上一篇
分布式数据库支持分库分表
分布式数据库通过分库分表实现 数据切分与分布式存储,提升处理性能及扩展性
分布式数据库支持分库分表的核心原理与实践
分库分表的背景与必要性
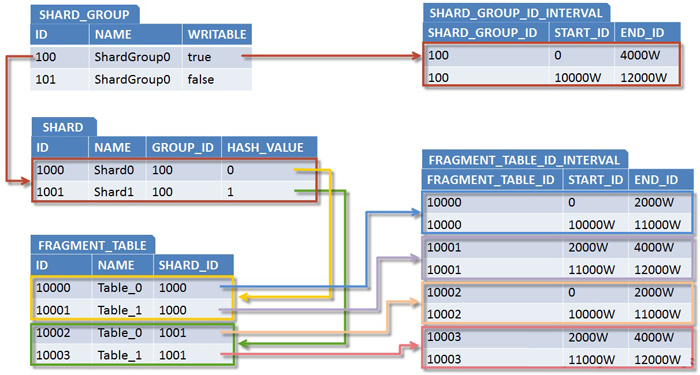
随着互联网业务的快速发展,单一数据库实例面临存储容量、并发性能、可用性三方面的瓶颈,以电商订单系统为例,当数据量超过亿级时,单库写入延迟显著增加,DDL操作(如建索引)可能锁表数小时,严重影响业务稳定性,分布式数据库通过分库分表技术,将数据分散存储到多个节点,突破单机物理限制,典型架构如下:
| 维度 | 单机数据库 | 分布式数据库(分库分表) |
|---|---|---|
| 存储容量 | 受限于单节点磁盘(TB级) | 线性扩展至PB级 |
| 并发吞吐量 | 受限于单节点CPU/内存 | 多节点并行处理(万级TPS) |
| 可用性 | 单点故障导致全服务中断 | 多副本冗余,RTO<30秒 |
| 成本效率 | 高端硬件采购成本高 | 普通PC服务器集群成本优化 |
分库分表的核心原理
数据分片策略
- 水平分库:按业务维度拆分,如用户ID取模分配到不同数据库
/ 用户1-1000存入db1,1001-2000存入db2 / INSERT INTO user_${shard_id} VALUES (?, ?, ...); - 垂直分表:按字段维度拆分,热数据与冷数据分离
/ 订单主表存基础信息,扩展表存详情 / CREATE TABLE order_main (id, user_id, status, ...); CREATE TABLE order_ext (id, promotion_info, logistics_detail);
- 水平分库:按业务维度拆分,如用户ID取模分配到不同数据库
分布式路由机制
- 哈希路由:
shard_key = user_id % db_count - 范围路由:按时间或ID区间划分,如
order_202301表存储1月数据 - 混合路由:电商场景中用户ID哈希分库,订单ID范围分表
- 哈希路由:
中间件实现
| 组件 | 功能 |
|—————|———————————————————————-|
| Sharding-JDBC | SQL解析→分片规则匹配→SQL改写→多节点执行→结果归并 |
| MyCAT | 虚拟IP+ADHOC路由,支持MySQL原生协议透明分库分表 |
| TiDB | 计算存储分离架构,自动路由+Raft协议保证强一致性 |
关键技术实现细节
全局唯一ID生成

- 雪花算法(Snowflake)生成19位ID:
41位时间戳 + 10位机器ID + 12位序列号 - 百度UidGenerator:基于Redis实现高可用ID生成
- 示例代码(Java):
public long generateId(long workerId, long datacenterId) { long timestamp = currentTimeMillis(); // 位移拼接时间戳、数据中心ID、工作机ID、序列号 return (timestamp << 22) | (datacenterId << 17) | (workerId << 12) | sequence; }
- 雪花算法(Snowflake)生成19位ID:
跨库事务处理
- XA协议:两阶段提交(2PC),性能损耗约30%
- TCC模式:Try→Confirm→Cancel补偿机制
// TCC事务伪代码 prepare(orderService.createOrder(order)); // 预留库存 prepare(paymentService.deduct(amount)); // 冻结资金 commitAll(); // 确认所有操作
- 消息队列最终一致性:异步补偿机制,适用于非核心业务
SQL改写与合并
- 原始SQL:
SELECT FROM order WHERE user_id=123 - 改写后:
SELECT FROM order_0, order_1 WHERE user_id=123 UNION ALL - 聚合函数优化:
COUNT()改为SUM(count_from_each_shard)
- 原始SQL:
典型场景实践对比
| 场景 | 推荐方案 | 关键配置 |
|---|---|---|
| 千亿级日志存储 | Elasticsearch+Kafka集群 | 按日期分索引,副本数=3 |
| 社交关系链查询 | TiDB(Cassandra底层) | 全局二级索引+LSM树存储 |
| 金融交易系统 | OceanBase(Paxos协议) | 强同步复制+读写分离 |
| 物联网设备数据 | TimescaleDB(时序数据库) | 设备ID哈希分表+时间范围分区 |
常见问题与解决方案
数据热点问题
- 现象:某个分片访问量远超其他节点
- 解决:
- 动态分片:按访问频率实时调整分片策略
- 缓存层:Redis缓存热点数据,降低DB压力
- 多级分区:先按业务类型分库,再按哈希分表
扩容与数据迁移
在线扩容步骤:
- 新增节点并同步历史数据
- 修改分片规则(如从4节点扩到5节点)
- 双写校验:新旧路由同时写入,比对数据一致性
- 流量切换:逐步将读请求切到新节点
工具支持:
- Sharding-Sphere提供可视化扩缩容向导
- 阿里云PolarDB-X支持一键扩容,自动均衡
性能优化建议
查询优化
- 避免跨库JOIN:预先在业务层完成数据聚合
- 建立分片局部索引:每个分片独立创建B+Tree索引
- 使用全局表:高频查询的字典表全局广播存储
写入优化
- 批量写入:积攒多个写请求后合并执行
- 异步化处理:主线程快速返回,后台执行实际写入
- 负载均衡:采用一致性哈希算法分配写入压力
监控体系
| 监控指标 | 阈值告警 | 优化措施 |
|——————-|————————-|———————————–|
| 分片QPS差异 | >3倍标准差 | 动态调整分片策略 |
| 跨库事务耗时 | >500ms | 改用本地事务+异步补偿 |
| 索引碎片率 | >20% | OPTIMIZE TABLE重建索引 |
FAQs
Q1:分库分表后如何实现全局排序?
A1:可采用以下方案:
- 业务层排序:各分片独立查询后,应用程序内存中合并排序
- 分布式排序:利用MapReduce框架(如Hadoop/Spark)进行多节点排序
- 预计算排名:维护冗余字段存储全局排名,定期刷新(如游戏排行榜)
- 特殊编码:订单号包含时间戳+自增序列,天然具备全局有序属性
Q2:如何应对分片键选择错误导致的性能问题?
A2:需进行以下优化:
- 重新分片:通过数据迁移工具(如ShardingSphere-Scaling)更换分片键
- 复合分片:增加次要分片键,如
(user_id, order_date)组合分片 - 冷热分离:对历史数据归档到冷库,新数据按优化后策略存储
- 查询优化:添加全局二级索引,通过代理层自动路由查询