max_fails和fail_timeout参数,控制故障恢复节奏。 - 结合熔断机制(如Hystrix)限制请求速率。
- 设置
3 SSL终止性能瓶颈
- 优化方案:
- 在负载均衡器层配置SSL卸载(如Nginx的
ssl模块)。 - 启用硬件加速(如AWS NLB的TLS加速)。
- 在负载均衡器层配置SSL卸载(如Nginx的
最佳实践清单
| 序号 | 最佳实践 | 说明 |
|---|---|---|
| 1 | 分离静态资源与动态请求 | 使用CDN分担静态流量(如七牛云、阿里云OSS) |
| 2 | 启用连接复用(Keep-Alive) | 减少TCP三次握手开销 |
| 3 | 配置限速策略 | 防止DDoS攻击和突发流量冲击 |
| 4 | 日志集中管理 | 使用ELK(Elasticsearch+Logstash+Kibana)分析访问日志 |
| 5 | 灰度发布与蓝绿部署 | 通过负载均衡权重实现无缝版本切换 |
FAQs
Q1:HA负载均衡与普通负载均衡的核心区别是什么?
A:普通负载均衡仅解决请求分发问题,而HA负载均衡额外具备:
- 故障自动转移:通过心跳检测和VIP漂移实现节点故障切换。
- 双活/多活设计:所有节点均可承担流量,无主备角色划分。
- 数据冗余机制:结合数据库复制或分布式存储保证数据一致性。
Q2:如何测试HA负载均衡器的高可用性?
A:可通过以下步骤验证:
- 模拟节点故障:关闭主负载均衡器节点,观察VIP是否漂移到备节点。
- 后端服务器压测:使用工具(如JMeter)发起高并发请求,检查负载均衡效果。
- 网络中断测试:断开主备节点间网络,验证心跳超时后的故障转移