上一篇
分布式服务器操作系统要怎么更新
分布式服务器系统更新需分阶段实施:1.备份全量数据并建立回滚预案;2.在测试环境验证新版本兼容性;3.采用滚动更新逐节点部署,通过负载均衡保障服务连续;4.实时监控各节点状态,异常时立即熔断;5.更新后执行全链路压测,确认系统稳定性,最终同步配置文件完成全集群升级
分布式服务器操作系统更新方案详解
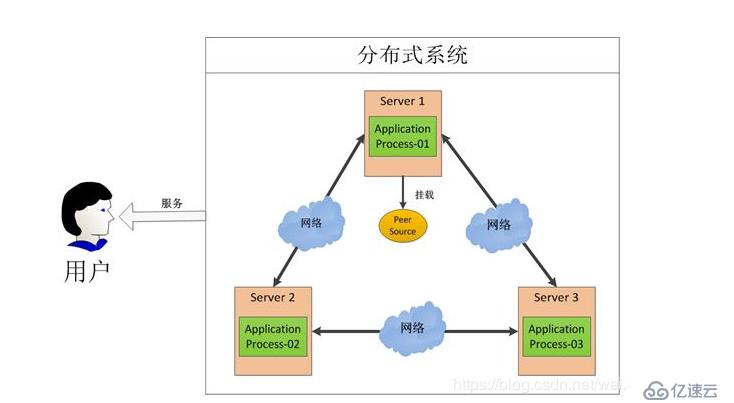
分布式服务器操作系统的更新是一项复杂且高风险的运维任务,涉及多节点协调、服务连续性保障、数据一致性维护等多个维度,以下是一套完整的更新流程与技术方案,涵盖从准备到执行再到验证的全周期操作。
更新前的核心准备工作
| 步骤 | 技术要点 | |
|---|---|---|
| 环境评估 | 检查硬件兼容性(CPU、内存、存储) 分析软件依赖(中间件、数据库、应用) 验证新版本OS的内核改动对现有服务的影响 | 使用工具:lscpu、dmesg、ldd兼容性测试:通过容器模拟新版本环境运行核心服务 |
| 数据备份 | 全量备份关键数据(数据库、配置文件) 创建快照(如ZFS、LVM) 备份元数据(如Kerberos密钥、LDAP配置) | 工具:rsync+ssh远程备份云环境:利用云厂商快照服务(如AWS EBS) |
| 灰度测试 | 搭建测试集群(建议≥3节点) 模拟生产负载进行压力测试 验证驱动兼容性(网卡、RAID卡) | 测试工具:sysbench、fio、stress-ng监控指标:CPU利用率、网络延迟、磁盘IOPS |
分布式更新策略对比
| 策略类型 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 滚动更新(Rolling Update) | 大规模集群、业务7×24小时在线 | 无需停机 逐步验证 | 更新时间长 需处理中途失败 |
| 分批更新(Canary Release) | 混合云环境、多数据中心 | 降低全局风险 可快速回滚 | 批次划分需精准 |
| 蓝绿部署(Blue-Green Deployment) | 微服务架构、高频更新场景 | 零停机切换 版本快速回退 | 资源占用翻倍 数据同步复杂 |
| 容器化热升级 | Kubernetes集群、Docker环境 | 秒级重启 无状态服务友好 | 依赖容器编排能力 状态ful服务需额外处理 |
推荐组合方案:
- 第一阶段:采用滚动更新完成5%-10%节点升级,重点观察监控告警
- 第二阶段:剩余节点分3-5个批次更新,每批间隔≥30分钟
- 最终校验:通过etcd/Consul等配置中心确认所有节点版本一致
关键技术实现细节
配置管理

- 使用Ansible/Puppet统一管理配置文件(/etc/fstab、network scripts)
- 版本化管理:将OS镜像打包为RPM/DEB包,通过SaltStack分发
- 示例命令:
ansible-playbook -i hosts.ini update_os.yml --limit "groupA" # 指定分组更新
自动化工具链
| 工具 | 功能 | 使用场景 |
|——|——|———-|
