上一篇
hive创新数据库
Hive是基于Hadoop的大数据平台,支持SQL查询,专注批量数据处理,具备高扩展性,广泛用于数据
Hive创新数据库:重构大数据存储与计算的新范式
Hive作为Apache基金会孵化的开源数据仓库工具,自诞生以来便以“SQL on Hadoop”的核心理念革新了大数据处理方式,其创新性不仅体现在对传统数据库的替代能力,更在于通过独特的架构设计、灵活的扩展机制以及与Hadoop生态的深度整合,解决了海量数据场景下的存储、计算与管理难题,以下从技术特性、架构创新、应用场景及行业影响四个维度展开分析。
核心创新点解析
| 创新维度 | 具体实现 | 价值体现 |
|---|---|---|
| 存储与计算分离 | 基于Hadoop HDFS存储数据,通过MapReduce或Tez引擎执行计算任务 | 解耦存储与计算资源,支持PB级数据水平扩展,降低硬件成本 |
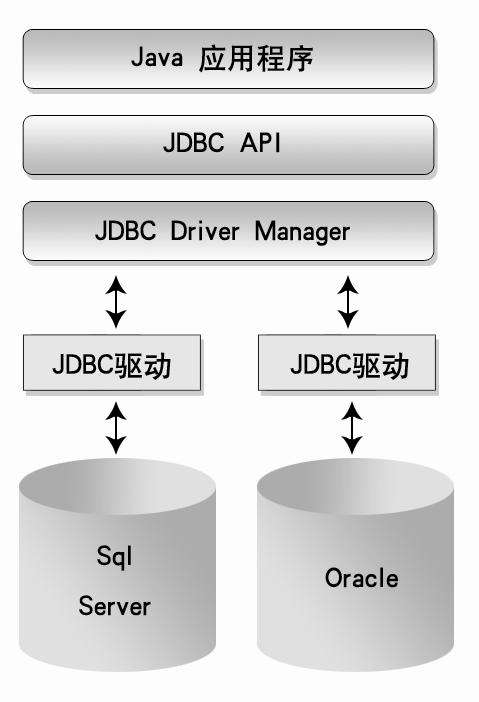
| SQL兼容性 | 提供类SQL语法(Hive QL),支持JDBC/ODBC连接 | 降低大数据技术门槛,允许传统数据分析师无需学习编程即可处理海量数据 |
| 元数据管理 | 采用关系型数据库(如MySQL)存储表结构、分区信息等元数据 | 实现数据逻辑与物理隔离,支持复杂分区策略(范围、哈希、列表分区) |
| 动态扩展能力 | 通过SerDe(序列化/反序列化)接口支持自定义数据格式(JSON、Avro、ORC等) | 适配多源异构数据,满足流批一体、实时与离线混合分析需求 |
| ACID事务支持 | 通过事务表(Transactional Table)实现原子性、一致性保障 | 支持可靠数据更新与删除,为数据湖场景提供事务级管理能力 |
架构设计亮点
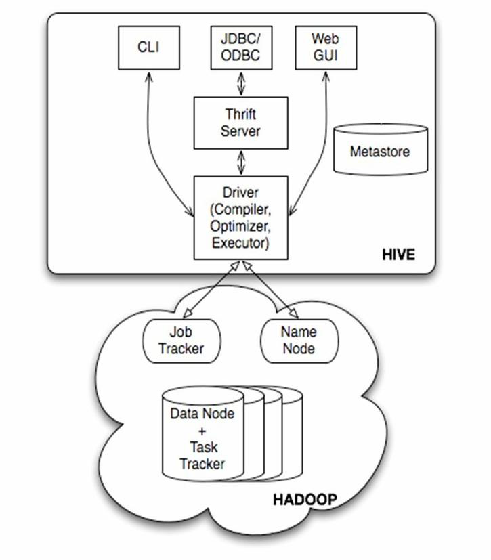
Hive的架构创新主要体现在以下三层:
客户端层

- 提供CLI、JDBC/ODBC、Thrift API等多种接入方式,支持BI工具(如Tableau)、ETL工具(如Oozie)直接对接。
- 通过
.hive-site.xml配置文件灵活调整参数(如并行度、内存分配)。
元数据管理层
- 使用内嵌的Derby数据库(生产环境建议外部MySQL/PostgreSQL)存储表结构、权限、Job历史等信息。
- 元数据缓存机制(如HiveServer2的MetaStore服务)提升高频查询性能。
执行引擎层
- 编译阶段:将HiveQL转换为抽象语法树(AST)→ 逻辑执行计划(Logical Plan)→ 物理执行计划(MapReduce/Tez/Spark作业)。
- 优化阶段:基于代价模型(CBO)选择最优执行路径,支持列式存储裁剪(如ORC文件跳过无关列)。
- 执行阶段:通过YARN动态分配资源,支持容器化部署(如Kubernetes集群)。
典型应用场景
| 场景类型 | 业务需求 | Hive解决方案 |
|---|---|---|
| 数据湖构建 | 整合多源异构数据(日志、传感器、业务库) | 通过外部表(External Table)映射数据源,支持Parquet/ORC高效存储格式 |
