上一篇
分布式数据仓库的书籍
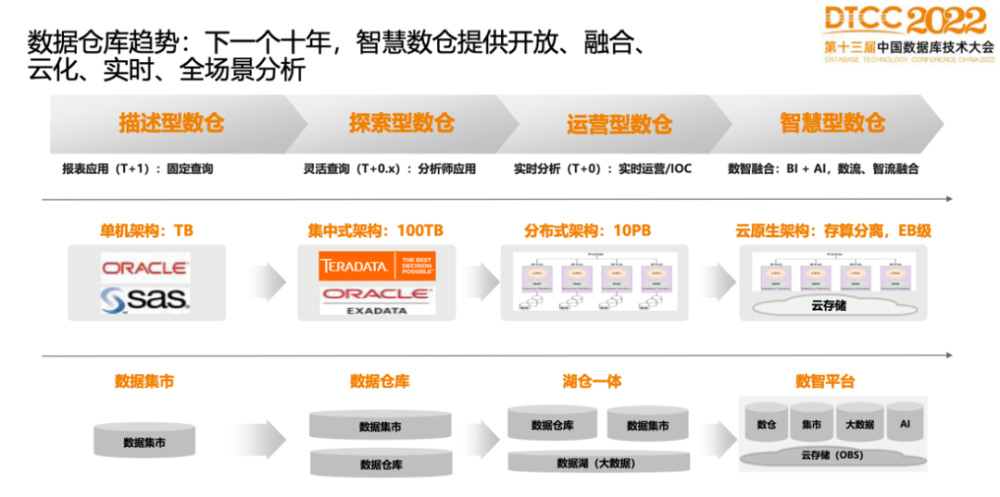
分布式数据仓库领域经典如《 数据仓库工具箱》与《分布式系统原理》,
分布式数据仓库领域核心书籍推荐
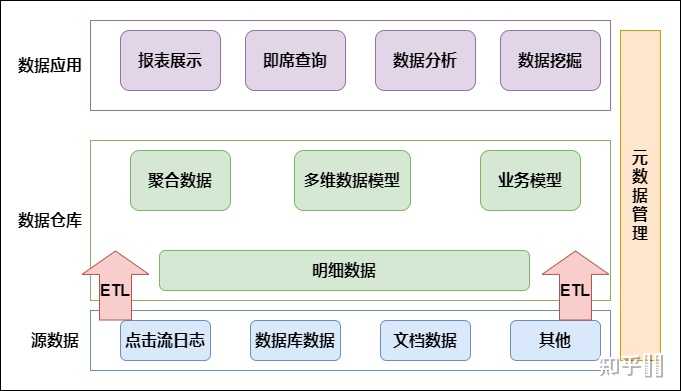
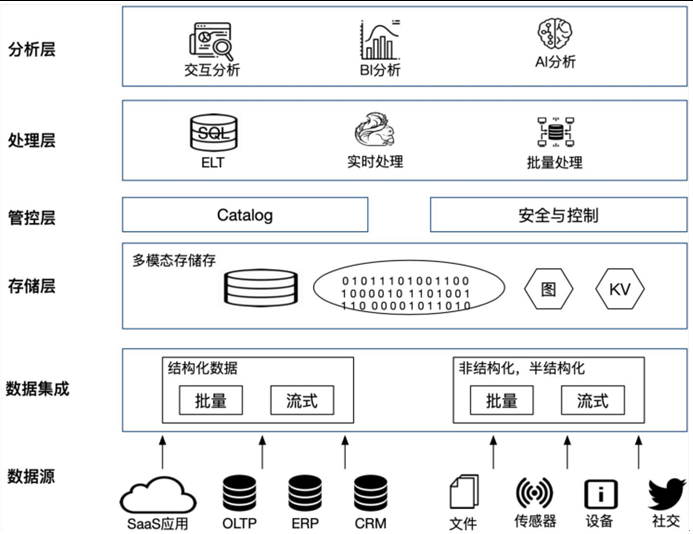
分布式数据仓库作为大数据基础设施的核心组件,涉及分布式存储、计算引擎、数据治理等复杂技术体系,以下精选书籍从架构设计、实践案例到理论原理提供全方位知识图谱:
| 书名 | 作者 | 出版年份 | 核心特点 | 适用阶段 |
|---|---|---|---|---|
| 《分布式数据仓库架构与实践》 | 李广宇等 | 2021 | 国内首部聚焦分布式数仓落地 | 初中级实践者 |
| 《Data Warehousing in the Cloud》 | Chris Adamson | 2020 | 云原生数仓设计权威指南 | 中高级架构师 |
| 《Hive大数据导论》 | 张孝祥等 | 2019 | 基于Apache Hive的实战解析 | 初级入门者 |
| 《The Data Warehouse Toolkit》 | Thomas Kimball | 2018 | 数据仓库建模经典(含分布式扩展) | 理论奠基阶段 |
| 《Designing Data-Intensive Applications》 | Martin Kleppmann | 2017 | 分布式系统原理(含数仓场景) | 高阶拓展阅读 |
《分布式数据仓库架构与实践》
该书由阿里云资深专家撰写,系统讲解:
- 分布式存储引擎(Delta Lake/Iceberg)实现原理
- 多活数据中心部署方案
- 实时数仓与离线数仓融合架构
- PB级数据治理策略
- 典型故障场景应急处理
特别适合互联网企业数据团队作为技术手册,书中包含大量生产环境配置参数和性能调优案例。
《Data Warehousing in the Cloud》
亚马逊云科技首席数据架构师著作,重点涵盖:
- Serverless架构下的数仓设计
- 跨云厂商的数据湖集成
- 机器学习驱动的自动优化
- 成本控制与资源弹性策略
- 合规性审计实现方法
通过对比Snowflake、Redshift、BigQuery等主流云数仓,揭示分布式架构设计共性与差异。
《Hive大数据导论》
针对Apache Hive生态的深度解析:

- UDF开发与优化技巧
- 动态分区策略设计
- 小文件合并算法实现
- Tez/Spark执行引擎对比
- 调优实战(JOIN优化/倾斜处理)
适合Hadoop生态维护人员,包含大量CLI命令与SQL优化实例。
进阶阅读方向
分布式系统理论强化
- 《Distributed Systems: Principles and Paradigms》 → 理解CAP定理、Paxos协议等底层原理
- 《Data-Intensive Text Processing》 → 掌握MapReduce编程模型本质
- 《Designing Data-Intensive Applications》 → 学习分布式系统设计方法论
云原生数仓前沿
- 《Cloud Native Data Warehousing》 → 详解Kubernetes部署数仓实践
- 《Streaming Architecture Patterns》 → Flink/Kafka与数仓的实时集成