| Terraform+Packer | 基础设施即代码+镜像构建 | 云环境批量更新 |
| Jenkins+Argo CD | CI/CD流水线+声明式部署 | DevOps体系集成 |
| Falco+Prometheus | 运行时安全监控+指标采集 | 异常行为检测 |高可用保障机制
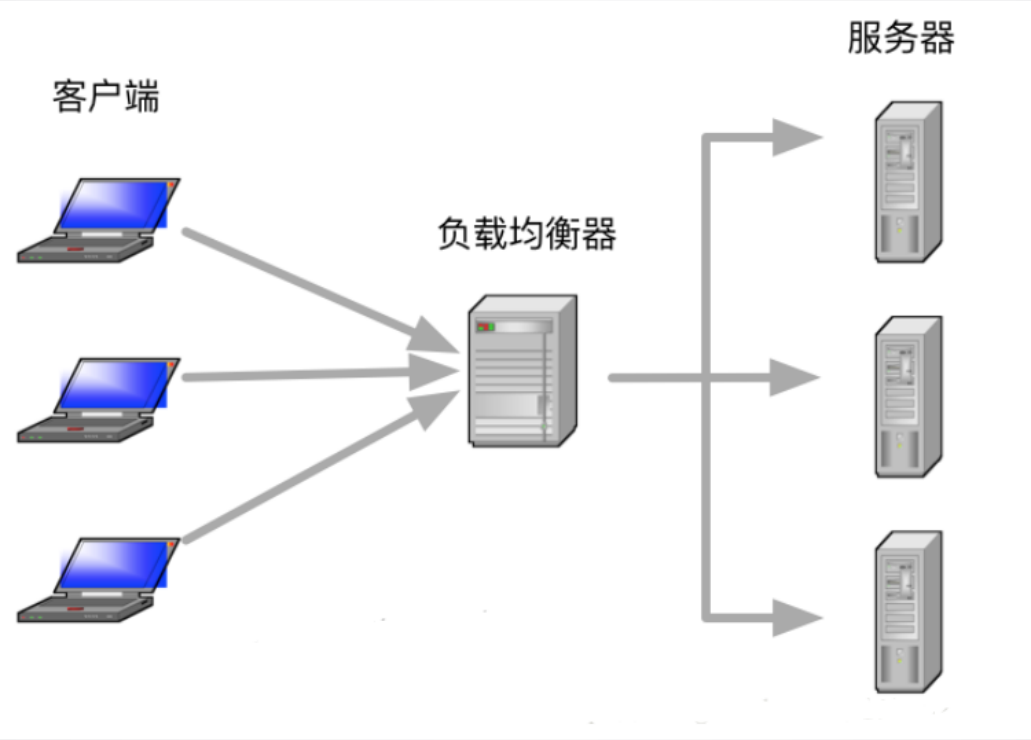
- 负载均衡切换:Nginx/HAProxy健康检查配置(示例):
upstream backend { server 192.168.1.1 max_fails=3; server 192.168.1.2 backup; # 备用节点 } - 数据同步:DRBD(分布式复制块设备)或Ceph CRUSH Map动态调整
- 服务熔断:Istio配置超时阈值(示例):
http: retries: attempts: 3 perTryTimeout: 2s
- 负载均衡切换:Nginx/HAProxy健康检查配置(示例):
典型故障处理预案
| 故障类型 | 处理方案 | 工具支持 |
|---|---|---|
| 驱动不兼容 | 紧急回滚至旧版内核 手动编译定制驱动 | dkms模块管理modprobe热插拔 |
| 网络分区 | 启用VRRP冗余网关 检查MTU/VLAN配置 | ip link实时监控traceroute路径追踪 |
| 时间同步异常 | 强制同步NTP(ntpd -q)修复chronyd配置 | ntpstat状态检查timedatectl校正 |
| 存储卷失效 | LVM激活(lvchange -ay)XFS文件系统修复( xfs_repair) | dmsetup查询映射状态 |
更新后验证清单
基础层验证
uname -a确认内核版本df -h检查存储挂载状态systemctl list-units查看服务启动情况
业务层验证
- API响应时间(≤200ms基准)
- 数据库连接池命中率(≥95%)
- 日志完整性(ELK/EFK栈检索)
安全合规检查
- OpenSSH版本(建议≥8.2p1)
- SELinux/AppArmor策略生效状态
- SSH登录告警(fail2ban规则触发测试)
FAQs
Q1:如何判断分布式更新是否完全成功?
- 验证标准:
- 所有节点
uptime连续运行时间>预期维护窗口 - Zabbix/Prometheus中无红色告警持续5分钟以上
- 业务吞吐量恢复至基线水平的±5%波动范围内
- 所有节点
- 工具命令:
for node in $(cat /etc/cluster_nodes); do ssh $node "dmesg | grep -i error"; done
Q2:更新过程中部分节点失联如何处理?
- 应急流程:
- 立即标记故障节点(如Consul标记为
critical状态) - 触发自动扩缩容(ASG)补充临时节点维持副本数
- 离线节点恢复后执行差异同步(rsync + checksum校验)
- 立即标记故障节点(如Consul标记为
- 预防措施:
- 提前配置Keepalived VIP漂移策略
- 设置节点健康检查超时阈值(建议30秒内未响应则摘除)