| 离线分析 | 用户行为分析、报表生成 | 利用窗口函数、UDF实现复杂事件处理,结合调度系统(Airflow)定时运行 |
| 归档与合规 | 长期存储冷数据(如交易记录) | 使用分区表按时间周期存储,结合Snappy压缩减少存储成本 |
| ETL管道 | 清洗、转换、加载原始数据 | 结合Apache NiFi或Logstash预处理数据,Hive作为最终存储与计算节点 |
对比传统数据库的优势
| 对比项 | 传统数据库(如MySQL/Oracle) | Hive创新数据库 |
|---|---|---|
| 数据规模 | 垂直扩展,受限于单机硬件上限(TB级) | 水平扩展,支持EB级数据存储与计算 |
| 成本模型 | 高昂的专有硬件与许可证费用 | 基于廉价PC服务器集群,开源免费 |
| 灵活性 | 固定Schema,修改需停机维护 | 动态Schema支持(如JSON SerDe),支持Schema演进 |
| 计算模式 | 行式存储,全量扫描效率低 | 列式存储(ORC/Parquet)+ 投影裁剪,提升查询性能 |
| 生态整合 | 孤立部署,缺乏与大数据工具联动 | 天然兼容Hadoop生态(HDFS、Spark、Flink) |
行业实践与挑战
成功案例:
- 电商领域:某头部电商平台使用Hive存储用户行为日志,每日处理百亿级事件,支撑实时推荐与离线画像计算。
- 金融行业:某银行利用Hive构建风险数据集市,通过时间旅行(Time Travel)功能回溯数据状态,满足审计需求。
现存挑战:
- 实时性不足:默认基于MapReduce的查询延迟较高(分钟级),需结合Impala或Spark加速。
- 元数据瓶颈:单点MetaStore在高并发场景下可能成为性能短板,需通过HA部署或分片解决。
- 资源竞争:共享Hadoop集群时,复杂查询可能抢占YARN资源,需配置Cgroups或队列隔离。
FAQs
Q1:Hive是否支持实时数据处理?
A1:Hive原生设计以批处理为主,但可通过以下方式增强实时性:
- 集成Apache Kafka作为流数据源,结合Hive Streaming(基于Kafka的近实时处理)。
- 使用Spark SQL替代Hive内置引擎,实现亚秒级查询响应。
- 对延迟敏感的场景,建议将Hive与Impala配合使用(Impala负责实时,Hive负责深度分析)。
Q2:如何优化Hive查询性能?
A2:可采取以下优化策略:
- 数据存储优化:
- 使用ORC/Parquet格式替代Text/SequenceFile,开启Snappy压缩。
- 按查询常用字段建立Bloom过滤器,减少IO扫描量。
- 查询语句优化:
- 避免全表扫描,利用分区剪裁(Partition Pruning)和分桶(Bucketing)。
- 合理设置并行度(
set mapreduce.job.reduces=)。
- 资源配置优化:
- 调整YARN容器内存(
yarn.nodemanager.resource.memory-mb)。 - 启用CBO优化器(
set hive.cbo.enable=true)。
- 调整YARN容器内存(