- 《Serverless Architecture》 → 事件驱动型数仓设计
数据治理专项
- 《Data Governance in the Digital Economy》 → 元数据管理标准
- 《Practical Data Quality Solutions》 → 数据质量监控体系搭建
- 《Metadata Management》 → 企业级数据目录建设
经典案例解析书籍
| 案例来源 | 推荐书籍 | 学习价值 |
|---|---|---|
| 电商数仓 | 《阿里巴巴数据中台实践》 | 双11大促流量应对方案 |
| 金融数仓 | 《金融数据仓库与数据挖掘》 | 实时风控数据架构 |
| 物联网 | 《IoT Data Management》 | 时序数据处理策略 |
| 广告系统 | 《Real-Time Analytics》 | 千亿级特征工程实践 |
学习路径规划建议
基础阶段(1-3个月)
- 《Hive大数据导论》+《SQL Performance Explained》
- 搭建本地Hadoop集群实践ETL流程
- 完成Kaggle基础数据集分析项目
进阶阶段(3-6个月)
- 《分布式数据仓库架构与实践》+《Data Warehousing in the Cloud》
- 在AWS/Azure搭建实验环境
- 参与开源项目(如Apache Doris)贡献
专家阶段(6-12个月)
- 《Designing Data-Intensive Applications》+《Cloud Native Data Warehousing》
- 研究Google/Facebook论文专利
- 主导企业级数仓重构项目
配套学习资源
在线课程
- Coursera《Data Warehousing for Big Data》
- Udacity《Cloud Data Engineering》
- 阿里云大学《实时计算与数仓整合》
工具手册
- 《Hive Reference Manual》→ 官方文档精要
- 《Spark SQL Programming Guide》→ 性能调优checklist
- 《Presto Query Tuning》→ 交互式分析优化
社区资源
- Stack Overflow → 搜索”distributed data warehouse”标签
- GitHub → 关注apache/incubator-calcite等项目
- Reddit → r/bigdata每周技术讨论
FAQs
Q1:传统数据仓库工程师如何向分布式架构转型?
A:建议分三步走:
- 补充分布式系统基础:学习《Designing Data-Intensive Applications》,掌握CAP定理、一致性协议等核心概念
- 实践云平台操作:在AWS/Azure完成EMR集群搭建,熟悉Serverless服务(如Athena)
- 重构思维模式:通过《Data Warehousing in the Cloud》理解无共享架构设计,重点关注数据湖与数仓的融合技术
Q2:中小型企业是否需要构建分布式数据仓库?
A:需根据业务规模判断:
- 日增数据量<1TB:可先用单机版ClickHouse+定期备份方案
- 日增1-10TB:采用Greenplum等MPP数据库+冷热数据分层
- 日增>10TB:必须考虑Spark+Hive+Iceberg组合,配合对象存储(如MinIO)
关键判断标准:单表查询是否出现分钟级延迟、ETL任务是否频繁失败、存储成本占比是否超过30%