上一篇
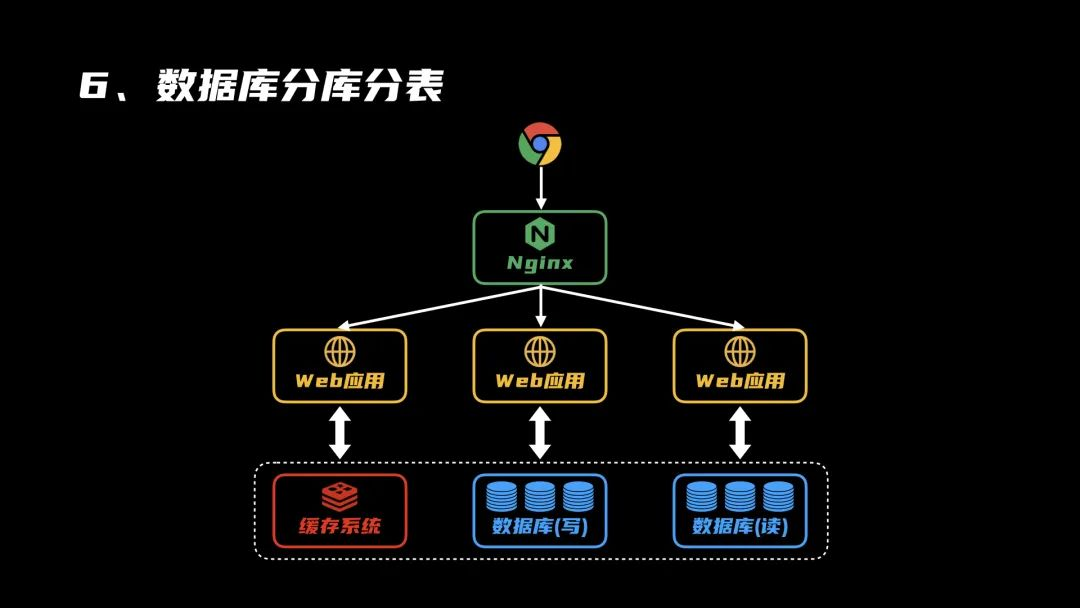
分布式数据库 分库分表
分布式数据库通过分库分表将数据分散存储,采用哈希或范围策略实现水平拆分,提升并发处理能力和
分库分表的核心原因
| 驱动因素 | 具体表现 |
|---|---|
| 数据量爆炸 | 单表数据超过亿级,查询效率下降,索引失效 |
| 高并发瓶颈 | 单机CPU、内存、磁盘IO无法支撑每秒万级请求 |
| 硬件成本限制 | 单个数据库实例扩容成本高,垂直扩展(加CPU/内存)边际效益递减 |
| 系统可用性要求 | 单点故障可能导致全服务不可用,需通过多节点冗余提升容灾能力 |
典型场景:电商平台订单系统(每日千万级订单)、社交应用消息系统(每分钟百万级消息)、金融交易系统(高并发读写)。

分库分表的核心概念
分库(Database Sharding)
- 定义:将数据按规则分散存储到多个独立数据库实例中。
- 示例:用户表按
user_id取模分散到db0~db3,每个库存储部分用户数据。 - 作用:突破单库连接数限制,降低单库磁盘IO压力。
分表(Table Sharding)
- 定义:将单表数据拆分到多个物理表中。
- 示例:订单表按
order_id哈希取模拆分为order_0~order_9共10张表。 - 作用:避免单表数据量过大导致查询性能下降,提升索引效率。
水平分库 vs 垂直分库
| 对比维度 | 水平分库 | 垂直分库 |
|---|---|---|
| 拆分依据 | 用户/业务维度(如按ID哈希) | 功能模块维度(如用户库、订单库) |
| 数据关联 | 跨库关联查询复杂 | 库内数据强关联 |
| 适用场景 | 写多读少、高并发场景 | 低耦合业务系统 |
分库分表策略与实现
分片策略
| 策略类型 | 实现方式 | 优缺点 |
|---|---|---|
| 哈希取模 | user_id % 4 将数据分散到4个库 | 均匀分布,但范围查询困难 |
| 范围分片 | 按时间(如2023-01订单存库1)或ID区间划分 | 连续查询高效,但易出现热点分布不均 |
| 一致性Hash | 虚拟节点+Hash环实现平滑扩展 | 解决节点增减导致的数据迁移问题,但算法复杂度高 |
中间件实现
- Sharding-JDBC:基于Java的轻量级分库分表框架,通过配置文件定义分片规则。
- MyCAT:开源MySQL代理,支持自动路由、数据聚合和复杂SQL解析。
- 自研方案:通过代码层封装分片逻辑(如Twitter的Snowflake分布式ID生成器)。
分布式ID生成
- 场景需求:分库分表后需全局唯一主键。
- 常见方案:
- 雪花算法(Snowflake):64位二进制生成,包含时间戳、机器ID、序列号。
- UUID:性能较低,通常用于非高并发场景。
- 数据库自增ID:依赖单点数据库,存在瓶颈。
分库分表的挑战与解决方案
跨库关联查询
- 问题:JOIN操作需访问多个数据库,性能骤降。
- 解决方案:
- 业务层拆分查询,避免跨库关联。
- 使用全局表(如用户信息表单独存储)减少关联。
- 引入ES/MongoDB等搜索引擎处理复杂查询。
数据迁移与扩容
- 问题:新增/移除节点时需重新分片,数据迁移成本高。
- 解决方案:
- 采用无状态设计,通过一致性Hash减少迁移量。
- 使用双写模式(新旧库同步写入)平滑过渡。
事务一致性
- 问题:跨库事务无法保证ACID特性。
- 解决方案:
- 最终一致性:通过消息队列异步补偿(如TCC协议)。
- XA分布式事务:性能差,仅适用于关键业务。
分片键选择
- 原则:
- 高离散性(避免热点,如
user_id比gender更合适)。 - 业务相关性(如订单按
user_id分片便于查询用户订单)。 - 不可变性(分片键值不应频繁变更)。
- 高离散性(避免热点,如
实践案例分析
案例1:电商订单系统
- 分库策略:按
user_id % 8将用户分散到8个库。 - 分表策略:每个库内订单表按
order_id % 10拆分为10张表。 - 效果:写吞吐量提升8倍,单表查询耗时从500ms降至50ms。
案例2:社交消息系统
- 分片策略:按用户ID一致性Hash分配到16个节点。
- 优化措施:热点用户数据(如明星账号)单独存储,避免Hash倾斜。
FAQs
问题1:分库分表后如何实现全局排序(如按创建时间排序)?
解答:
- 业务层合并:查询时从所有分片获取数据,客户端或服务端合并后排序。
- 冗余字段:在分片键中包含时间前缀(如
202301_user_id),优先按时间分片。 - 全局索引:通过Elasticsearch建立同步索引,直接查询ES而非数据库。
问题2:分片键选择不当导致数据倾斜怎么办?
解答:
- 重新分片:通过一致性Hash或范围调整重新分配数据。
- 冷热分离:将高频访问数据(如热门商品)单独存储。
- 动态分片:根据数据访问频率动态调整分片策略(如美团的动态分片算法)。